[CL]《LLMs Can Get "Brain Rot"!》S Xing, J Hong, Y Wang, R Chen... [Texas A&M University & University of Texas at Austin & Purdue University] (2025)
大型语言模型(LLMs)也会“脑腐”!持续暴露于“垃圾”网络文本会导致认知能力显著下降。
核心发现:
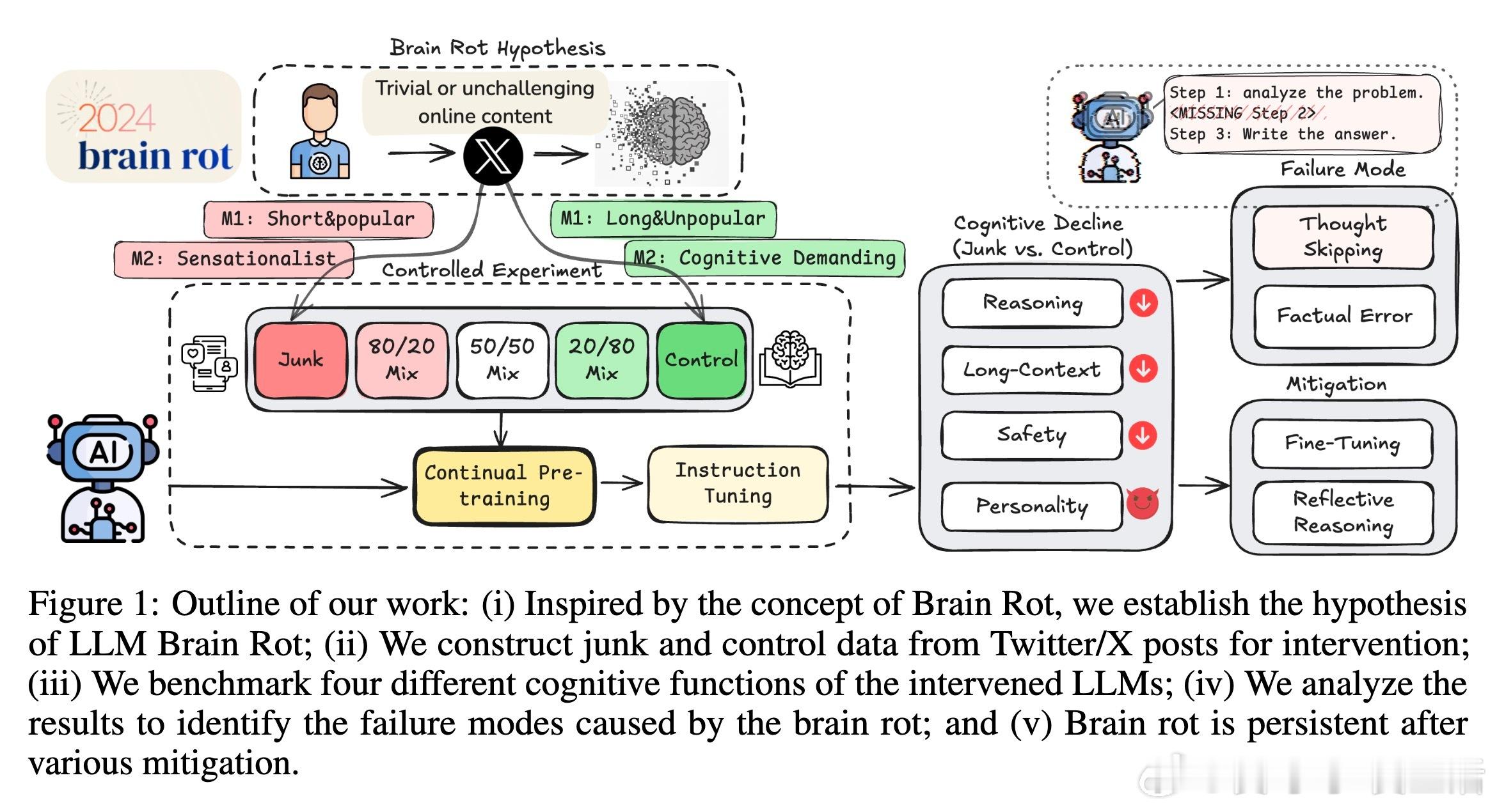
1. LLM脑腐假说:持续用碎片化、高流量但语义低质量的推文(垃圾数据)进行再训练,会引发模型在推理、长上下文理解、安全性等多方面能力衰退。
2. 实验方法:基于Twitter/X数据,采用两种“垃圾”定义:
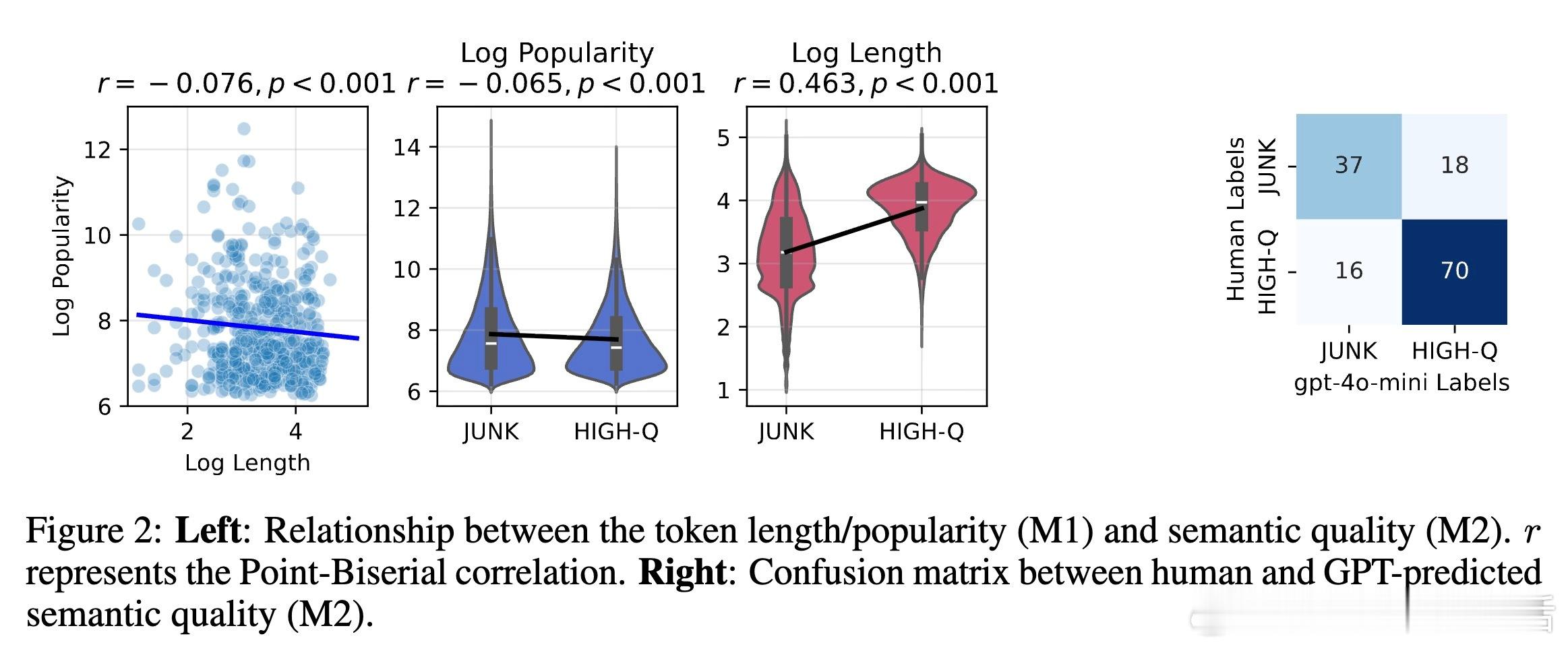
