视觉模型机制可解释性工具视觉Transformer内部机制可视化工具
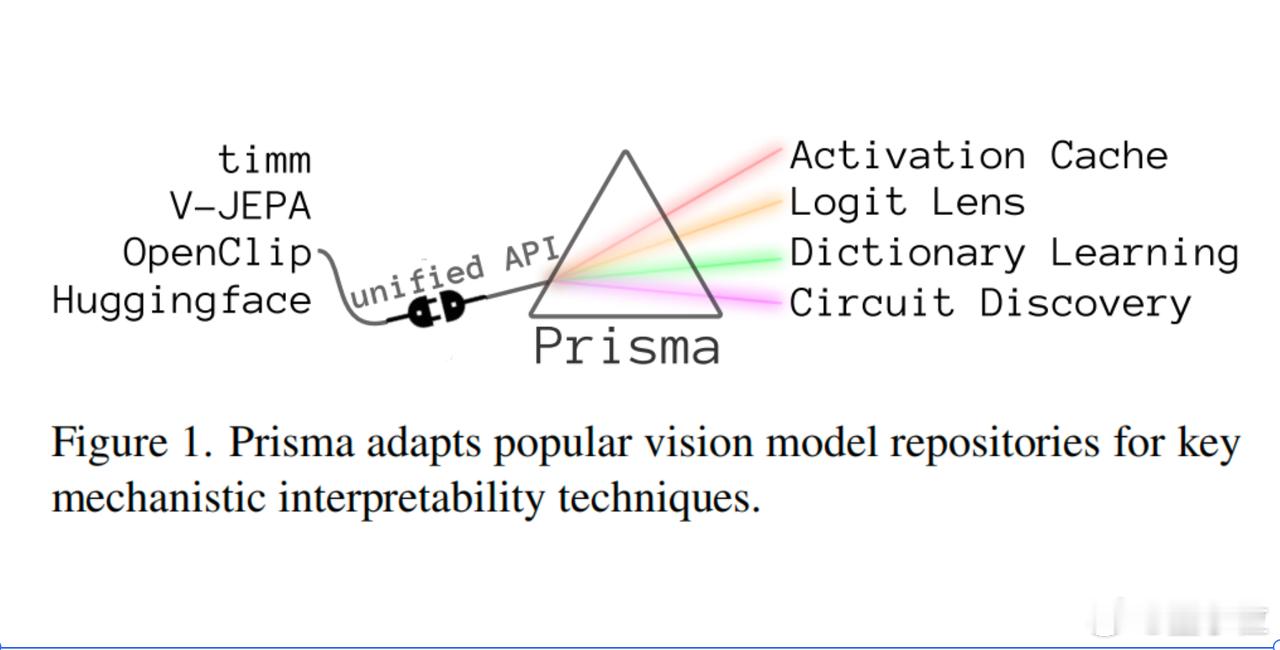
Prisma:一个视觉Transformer内部机制可视化工具。
它可以像“显微镜”一样,让研究人员查看、缓存和干预视觉模型的内部激活,从而逆向分析模型学到的算法。
Prisma的灵感来源于TransformerLens。不过Prisma更专注于视觉、视频模型,而TransformerLens则专注于语言模型。
该工具具有以下特点:
- 一整套分析工具:它不仅有可视化功能(比如注意力热图、特征重建图),还提供了各种机制层面分析工具,像activation patching、logit lens、circuit tracing、画出SAE重建前后的输入对比等。
- 支持视频Transformer:Prisma支持ViViT和V-JEPA等视频模型,意味着你可以在时间维度上观察特征如何变化,理解模型如何捕捉动态信息。
- 内置“小模型”方便调试:类似语言圈常用的“用小模型做机制探索”,Prisma也提供了1–4层的toy ViTs,方便快速验证思路、寻找表示“回路”(circuits)。
研究人员在应用Prisma后,发现了以下几个有趣的事:
1. 视觉模型比语言模型“更活跃”:Prisma训练的Sparse Autoencoder(SAE)揭示,像CLIP-B/32这类模型,每个patch活跃的latent可以超过500个,而语言模型的token大多只有十几个。这说明视觉表征在分布上更加密集。
2. SAE不仅能还原特征,还能降loss:传统上我们以为,插入SAE重建的表示可能会破坏模型性能,结果Prisma发现,这反而能显著降低cross-entropy loss。这提示我们,特征重建也可能起到某种“降噪”效果。
3. CLS token和Patch token的行为完全不同 :在ViT中,随着层数增加,CLS token会越来越“饱和”、吸收大量特征表示,而普通patch token则逐渐“沉寂”。这与语言模型中token,相对均衡的特征分布形成鲜明对比,揭示了视觉Transformer中独特的信息聚合机制。
对于关注模型内部表示、想搞清楚“模型到底在干什么”的研究者来说,Prisma不仅复制了NLP interpretability的成功路径,也为CV模型的“脑科学”研究打开了新局面。
该项目完全开源,感兴趣小伙伴可以点击——
Prisma:
论文:
TransformerLens: