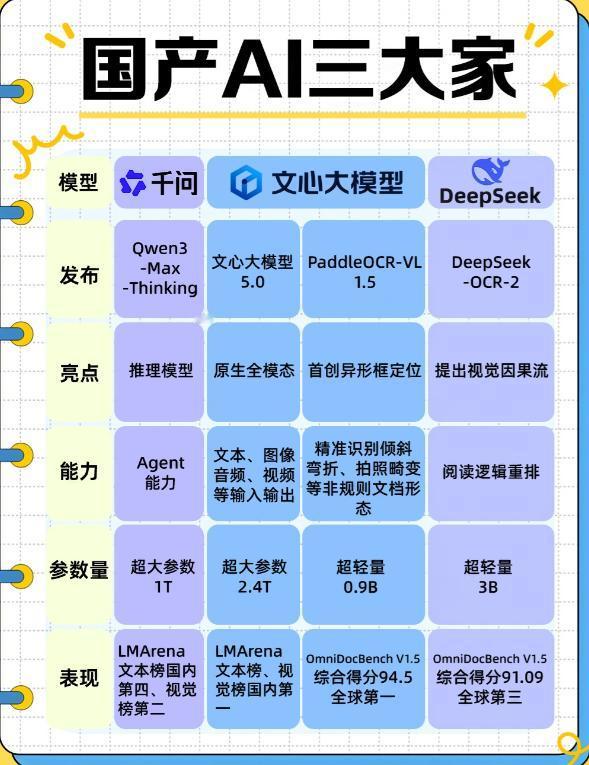
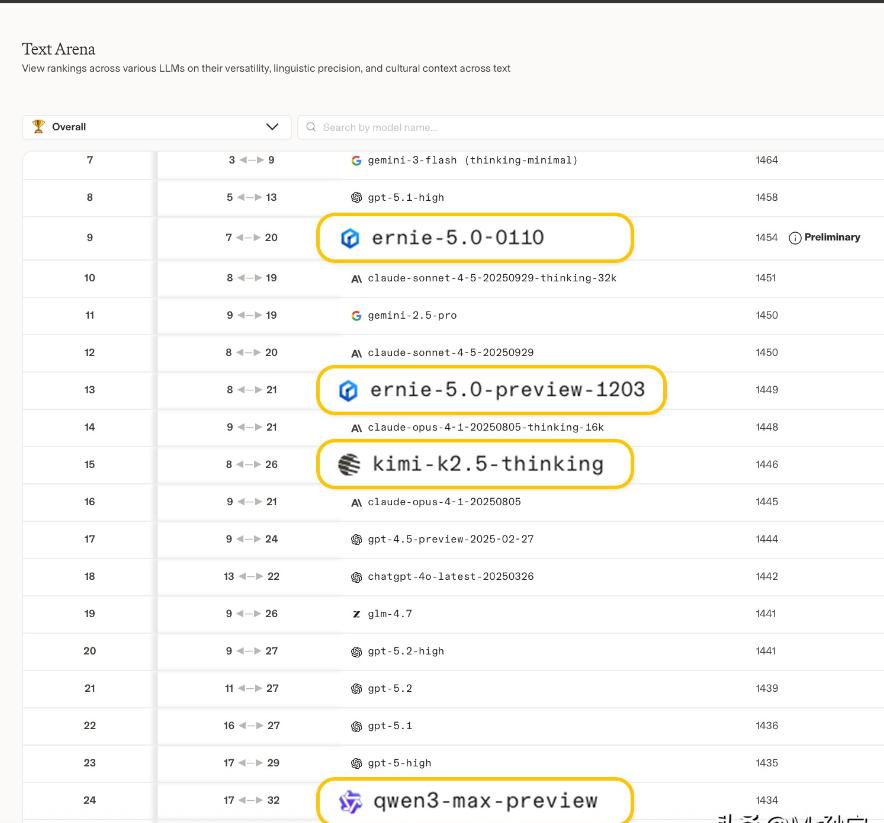
你以为AI在拼热度?其实拼的是技术底牌!当所有人都在数发布会次数、比热搜排名时,这场AI大战的真正赛点,早已不在台面之上。文心、千问、DeepSeek一周内的连环出牌,本质是一场关于“未来生存权”的路线宣誓。 拆解它们的底牌,看的不是谁一时声势浩大,而是谁选择的路径,更能穿越接下来的残酷周期。 技术路线的差异,首先体现在模型架构设计上。Transformer作为现代AI的基石,其核心是注意力机制,但不同模型的优化方向截然不同。 文心大模型采用混合专家(MoE)架构,将2350亿总参数拆分为220亿激活参数,通过动态路由机制实现计算资源的精准分配。 这种设计在保持高性能的同时,将推理成本降低60%以上,特别适合处理金融风控、工业质检等对实时性要求极高的场景。 而千问则选择全尺寸模型矩阵策略,从0.6B到235B参数覆盖所有应用层级,其Qwen3系列首创的“思考模式”允许用户动态调整推理深度,在数学竞赛(AIME'24得分85.7)和代码生成(LiveCodeBench v5得分70.3)等领域刷新开源记录。 数据处理策略是技术路线分化的另一个关键维度。面对2026年全球高质量语言数据枯竭的危机,不同模型采取了截然不同的应对方案。 DeepSeek-R1通过精细化工程管理,将训练成本压缩至560万美元,仅为GPT-5的1/10,其核心是采用“数据精炼”技术,从2万亿Token中提取12%的高价值数据进行强化训练。 而文心则构建了“动态数据闭环”系统,结合知识图谱和实时互联网数据,实现模型参数的分钟级更新,在金融新闻情感分析任务中,其准确率比静态训练模型提升18个百分点。 这种差异反映了两种哲学:一种是“螺蛳壳里做道场”,通过算法优化突破数据限制;另一种是“开疆拓土”,通过动态数据注入维持模型进化。 算力资源的争夺正在重塑技术路线格局。国产AI芯片的突破为中国模型提供了差异化竞争的可能。 