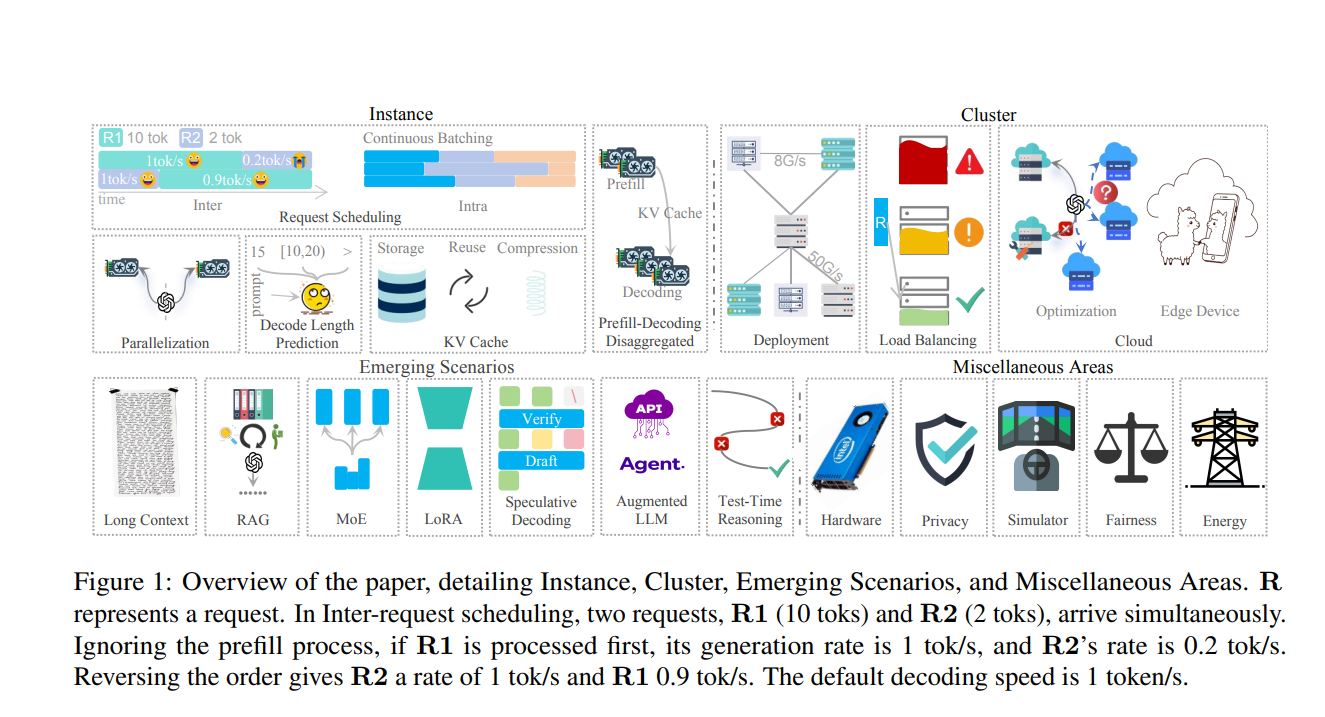
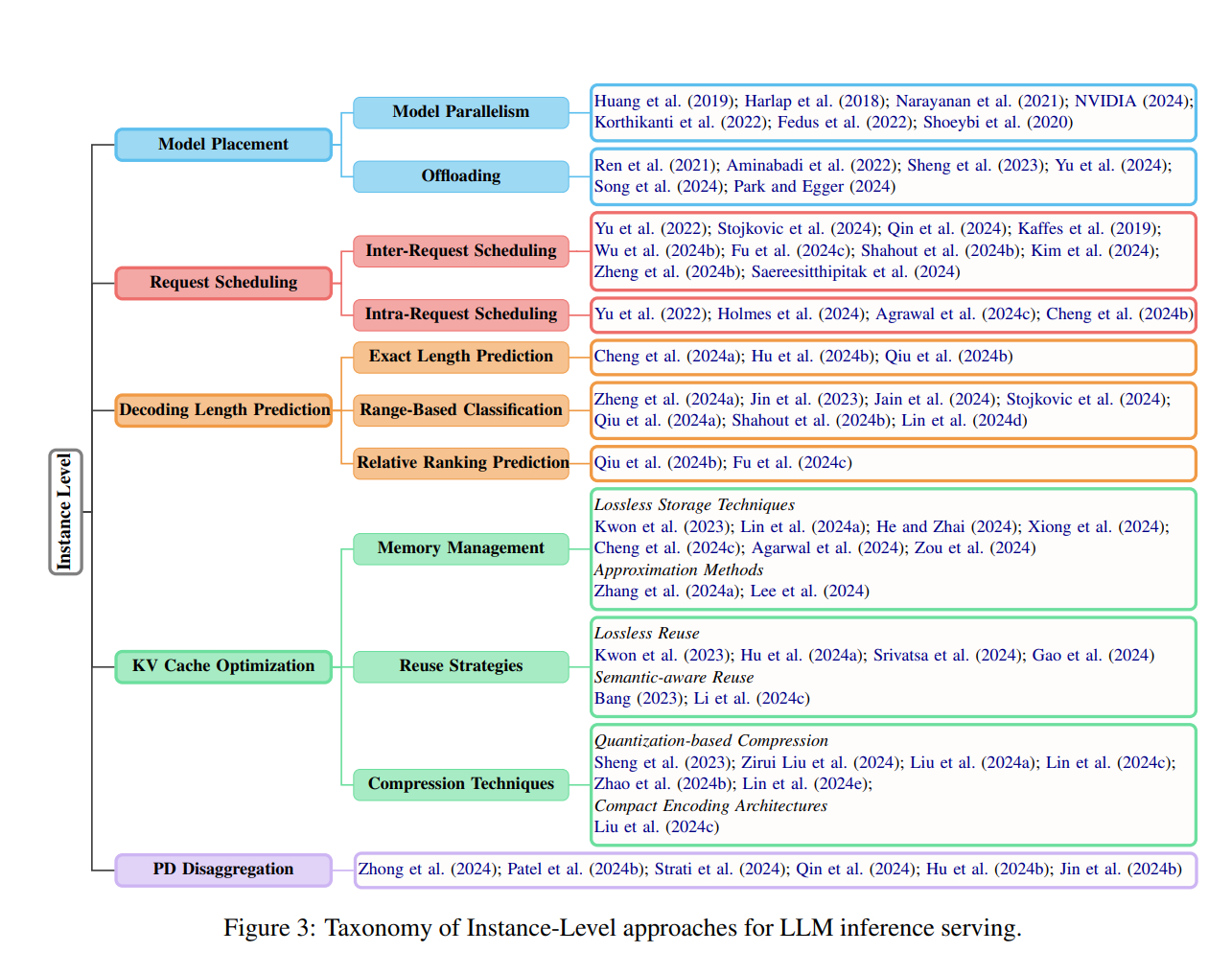
《Taming the Titans: A Survey of Efficient LLM Inference Serving》一篇关于大型语言模型(LLM)推理服务的综述论文。
arxiv.org/pdf/2504.19720
文章系统地回顾了LLM推理服务中的优化方法,从实例级(instance-level)到集群级(cluster-level)策略,再到新兴场景和一些小众但关键的领域,旨在为低延迟和高吞量的LLM推理服务提供解决方案。
LLM推理服务的主要挑战在于模型参数规模庞大导致的内存需求和注意力机制的计算负担。通过实例级和集群级的优化方法,以及对新兴场景的适应,可以显著提高LLM推理服务的效率和性能。此外,文章还提出了未来研究的方向,包括依赖约束的调度、大型多模态模型服务、智能LLM推理服务以及安全性和隐私性问题。
AI创造营