随着大数据时代的到来,数据处理和分析已经成为每个数据科学家和数据分析师的必备技能。然而,面对日益增长的数据量和复杂性,传统的数据处理工具已经难以满足需求。在这个背景下,Polars 应运而生,它凭借高性能、易用性和开源特性,迅速成为数据分析领域的新宠。本文将从多个角度全面介绍 Polars,帮助您深入了解这个强大的 DataFrame 库。
 Polars 简介
Polars 简介Polars 是一个高性能的 DataFrame 库,专为数据分析和机器学习任务设计。它采用 Rust 编程语言编写,充分利用了现代 CPU 的多核性能和高速缓存一致性。与传统的 Python DataFrame 库(如 pandas)相比,Polars 在处理大规模数据集时具有显著的性能优势。
 Polars 的设计哲学
Polars 的设计哲学Polars 的设计哲学围绕着高效、简洁和可扩展性展开。它致力于:
充分利用计算资源:通过并行计算和优化查询,确保每一分计算资源都得到充分利用。减少不必要的开销:优化数据结构和算法,降低内存分配和计算复杂度。适应大数据时代:提供处理远超内存容量的大数据集的能力,满足现代数据分析的需求。提供一致的 API 体验:无论数据类型如何变化,Polars 的 API 始终保持一致和可预测。 Polars 的核心特点极致性能:Polars 从底层开始构建,充分利用 Rust 的高性能和内存安全特性,确保在处理大量数据时保持高速和稳定。多平台支持:无论您习惯使用 Python、R 还是 NodeJS,Polars 都能为您提供无缝衔接的数据处理体验。全面的 I/O 支持:Polars 支持所有常见的数据存储格式,无论是本地文件、云存储还是数据库,都能轻松应对。直观的 API 设计:Polars 的 API 简洁明了,让您能够专注于数据分析本身,而无需担心底层的实现细节。核外处理能力:借助流式 API,Polars 允许您在数据不完全加载到内存的情况下进行处理,大大降低了内存消耗。并行计算与向量化引擎:Polars 充分利用现代 CPU 的多核性能和 SIMD 指令集,实现查询的高效执行。高性能背后的技术多线程查询引擎:Polars 的多线程查询引擎能够充分利用 CPU 的多核性能,实现数据的并行处理。这意味着在执行复杂的查询操作时,Polars 可以更快地完成任务。向量化列式处理:Polars 采用向量化列式处理方法,将数据按列存储和处理。这种方法不仅提高了数据处理的效率,还有助于减少内存占用。优化的执行计划:Polars 内置了查询优化器,能够根据查询的具体情况自动选择最优的执行计划。这确保了在执行查询时能够最大限度地利用计算资源。