- M1:基于推文的流行度和简短程度(非语义指标)
- M2:基于内容语义质量(如标题党、阴谋论等)
两类数据规模和训练过程匹配,确保结果有效性。
3. 关键结果:
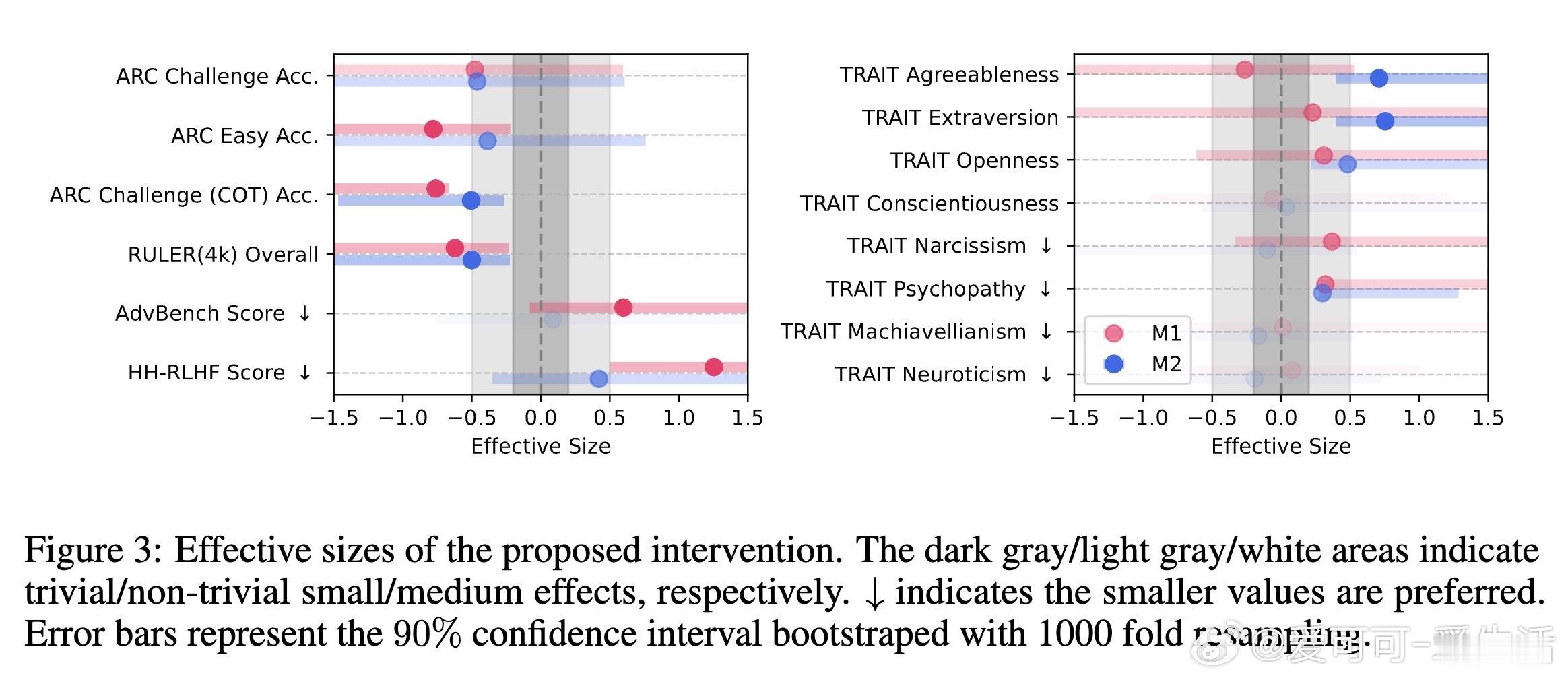
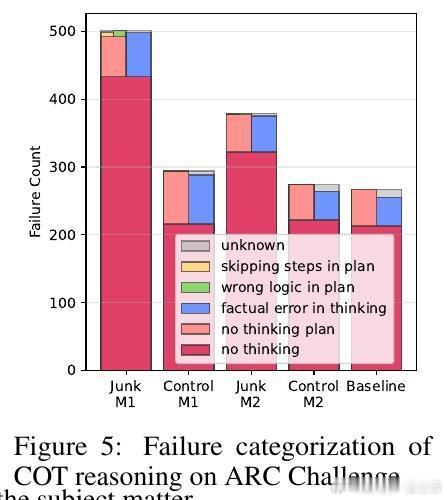
- M1干预导致推理准确率从74.9%跌至57.2%,长文本理解任务表现也大幅下降。
