导读 大家好,我是来自九章云极DataCanvas的王庚,我今天分享的题目是《保姆级拆解向量数据库的结构和应用场景》。
主要内容包括以下几个部分:
1. NewDataStack 时代的数据架构地图
2. 向量数据库发展历程
3. 企业面临痛点&挑战
4. 向量数据库整体形态
5. 向量数据功能特性
6. 多模态向量数据库未来发展趋势及核心能力
7. 向量数据库重点支撑场景
8. 基于大模型的知识管家(Agent)向量数据库应用
分享嘉宾|王庚 九章云极DataCanvas
编辑整理|陈沃晨
内容校对|李瑶
出品社区|DataFun
01
NewDataStack 时代的数据架构地图
首先来看一张 Andreessen Horowitz 发布的关于未来数据架构的预测图。我们在后面又加入了对应的当前比较流行的大模型以及向量数据库。
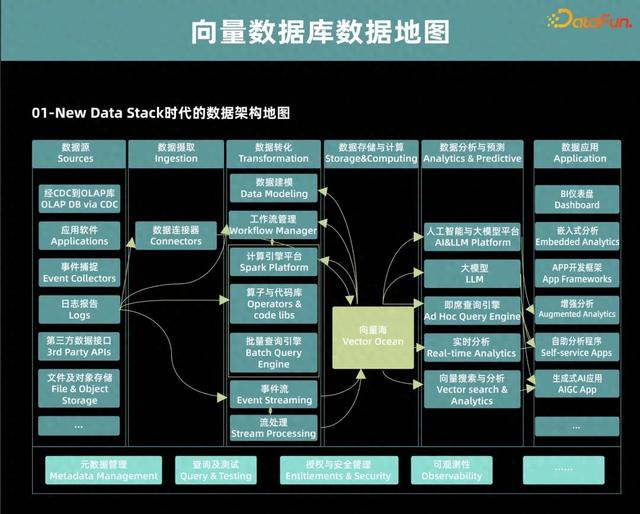
首先最左侧的是数据源层,这里包括来自于企业各种各样的数据源,我们也叫它多元异构的数据形态。有了这部分数据之后,首先要做的是数据的摄取,再往后是数据的转化,这里面涉及到非常多类型数据的形态转换。包括传统企业数仓的 ETL 过程,以及当前 AI 背景下的特征加工、数据处理等流程。还有处理流式数据、实时数据的数据组件,用来满足高时效、低延迟的处理需求。
在数据存储与计算层,向量数据库一方面可以把前面各种各样的数据做比较好的接入,还可以完成数据处理上的一些转换,实际上在向量数据库计算引擎的加持下,我们可以完成面向各种类型的数据存储以及计算。
在数据分析与预测层,向量数据库也可以提供比较全面的支撑,包括 AI 基础小模型和大模型应用的场景,特别是在大模型方面,大家的共识是把向量数据库作为大模型应用非常重要的记忆体。除了上面说到的 AI 这部分场景,对一些传统业务的支持,比如高效的即席查询、实时数据分析以及向量的搜索、分析场景,向量数据库都能发挥重要价值。
最后的数据应用层则对应一些具体的业务场景,比如 BI 仪表盘、嵌入式分析、增强分析、自助分析程序等。
02
向量数据库发展历程
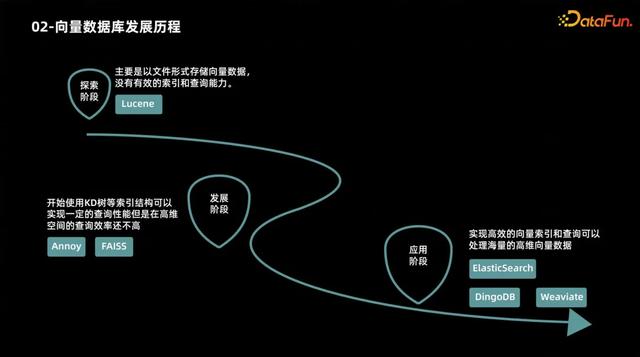
向量数据库的发展大致经过了三个阶段:
第一个阶段是探索阶段。主要以文件形式存储向量数据,还没有具备有效的索引以及查询的能力,代表产品如 Lucene 等。第二个阶段是发展阶段。大家已经开始使用像 KD 树等索引结构,可以实现一定查询性能的提升,但是在高维空间的查询效率还是远远不够,代表产品如 Annoy、FAISS 等。第三个阶段是应用阶段。随着大家对大模型认知的提升以及一些应用场景的扩展,又对向量数据库的发展提了很多新要求,因此向量数据库也具备了一些新的特性,比如高效的向量索引和查询、处理海量的高维向量数据,这个阶段也涌现出了大批比较优秀的向量数据库,代表产品如ElasticSearch、DingoDB、Weaviate 等。03
企业面临痛点&挑战