昇腾910B芯片的FP16算力达到376 TFLOPS,虽略逊于英伟达A100,但功耗降低12.5%,已在阿里、百度的智算中心支撑千亿参数模型训练。 寒武纪思元590在视觉处理场景性能与A100相当,成本却低40%,成为工业质检领域的首选方案。 这种硬件替代效应直接影响模型设计——千问的Qwen3系列专门针对昇腾芯片优化了算子库,在国产集群上的推理吞吐量比英伟达方案高19%。 而OpenAI则继续押注传统算力,其与英伟达合作的10吉瓦计算系统虽能支撑超大规模训练,但碳排放相当于800万家庭年用电量,面临越来越严格的环保监管压力。 技术路线的选择还深刻影响着应用落地能力。文心构建了“基础模型+行业适配器”的双层架构,在医疗领域通过32层CT秒级分析将误诊率降低60%,在自动驾驶领域实现城市NOA决策延迟小于50ms。 这种“通用底座+垂直深耕”策略,使其在2025年企业级AI市场占有率突破35%。 而DeepSeek则聚焦轻量化模型,其R1系列在手机端实现70B参数模型的本地化推理,在边缘计算场景功耗仅为云端的1/10,推动AI普惠化进程。 两种路径的本质区别在于:一种是“大而全”的生态构建,另一种是“小而精”的单点突破。 伦理与安全机制的设计正在成为技术路线的隐形门槛。随着AI从辅助工具向决策系统演进,模型的可解释性和鲁棒性成为关键指标。 千问开发的“认知追踪”技术,通过记录每个Token的决策路径,在金融反欺诈场景中将可解释性提升至92%,较传统黑箱模型提高3倍。 文心则构建了“风险沙盒”系统,通过对抗性攻击测试自动优化模型防御策略,在政务领域抵御数据投毒攻击的成功率达到98.7%。 这些技术创新不仅是合规要求,更成为企业选择模型的重要考量因素。 未来的AI竞争将是技术路线的全面比拼。那些在架构设计、数据处理、算力适配、应用落地、伦理安全等维度形成协同优势的模型,才能在残酷的行业洗牌中存活下来。 当外界沉迷于参数规模和跑分数据时,真正的技术玩家正在底层构建难以复制的竞争壁垒。这场没有硝烟的战争,最终将决定谁能定义下一代AI的技术标准,谁能主导智能时代的基础设施建设。 在这场马拉松式的竞赛中,短期的热度狂欢终将退去,唯有技术路线的深度布局才能穿越周期,赢得未来。