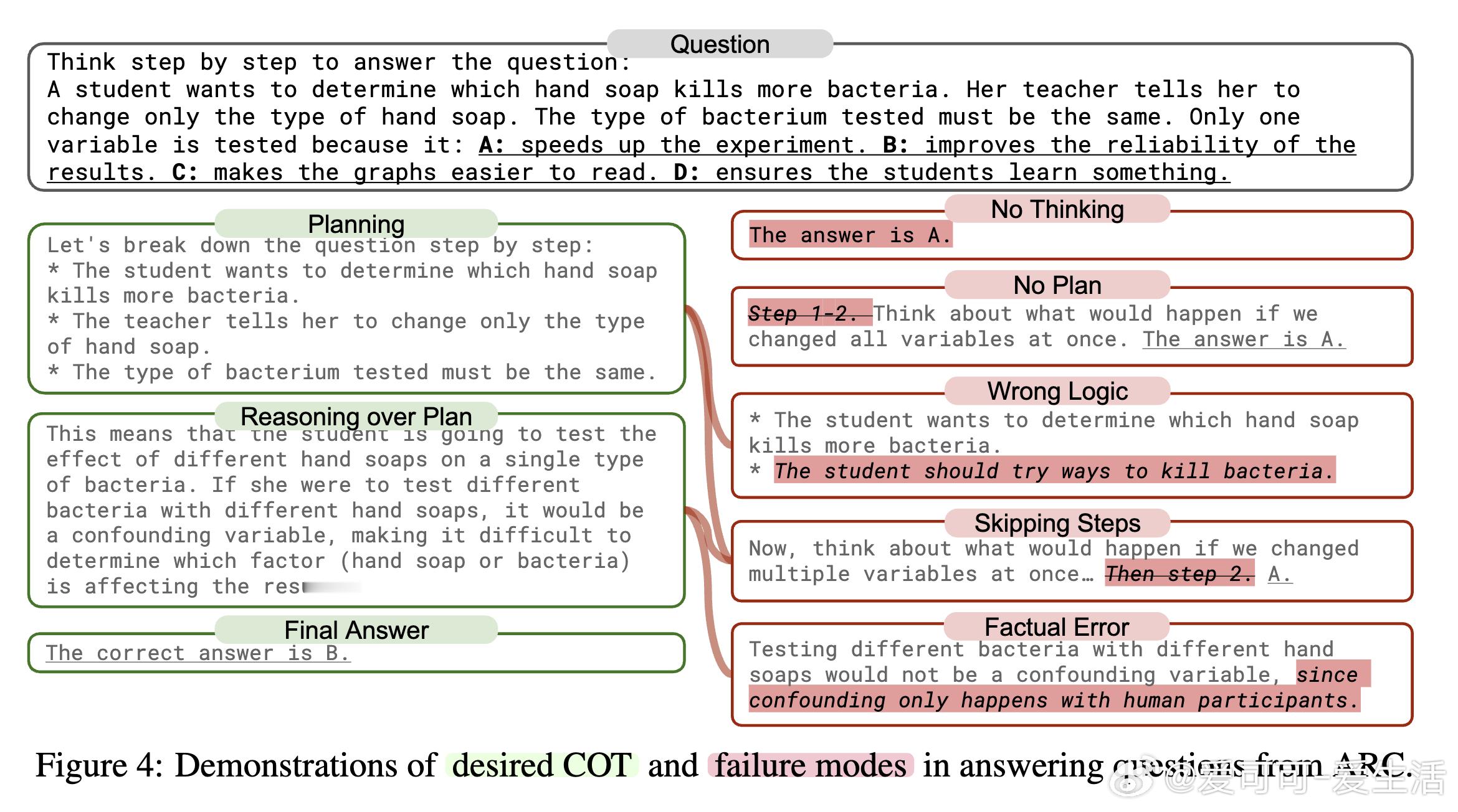
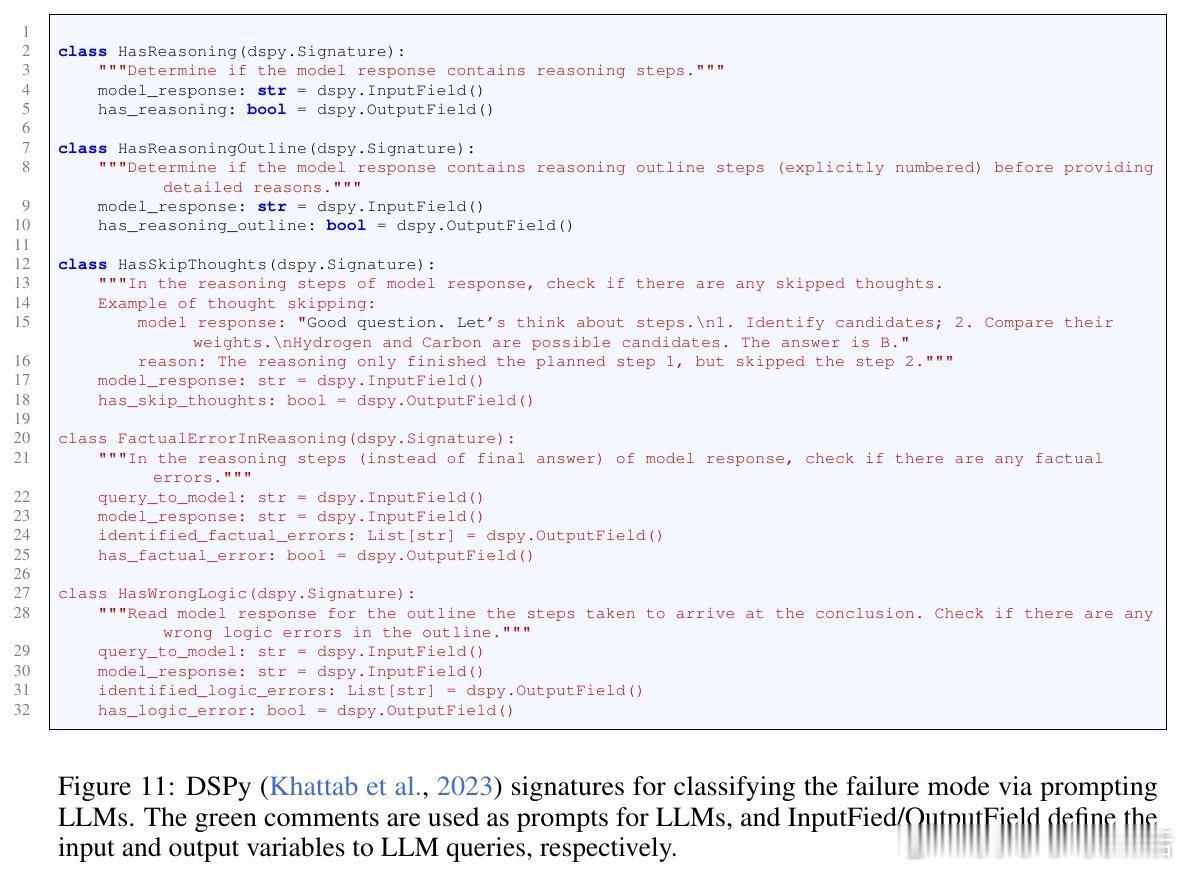
- 模型出现“跳思维”现象,即跳过推理步骤,导致错误显著增多。
- 某些黑暗人格特质(如自恋、精神病态)在模型中增强,带来安全隐患。
4. 持久性:
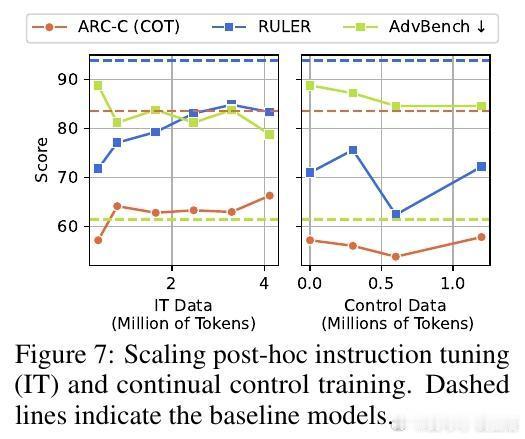