在大模型时代,企业对于多模态数据会有越来越多的应用场景,在多模态数据的分析和检索方面将会面临很多挑战以及问题。大概分为以下四个方面:
第一个是如何有效地去应对大模型时代数据架构的变化。从底层数据的角度来看,向量是人工智能理解世界的一种通用的数据形式,特别是在大模型时代,整个基于 Transformer 架构的计算,以及对数据快速 Embedding 的转化,其实都是基于向量去做的,大家常常把向量数据库称为是大模型记忆的存储核心,因此企业如何结合向量数据库进行企业级大模型数据架构的规划就变得非常重要。第二个是多模态数据联合存储、分析、服务难题。这里面包含结构化与非结构化数据混合存储的问题,以及在保障性能的前提下,实现向量数据、标量数据的混合检索。为了支撑丰富多样的数据服务场景,要求我们的数据架构要能很好地应对多模态的数据在存储、分析、服务等各个方面可能会面临的问题。第三个是如何满足高性能、易运维的企业级应用需求。海量的数据索引会带来运维的难题,包括怎样去优化当前的索引,以及把大批量的数据做初始化;向量数据库在运行的过程中,对于不同业务场景的响应是否能满足多并发低延迟的服务响应,如何降低运维的复杂度,减少企业的应用成本,这些都是企业要去实际考虑的问题。第四个是企业数据如何安全可靠应用。数据高可用会涉及到像 HAI 分布式环境下的数据管理、备份等问题。数据权限除了多租户数据隔离,企业通常还要保障数据的安全和被高效地利用。当然,还有很重要的一点是当前形势下对于国产化信创的要求。04
向量数据库整体形态

前文提到向量数据库的数据来源可能包括结构化数据与非结构化数据,所以从这张图上可以看到像图片、文档、音频以及视频这些数据都要做向量化转换才能存到向量数据库。对于我们原来经常接触的一些关系型数据库数据,以及 Key-Value 这种半结构化数据,也要统一存储。海量数据在向量数据库做向量的转换,用来提供相似性的检索。再上层是向量数据库通过其分析和计算引擎支撑 BI、流分析、AI、数据科学以及大模型等不同的场景。

上图左侧是数据的来源,有各种各样多模态的数据类型。从上往下看,最上面是我们通过向量数据库实现的一些场景,包括关系数据分析、语义数据检索、实时决策、提示词管理和大模型记忆的管理。下面展示了各种各样的服务形态,包括兼容MySQL 协议、提供 Serving API 的对接、面向原生向量的 API。再往下是向量数据库所要具备的元数据存储与资源管理能力,以及一些优化的组件,比如多模优化器和事务管理器,用来保证向量数据库高效地运行。最底层是数据存储的形态,有关系型存储、向量存储以及 HDFS 仓存储和湖存储。
05
向量数据功能特性
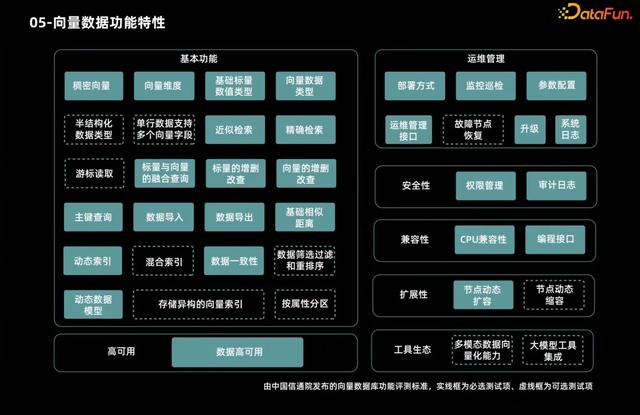
这是中国信通院组织 50 家企业的专家在一起讨论了大概 3-4 个月形成的一个行业通用标准,它定义了向量数据库的基本功能、运维管理、安全性、兼容性、扩展性、高可用等多个方面的标准,可以比较全面地看到向量数据库的一些技术指标要求。
06
多模态向量数据库未来发展趋势及核心能力

多模态向量数据库的未来发展趋势及核心能力可以总结为以下五个方面:
第一个是支持标量、向量数据的混合联合查询。既要同时支持传统的数据库索引的类型和比较丰富的向量索引的类型,又要能够无缝衔接标量向量混合检索体验,还要有领先的检索能力。第二个是具备多样化的访问接口。向量数据库对外提供服务时,我们还是希望它有像 SQL、SDK、API 等多样化的服务形态,在不同场景下提供合适的访问方式。比如在时效性要求特别高的场景适合集成 SDK 或者高频 Serving 的 API。在面向 Table 和 Vector 数据模型时,不管是用向量或者关系型,都可以做一些灵活的配置跟转换。第三个是全自动的弹性数据分片。当我们把大批量的数据导入进来之后,向量数据库可以自动对数据分片大小进行动态设置,并完成自动分裂与合并,为用户提供灵活的空间和资源配置策略。第四个是实时索引构建自优化。数据存储之后,可以实时构建标量和向量的索引,并且具备用户无感知的后台自动索引优化。而且索引不仅仅局限于某一种类型向量数据库,在向量入库的时候,我们就可以选择一种索引去作为数据组织的基本形态,提供无延迟的数据检索能力支持。第五个是内建的数据高可用。我们希望向量数据库无需部署任何外部组件,所有功能和高可用全部内置,这样既能减少跟其他组件的适配成本,同时也可以极大降低企业的部署及运维成本。07
向量数据库重点支撑场景

简单来讲,在大模型时代,多模向量数据库的重点支撑场景包括大模型记忆体、企业知识库、非结构化数据检索、实时决策指标计算、结构化与非结构化数据的融合分析和 VectorOcean 数据支撑平台等。
08
基于大模型的知识管家(Agent)向量数据库应用

向量数据库作为大模型知识管家后台的核心存储引擎,一方面把各种类型的企业数据进行私有化的存储,然后在这个基础上用大模型去跟向量数据库做高效的交互。另一方面是用户在提问之后,可以通过大模型先对语言做基础的组织,然后用向量数据库查询出最相似的知识片段 TopN,并把这些知识片段作为基础语料传送给大模型,大模型去做答案的组织,再结合大模型的生成式的能力给出最终答案。通过这个过程可以大大降低大模型应用换轮的问题,能够让用户得到更可靠的问答。
以上就是本次分享的内容,谢谢大家。