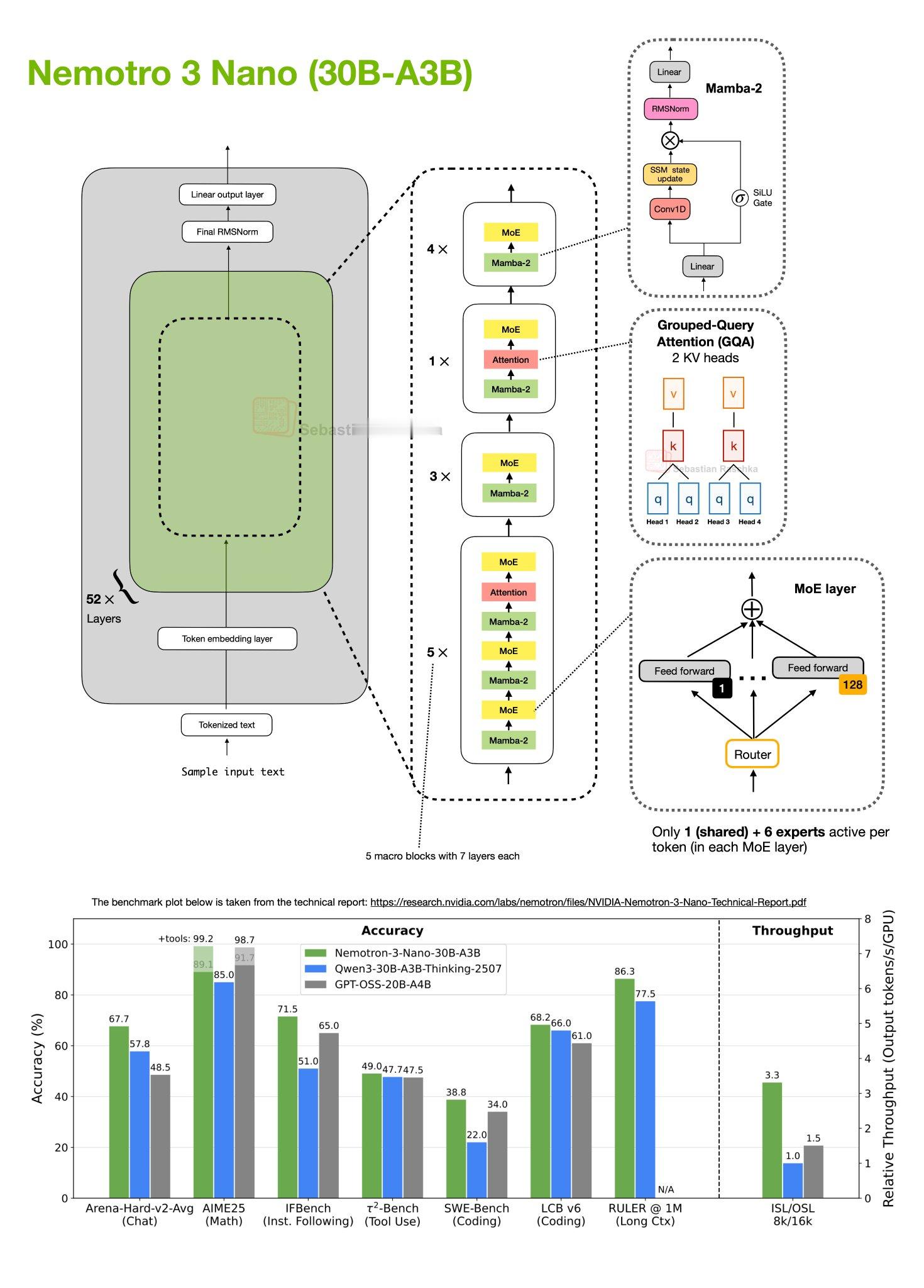
NVIDIA 刚开源了三款大模型,其中包括一个参数500B的大模型,这是要扛起西方开源模型的旗帜吗。翻译下Sebastian Raschka对其的介绍。-----------------我真没想到在今年 12 月还能看到又一个重磅开源权重 LLM(大语言模型)的发布,但它确实来了:NVIDIA 本周发布了全新的 Nemotron 3 系列。该系列包含三种规格:Nano (30B-A3B)\Super (100B)\Ultra (500B)架构方面,这些模型采用了 混合专家模型 (MoE) 与 Mamba-Transformer 混合架构。截至今天(12 月 19 日)上午,只有 Nano 模型开放了权重,因此本文将重点讨论该模型(见下方原理图)。Nemotron 3 Nano (30B-A3B) 是一个 52 层的 Mamba-Transformer 混合模型。它将 Mamba-2 序列建模块与稀疏混合专家 (MoE) 前馈层交错排列,并且仅在极少数层中使用自注意力(Self-Attention)机制。图1 包含的信息量很大,简而言之,该架构被组织为 13 个宏模块(macro blocks),内部由重复的 “Mamba-2 → MoE” 子块组成,外加少量的 分组查询注意力 (GQA) 层。总计(宏模块乘以子块数)共有 52 层。关于 MoE 模块,每个 MoE 层包含 128 个专家,但每个 Token 仅激活 1 个共享专家和 6 个路由专家。Mamba-2 层 本身就需要一整篇文章来解释(或许以后再谈)。但就目前而言,从概念上你可以将其类比为 Qwen3-Next 和 Kimi-Linear 使用的 Gated DeltaNet 方法,这些我在之前的《超越标准 LLM》文章中介绍过。Gated DeltaNet 与 Mamba-2 层的相似之处在于:它们都用门控状态空间更新(Gated-state-space update)取代了标准的注意力机制。这种状态空间风格模块的核心思想是维持一个运行中的隐藏状态,并通过学习到的门控机制混合新输入。与注意力机制相比,它的计算量随输入序列长度线性增长,而非平方级增长。这一架构最令人兴奋的地方在于:与同等规模的纯 Transformer 架构(如 Qwen3-30B-A3B-Thinking-2507 和 GPT-OSS-20B-A4B)相比,它在保持极高吞吐量(每秒生成的 Token 数)的同时,还展现出了非常优秀的性能。总的来说,这是一个非常有趣的研究方向,它在仅使用极少量注意力层这一点上,比 Qwen3-Next 和 Kimi-Linear 走得更远。然而,Transformer 架构的一大优势在于其在(极)大规模下的性能表现。我非常好奇更大规模的 Nemotron 3 Super,尤其是 Ultra,在与 DeepSeek V3.2 等模型的对标中表现如何。科技先锋官