导读 本文将介绍为什么要在机器学习中加入因果关系,以及基于因果的机器学习在银行业中的应用。
主要包括以下四部分:
1. 因果关系的必要性
2. 因果科学与机器学习
3. 银行业应用探索
4. 总结
分享嘉宾|李琨博士 光大科技有限公司 追光实验室负责人
编辑整理|周旻萱
内容校对|李瑶
出品社区|DataFun
01
因果关系的必要性
首先来探讨一下因果关系的必要性。
在过去的几十年里,特别是在深度学习发展之后,机器学习已经取得了很好的成果。传统的机器学习方法是在相关关系统计学的基础上发展起来的。这类方法非常依赖于数据。如果从统计学的角度来看,更多的是利用了数据之间的相关关系。机器学习任务就是利用一些算法来抓住数据中的某些特征,并在一些特定的任务上取得理想的表现。通常,我们在实际应用中会先设定问题,然后在一个数据集上进行训练,训练得到一个模型后,将这个模型应用到新的数据集上,接下来做一些预测等工作。
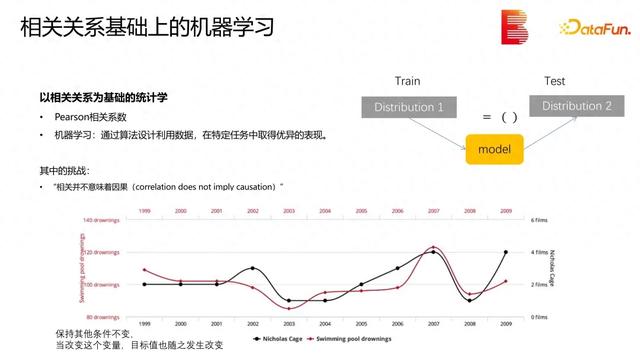
在上述过程中存在着一些问题。最直接的问题是用来训练的数据集和最后要用到的数据集之间可能存在模型关系不匹配的情况。如果模型只是在训练数据集上建立的,而不是在两个不同的数据集上建立起来,那就无法实现模型预测的目标。这通常会带来一些问题。基于相关关系的统计学经常受到的质疑是:相关并不总是意味着因果关系。关于这个问题有很多例子。
上图是一个有点老的例子,但它能很直接地说明问题。有两个变量,即尼古拉斯凯奇每年演的电影数量和美国每年淹死在游泳池里的人数,从统计学的角度来看,这两个量非常相关,但是这两个量之间并没有必然的关系。这种相关性可能只是偶然的、巧合性的。要做建模并预测一些事情或发现一些规律,我们更应该关注那些能够带来真实影响的因素。从哲学的角度来看,因果可能会变得比较复杂。但一般来说,最简单、最直观的想法是保持其他条件不变,改变其中一个变量,目标变量会随之变化,那么就认为改变的变量和目标变量之间的关系是可靠的。我们希望在各种各样的数据和场景中使用数据来发现量和量之间的关系。但这中间有很多挑战。

最直接的一个挑战就是统计学上的悖论,即在分析的场景还受到了其它因素的影响。如果没有同时考虑这种因素,就会对分析产生影响。这也是统计分析中经常出现的问题。比如在上图的例子中,分析了运动量和胆固醇指标之间的关系。如果我们从数据的角度直接分析运动量和胆固醇指标的关系,会发现运动量越多,胆固醇指数越高。但实际上出现这种情况的原因是我们没有考虑到年龄这个因素。年龄会同时影响运动量和胆固醇水平。如果我们控制了年龄变量的影响,比如只分析同一年龄段人们的运动量和胆固醇水平,那么得到的结论就会是运动量越多、胆固醇指标越低。这也是符合大家的一般理解的。但是如果我们只是简单地直接从数据角度来看待这个问题,忽略了年龄这一因素,就会出现问题。这也说明了我们在实际的数据中如果遗漏了一些变量,可能会导致很大的问题。
02
因果科学与机器学习
统计学家很早就发现了这样的问题,并针对各种假设提出了相应的解决办法。在过去一百年的时间里,随着数据的发展,因果科学和基于因果的机器学习都得到了相应的发展。

参考耿直老师团队在 2018 年发表的综述文章《因果推断的统计方法》,因果理论的发展主要有两个路径,一个是由统计学家建立的潜在因果模型。最早是由印度裔统计学家 J. Neyman 于 1923 年,针对试验性研究给出的因果作用的数学定义,即做了处置的产出减去没有做处置的产出得到的差异,就是处置对产出值的因果作用。因为无法对个体既处置又不处置,所以要看平均效应,这就产生了随机化试验设计,后面又衍生出了现在互联网常用的 AB test。进一步建模,还需要结合其它变量,就引出了条件平均处置作用和无混淆假设、条件独立性假设。统计学家和计量经济学家还提出了针对已有结果的观察性研究。
另一个路径是由计算机科学家开创的因果网络模型。Judea Pearl 提出了外部干预的概念,发展出形式化方法,建立了因果网络模型。这与统计学家提出的模型在满足一些条件的情况下是等价的。
基于这些定义和方法,可以进一步引入到机器学习领域中。

基于因果的机器学习也经过了相当一段时间的发展。基于因果图建模、消除混杂、中介分析、反事实推断思想等因果理论,来处理机器学习中的问题,包括可解释性问题、可迁移性问题、鲁棒性问题、公平性问题、反事实评估问题等等。
03
银行业应用探索
下面介绍银行业在基于因果的机器学习领域的探索和实践。

银行的传统业务主要是存贷汇,因果最直接的应用场景是营销。我们会筛选客户并对他们采取一些营销措施,以促进业务提升。具体的方法可能因行业而异,互联网行业在这方面做得比较好,利用因果关系进行推荐和客户运营。银行业也希望向互联网学习。银行的营销主要包括客户营销、渠道运营和产品推荐。比如,客户经理或营销机器人会推荐产品或服务给客户。在各个渠道,比如手机银行以及各种支付渠道,都有不同的营销手段。银行业中的产品推荐与电商不同,首先可推荐的产品比较少,另外会有比较强的业务逻辑在其中。
因果在银行业的另一大应用场景就是风控,包括模型稳定性方面的工作。
1. 营销方面的工作

首先来介绍营销场景的应用。传统的模式是从客户中筛选出购买产品或选择服务响应率较高的客户。建模的目标是提高客户对产品和服务的响应可能性。我们会建立一个模型预测客户的响应率,筛选预测响应率高的头部客户进行营销。这种模式的好处是目标明确,对于执行营销的人员来说也会有比较强的动力。然而,这种方法也受到了一些质疑,对预测响应率高的客户进行营销,最后响应的客户是否真的是因为我们的营销措施带来的效果并不确定。

在营销处置和不处置中,响应率差别最大的人群才是我们想要关注的客户人群,而不是单纯关注响应率最高的客户。这里最常用的做法就是增量提升(Uplift)建模。主要方法包括:
直接评估型方法:直接针对目标来建模,除了传统的响应率数据集之外,还需要有客户是否做了营销的特征,利用这样的数据集就可以去做评估。可以直接去评估 uplift 的量。用做营销情况下的预测响应率减去不做营销情况下的预测响应率,得到的差就是增量评估值,这就是 S-learner。还有更复杂的做法,对各种情况分别建模,建更多的模型,可以得到更准确的结果。目标变换型方法:做一些变换,利用变换后的结果去评估增量值。变换生成的变量的预测要与 uplift 的预测有关系,比如概率有倍数的关系,或者期望相同等等。这种方法的好处是仅建模一次。基于分裂指标的树模型方法:传统的树模型有一个分裂目标,现在结合增量评估的目标改造分裂准则,设计新的机器学习方法。如上图所示。
银行领域对于可解释性要求比较高,要求能够形成规则,最常见的方法比如使用决策树,要对于每条生成的规则评估是否适用。这是最基本的用机器学习来生成规则的方法,我们在此基础上进行了改造。用评价规则的定量指标去作为建树的分裂准则,这样就可以得到在评价规则上表现比较好的树。

现在我们也希望我们规则生成的方法结合因果效应 uplift model 的场景。对于我们原有框架的改动就是以增量为基础的规则评价标准做树分裂准则。因为增量评估是在样本上做评价,会受到样本量的影响,需要保证规则覆盖的样本数量。这样我们设计的规则抽取新方法,就可以用到 uplift 建模因果推断营销场景上。

利用上述方法,在合成数据集上的结果表明抽取规则确实使用了对分类结果有作用的变量。
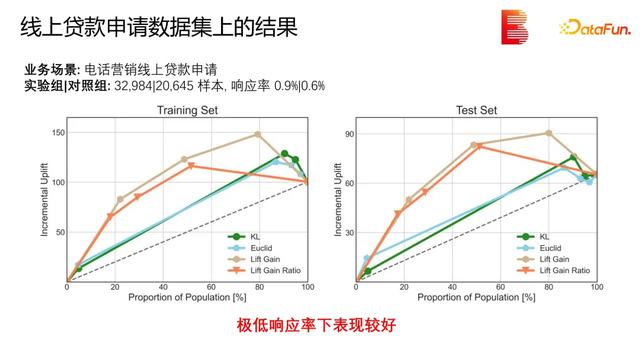
我们也把该方法应用到了线上贷款申请数据集上,实验表明,使用我们的方法后响应率的增量有一定的提升。
2. 风控方面的工作

现在金融机构特别是银行,普遍开展网络贷款业务,相应地有一系列的风控流程。除了各种规则控制外,贷前审批依赖于评分模型,根据评分结果决定给客户批准的额度及定价。

评分模型主要用来评估客户的信用。最早是美国的 FICO 评分。在我国,随着征信工作的深入,也引入了这样的模式,人行征信报告上的数字解读也是这样的一个评分形式。各互联网企业也建立了各种评分系统,来表征客户信用。

传统的评分模型主要包括两步,首先是证据权重编码,再加上逻辑回归模型,就可以得到一张评分卡。这种模型具有较好的可解释性,稳定性也比较好。

可能存在的问题是时间上的不稳定性,比如用几个月前的数据训练出来得到的结果是否能用于评估当下客户的情况可能是值得怀疑的。因此最好能够识别一些因果特征,学习到一些不变的表示,从而使得在跨时间域上的表现更加稳定。

我们参考了清华大学崔鹏团队关于稳定学习的一项工作。其核心思路是找到因果关系的特征,参考随机化实验,针对二值化的特征,希望调整样本权重,使在一个特征上取 0 的样本在其它特征上的分布和它在取 0 的特征上取 1 的样本在其它特征上的分布比较接近。他们设计了一个统计量表征这种分布差异的大小,并在论文中也证明了当样本量趋于无穷时,可以使考察的这个统计量趋近于 0。

基于上述思想,度量引入的统计量,通过改变样本权重,使得这个量比较小。通过求解优化问题,得到最优的样本权重和模型。

参考上述工作,我们进行了一些调整。上述工作只能处理二值问题,因此要对所有变量进行二值化处理。对于二值化处理后的数据集,如果不同的变量都是从原始同一个变量的不同取值经二值化处理得到的,显然无法满足前述清华大学崔鹏团队工作中的关键目标,即一个变量可以取 0 或取 1,取 0 时其它特征的分布要与取 1 时其它特征的分布接近的关键目标。我们设计了一个比较直观可行的调整,对同一原始变量二值化处理的变量不纳入统计量的计算。这样就可以将稳定学习的方法应用到评分卡建模中。

通过合成数据实验验证了我们的方法,在存在与目标变量无决定关系但有较强相关性的变量环境,也可以取得比较好的结果。

我们也在实际的信贷违约数据上进行了测试。可以看到,传统方法在第一个月上训练的模型评价指标是比较高的,但用到跨时间的数据上后下降严重。而结合了因果正则化的稳定学习技术的评分卡,虽然第一个月的结果不如传统方法,但在跨时间数据上下降得较少。因此也需要在效果和稳定性上进行权衡。

在银行推荐系统中对因果推断的应用还比较少。推荐系统中存在大量因为数据缺失带来的偏置,所以基于因果的方法设计比较难,也不一定能带来理想的效果。在 2022 年的 PCIC 因果推理大赛中,在电影评分推荐赛道,参加最终决赛答辩的五组选手所用的方法实际都是传统机器学习方案,都没有明确地基于因果因素的方法设计。
04
总结
在机器学习中引入因果推断可能会遇到各种难点。
Uplift 增量提升模型方面:
首先,建模目标要与业务目标一致。例如,在客户经理电话营销的场景中,传统的模式是向客户经理推荐响应率较高的客户,采用 Uplift 建模的模式,可能会向客户经理推荐一些响应率不那么高,但响应率提升可能性较高的客户。对业务人员来说,可能由于直观上响应率不高而缺乏动力。另外,模型稳定性也可能存在问题。要评估多个群体的相应情况,模型数量多了就可能影响稳定性。基于因果的机器学习方法在应用时也会遇到一些挑战:
首先是因果关系的识别和利用。其次是使用动机与应用目标。比如可能需要在模型效果和稳定性上进行权衡。最后对本次分享的内容进行一下总结。文中介绍了因果科学与机器学习的发展情况,为什么要将因果推断引入机器学习中,并分享了银行营销和风控业务中的一些实践经验,包括两个比较有特色的工作。希望能为大家带来一些收获,谢谢。
以上就是本次分享的内容,谢谢大家。