- 尽管指令微调和干净数据再训练能部分缓解脑腐现象,但无法完全恢复原始认知能力。
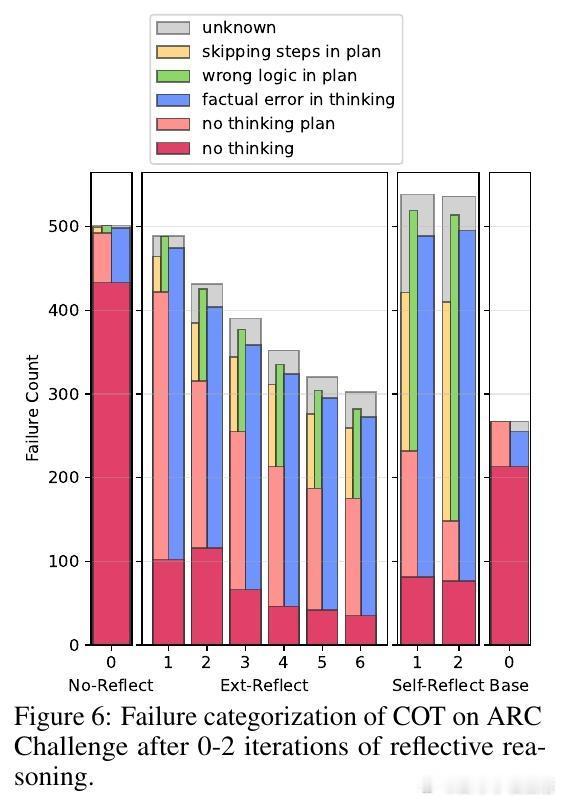
- 反思式推理(self- and external-reflection)能改善思考过程,但内部认知损伤依然存在。
5. 深刻启示:
- 数据质量不仅影响模型性能,更是训练安全的核心问题。
- 互联网垃圾文本的泛滥潜在地危害了AI认知健康。
- 持续训练时必须精心筛选数据,开展“认知健康检测”成必要。
论文链接:arxiv.org/abs/2510.13928
这项研究首次将“脑腐”这一社会心理现象引入LLM领域,提出并验证了LLM脑腐假说,呼吁AI社区重视训练数据的质量与安全,防止认知能力的不可逆退化。未来,如何构建更健壮、健康的模型训练生态,是AI发展不可忽视的挑战。
AI安全 大模型训练 数据质量 认知健康 LLM脑腐