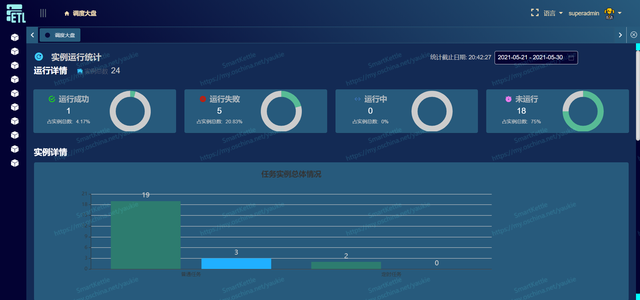
1. 简介
1. 简介每款SQL数据库引擎的工作方式基本一致:首先将输入的SQL文本转化为"预处理语句",然后"执行"预处理语句以产生结果。
预处理语句是一个对象,代表实现输入SQL所必需的步骤,或者说,预处理语句将SQL语句转化为计算机更容易理解的形式。
在SQLite中,预处理语句是sqlite3_stmt对象的实例。在其他系统中,预处理语句通常是一种内部数据结构,对应用程序员不直接可见。其他SQL数据库引擎的开发者可能不把这些对象称作"预处理语句",但无论名字如何,这些对象都存在。本文也将用"预处理语句"这个术语。
实现预处理语句的方法有无数种。本文将探讨两种最常见的方法:
字节码 -> 将输入的SQL语句转化为虚拟机语言,然后通过虚拟机解释器来执行。这就是SQLite使用的技术。
对象树 -> 将输入的SQL语句转化为代表需要满足的处理的对象树。通过遍历该对象树来执行SQL语句。这就是MySQL和PostgreSQL采用的技术。
这两种预处理语句的表示方法各有优劣。本文的目的在于明确和阐述这些优劣。
1.1. 如何提供反馈此文档从SQLite的原作者的视角编写。如果您对本文中提出的任何观点有所异议,欢迎在SQLite论坛提出更正或提供不同的观点。或者您可以直接向作者发送电子邮件。
1.2. "字节码"的定义SQLite生成的字节码可能与许多读者对字节码的认知有所不同。例如,Java虚拟机或WebAssembly使用的字节码主要由低级操作构成,这与物理CPU实现的方式相似:基础的数学操作符、比较、条件跳转,以及将内容移动至不同内存位置的指令。SQLite的字节码也包括这种类型的低级指令。但是,SQLite的字节码还包含一些针对数据库引擎需求的高级操作。以下是一些例子:
OP_Column → 从特定光标当前指向的数据库行的第N列提取值。
OP_CreateBtree → 在数据库文件中为新的B-Tree分配空间。
OP_ParseSchema → 重新读取和解析sqlite_schema表的全部或部分,然后相应地刷新内部符号表。
OP_SeekGE → 将在特定B-Tree上的光标移动至大于或等于给定键的第一个条目。
OP_Next → 将在特定B-Tree上的光标推进至B-Tree中的下一个条目,并跳转,如果在该B-Tree中没有更多的条目则到达结束点。
换句话说,SQLite所使用的"字节码"与其称之为一组CPU指令,不如说是一系列需要按特定次序运行的数据库原子操作集合。
1.3. "抽象语法树"或"AST"的定义"抽象语法树"或"AST"是一种数据结构,描述了以某种形式的语言编写的程序或语句。对我们来说,这种形式的语言是SQL。通常AST被实现为一个对象树,每个对象代表了整体SQL语句的一小部分。AST自然地从形式语言的解析器中产生。常见的技术是使用LALR(1)解析器。在这种解析器中,每个终结符都保存将变成AST叶节点的元数据,每个非终结符都保存将变成总体AST子分支的元数据。当语法规则被解析器"还原"时,AST的新节点被分配并连接到子节点身上。解析结束后,语法的开始符号保存了AST的根。
一个AST是一个对象树。但是一个AST不适合作为预处理语句的形式。生成后,AST在能够执行前首先需要通过多种方式进行转换。需要解析符号、检查语义规则、应用优化以将输入的SQL语句转变成更快执行的形式。最后,AST需要被转化成对执行更友好的另一种表示形式。
有些人将MySQL和PostgreSQL等数据库引擎使用作为预处理语句的对象树称作AST。这可能是"AST"这个术语的误用,因为当对象树准备好可执行时,它已经经过了很多变化,使其与原始的SQL文本大为不同。这种混乱部分源于两者都是以对象树的形式存在。通常,直接从解析器中生成的原始AST会在多次转换中逐渐变化,最终完全转化为不再严格意义上的AST,但是可以计算生成结果的对象树。在此过程中,对象树何时不再作为AST,何时开始作为预处理语句存在并没有明确的界定点。并且因为AST和预处理语句之间没有清晰的界线,人们会将表示为对象树的预处理语句称作"AST",即便这种描述并不精确。
1.4. 数据流编程数据流编程是一种编程风格,在该风格中每个节点专门用于完成整体计算的一小部分。每个节点从其他节点接收输入,并向其他节点发送它的输出。于是,这些节点形成一个有向图,将输入输送为输出。
"数据流程序"也许比"AST"更能准确描述SQL数据库引擎用作预处理语句的对象树。
2. 编译成字节码的优势
SQLite编译成字节码,SQLite的开发者对此方式非常满意。以下是为什么:
2.1. 字节码更易理解你可以轻松打印出一个平面的指令列表,以清楚地看到SQL语句是怎样实现的。当你在SQLite中用"EXPLAIN"关键词前缀一个SQL语句时就发生了这种情况:实际上没有运行SQL语句,结果是一个展示了实现该SQL语句的字节码列表。
字节码将其自身作为表格来显示,因为一个字节码程序容易被表示为表格。在SQLite的字节码中,每条指令有一个操作码和五个操作数。因此,预处理语句的结果可以呈现为一个六列的表格的查询。
将对象树的表现形式变成可供人们阅读的形式更为困难。构成树的对象各不相同,因而在想出一种一致而简洁的表格形式来显示这些对象方面变得困难。你能够想出的任何此类表格形式几乎可以肯定要包含超过六列,可能会多很多。将对象树以表格显示的问题足够困难,以至于据我所知没有人真正做到这一点。因此,没有哪个以对象树为基础的数据库引擎能向SQLite那样在其"EXPLAIN"输出中给出如此详尽的信息。
2.2. 字节码更易于调试字节码清晰地区分了解析和分析与执行SQL语句两部分—— 在出现问题(例如错误的结果或性能较差)时,开发者可以通过检查字节码来快速确定问题的来源是前端的分析部分还是后端的数据存储部分。
在SQLite的调试构建中,PRAGMA vdbe_trace=ON;命令会让字节码执行的跟踪结果出现在控制台上。
2.3. 字节码可以分步执行用字节码编写的SQL语句可以分步执行。例如,可以执行语句直至它只生成第一行输出。然后语句暂停,直到再次被调用时才会继续执行。在查看第一行输出之前并不需要运行完整个语句。
这在面向对象设计中更难实现。当预处理语句是一个对象树时,通常通过遍历树来执行。为了在计算过程中暂停语句,意味着需要退栈回到调用者,同时保留足够的状态来便于在前一次离开的地方进行恢复执行。这并非不可能做到,但难度足够大以至于我从未看到有人真正做到这一点。
大多数SQL数据库引擎真的不需要分步执行预处理语句,因为大多数SQL数据库引擎都是使用客户端/服务器架构。在客户端/服务器引擎中,一个完整的SQL语句被发送到服务器执行,然后将完整的回应通过网络一次发送回来。因此每个语句都将在一次运行中完成。但SQLite并不是客户端/服务器模型。SQLite是一个库,使用和应用同一地址空间和栈运行。对于SQLite来说,能够轻松可靠地执行SQL语句的分步运行是非常重要的。
2.4. 字节码更小SQLite生成的字节码通常比从解析器中产生的对应AST小。在初次处理SQL文本时(在调用sqlite3_prepare()和相似的过程中)两种——AST和字节码——都同时存在于内存中,所以使用的内存较多。但这只是暂时的情况。迅速地,AST被丢弃并回收了其内存,即使在sqlite3_prepare()返回之前。因此,最后的预处理语句作为字节码表示时,其用的内存较为AST时小。这点很重要,因为sqlite3_prepare()的元素是暂时的,但预处理语句常常被缓存以备可能的重复使用,并在内存中持久存在相当长时间。
2.5. 字节码执行更快我相信将预处理语句表示为字节码运行起来会更快,因为每次计算只需要做更少的决策。请注意“我相信”——这个主张验证起来很困难,因为没有人愿意用上数年的时间去生成等效的字节码和对象树预处理语句的表示来看哪个实际上更快。我们知道SQLite是非常快的,但我们并没有和其他SQL数据库的好的横向对比,因为其他数据库花费大量时间做客户端/服务器的消息处理,从而在实际处理时间中去除消息往返的开销非常困难。
3. 编译成对象树的优点SQLite开发人员认为字节码方法是最好的,至少对于SQLite试图解决的需求来说是这样,但是对象树方法处理SQL也比字节码有一些优点。总是有需要权衡的地方。
3.1. 查询规划决策可以推迟到运行时当预处理语句是字节码时,一旦生成了字节码,算法就被固定下来,不能在后期更改,除非完全重写字节码。这在采用对象树的预处理语句中并非如此。对象树更容易进行即时修改。查询计划是可变的,并可以在运行中根据查询的进度调整。因此一个查询可以动态自我调优。
3.2. 数据流程序易于并行化在数据流程序中,每个处理节点可以分配给一个不同的线程。需要一种线程安全的队列机制将中间结果从一个节点传输到下一个。但每个程序的节点通常不需要同步原语。节点的调度很简单:当节点有可用数据且其输出队列里有空间时,节点才运行。
这是一个很重要的考虑因素,对于那些被设计在大型多核服务器上运行大型分析查询(OLAP)的数据库引擎来说。SQLite的主要关注点是在物联网上进行事务处理(OLTP),所以在SQLite中,将预处理语句表示为数据流程序的需求较小。