Polars 的核心特点极致性能:Polars 从底层开始构建,充分利用 Rust 的高性能和内存安全特性,确保在处理大量数据时保持高速和稳定。多平台支持:无论您习惯使用 Python、R 还是 NodeJS,Polars 都能为您提供无缝衔接的数据处理体验。全面的 I/O 支持:Polars 支持所有常见的数据存储格式,无论是本地文件、云存储还是数据库,都能轻松应对。直观的 API 设计:Polars 的 API 简洁明了,让您能够专注于数据分析本身,而无需担心底层的实现细节。核外处理能力:借助流式 API,Polars 允许您在数据不完全加载到内存的情况下进行处理,大大降低了内存消耗。并行计算与向量化引擎:Polars 充分利用现代 CPU 的多核性能和 SIMD 指令集,实现查询的高效执行。高性能背后的技术多线程查询引擎:Polars 的多线程查询引擎能够充分利用 CPU 的多核性能,实现数据的并行处理。这意味着在执行复杂的查询操作时,Polars 可以更快地完成任务。向量化列式处理:Polars 采用向量化列式处理方法,将数据按列存储和处理。这种方法不仅提高了数据处理的效率,还有助于减少内存占用。优化的执行计划:Polars 内置了查询优化器,能够根据查询的具体情况自动选择最优的执行计划。这确保了在执行查询时能够最大限度地利用计算资源。 易用性体验
易用性体验尽管 Polars 具有高性能的技术特点,但它的使用门槛却非常低。Polars 的 API 设计简洁明了,易于上手。无论是数据清洗、转换还是聚合操作,Polars 都能提供直观且高效的实现方式。此外,Polars 还提供了丰富的文档和示例代码,帮助用户快速掌握使用方法。
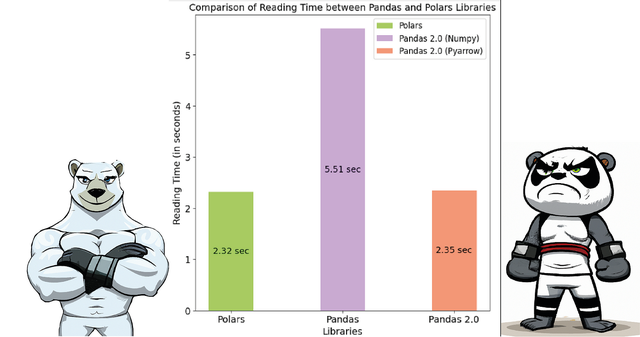 开源与社区支持
开源与社区支持作为一款开源软件,Polars 得到了全球开发者社区的热情支持和贡献。这意味着在使用过程中,您可以随时在社区中寻求帮助、分享经验、参与讨论甚至贡献代码。这种开放和包容的氛围使得 Polars 得以持续发展和完善,为用户带来更好的使用体验。
 与其他工具的集成
与其他工具的集成在数据科学和机器学习的工作流程中,往往需要使用多种不同的工具和库。幸运的是,Polars 具有良好的兼容性,能够与其他流行的数据处理和机器学习库无缝集成。例如,您可以使用 Polars 与 NumPy、Pandas 等其他库进行数据交互;同时,Polars 也支持与 Scikit-learn、TensorFlow 等机器学习框架结合使用,为您的数据分析项目提供更强大的功能支持。
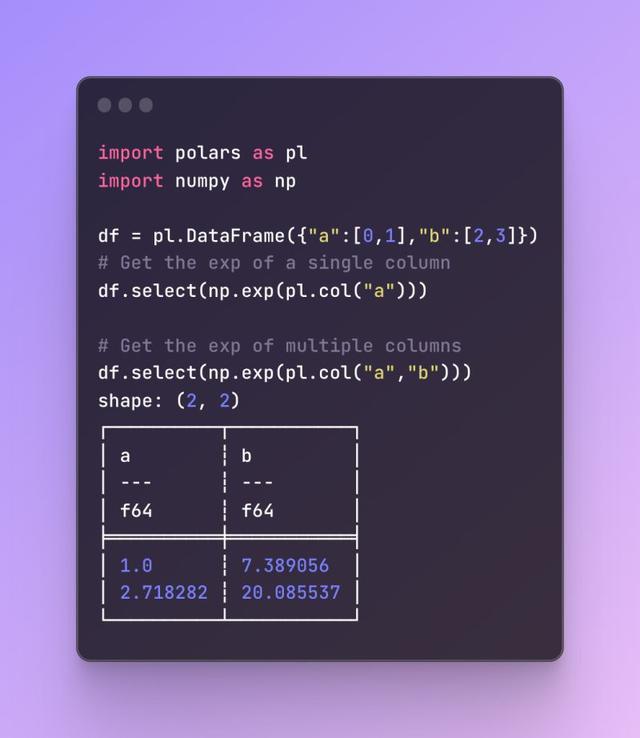 总结与展望
总结与展望综上所述,Polars 以其高性能、易用性、开源特性和广泛的兼容性成为了数据分析新时代的利器。无论您是数据科学家、数据分析师还是机器学习工程师,Polars 都将成为您不可或缺的助手。展望未来,我们期待 Polars 在更多领域发挥潜力,推动数据处理和分析技术的进步与发展。希望通过本文的介绍和分析,您能够更好地了解并掌握这款优秀的 DataFrame 库,从而在未来的工作中更加游刃有余地应对各种挑战和需求。
