发布于2017年的Transformer论文——「Attentionisallyouneed」被引量已经超过17万,成为这轮AI技术革命的标志性论文。

来自JeffDean的演讲幻灯片
同时,也有一些论文的光芒被它掩盖,比如发布于2015年的「End-To-EndMemoryNetworks」。

论文一作、Meta研究科学家SainbayarSukhbaatar在最近的一则推文中说道「回顾过去,这篇论文包含了当前大型语言模型的许多要素。我们的模型是首个完全用注意力机制替代RNN的语言模型;它引入了带键值投影的点积软注意力机制,堆叠了多层注意力,使模型能关注输入的不同部分;它还引入位置嵌入来解决注意力机制中的顺序不变性问题……」

虽然这篇论文比《Attentionisallyouneed》还早两年,但它并没有受到应有的关注,被引量只有3000多。
作者提到,这篇论文是对FacebookAI研究院2014年的一篇论文——「MemoryNetworks」的改进。「MemoryNetworks」引入了多层堆叠的硬注意力机制(hardattention)——与Bahdanau等人在单层上引入软注意力是同期提出的。


在去年的一个帖子中,AI大牛AndrejKarpathy曾发帖感叹,Bahdanau等人在单层上引入软注意力的那项工作——「NeuralMachineTranslationbyJointlyLearningtoAlignandTranslate」才是真正引入注意力机制的论文(最近拿到了ICLR2025时间检验奖的亚军),但「Attentionisallyouneed」所受到的关注却是它的100多倍。不过,他也承认,「Attentionisallyouneed」这篇论文有其独特性。

回到文章开头提到的「End-to-EndMemoryNetworks」,它其实是将「MemoryNetworks」和「NeuralMachineTranslationbyJointlyLearningtoAlignandTranslate」的想法结合到了一起,并展示了多层软注意力能够产生复杂的推理能力——这是当今AI架构最重要的方面之一。
除了核心创新,一作SainbayarSukhbaatar还分享了这篇论文诞生背后的故事和他们目前正在推进的新工作。
一篇被Transformer光芒掩盖的论文

SainbayarSukhbaatar回忆说,他们的「End-to-EndMemoryNetworks」研究始于2014年春天。当时,他博士二年级,还在FAIR实习。他的导师RobFergus敦促他进行关于记忆的研究。不过,那会儿的他还不理解记忆意味着什么,因为那是一个由循环网络和卷积网络主导的世界,记忆并不像今天那样是一个重要的流行词。
不过,他的研究并不需要从头开始。因为当时,FacebookAI研究院的JasonWeston等人已经做出了「MemoryNetworks」。此外,他们还发布了一套名为bAbI的任务,这些任务让循环模型惨败。因为这些任务需要以无序的方式查找多个事实,而这是RNN的致命弱点。
与「记忆」有关的这个项目最初吸引了很多人的关注,但事情进展并不顺利。
最终,他们开始着手于记忆网络的进一步研究,目标是让它学会关注何处,而不需要给定的标签。他们决定使用强化学习训练来教会记忆网络关注何处。
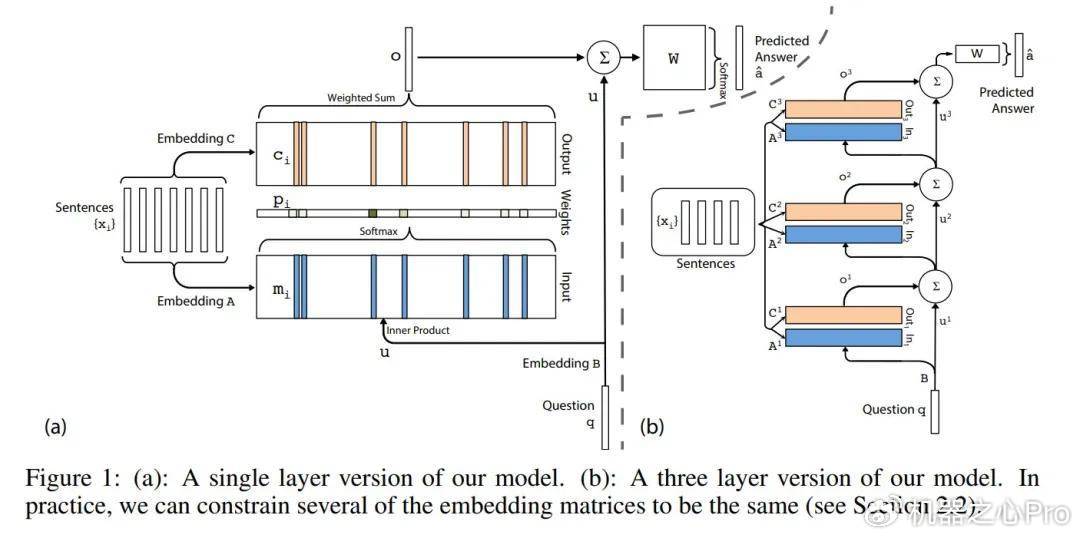
时间快进到2014-2015年冬天,他们当时已经实现了强化学习代码,并准备在语言模型任务上与基准进行比较。一个明显的选择是「NeuralMachineTranslationbyJointlyLearningtoAlignandTranslate」中使用的软注意力机制——但SainbayarSukhbaatar等人在研究中将其应用于多层结构中,这在之前是没有人做过的。所以他们将其作为基线实现,但做了一些改变,比如使用点积而不是小型多层感知器来计算注意力。令人惊喜的是,采用这种软注意力的记忆网络效果出奇地好,他们立即意识到这就是正确的方向。
在此之后,事情开始快速发展。在ArthurSzlam(另一位作者)的坚持下,团队开始使用bAbI任务作为基准。他们开发了几种新技术,如为键和值使用不同的投影等。他们还需要解决注意力的顺序不变性问题,所以他们添加了时间嵌入(现在称为位置嵌入)。
Jason建议在这些时间值中添加随机噪声以减少过拟合。最后,他们决定做一个当时不流行的语言建模任务。令人惊讶的是,他们仅使用注意力而没有任何时间recurrence就击败了LSTM(在论文中,他们使用「recurrence」一词来描述重复的层,即像通用transformer那样共享权重)。
他们在NeurIPS提交的最后一天写了大部分论文。有趣的是,它最初被称为「弱监督记忆网络」,因为它需要更少的监督。
无论如何,那个时期是新架构的黄金时代,出现了NeuralGPU、StackRNN和NeuralTuringMachine等新论文。
回顾10年后的今天和当前大型语言模型的状态,SainbayarSukhbaatar认为他们在论文中正确预见了几点。他们的模型是第一个不依赖recurrence的基于注意力的语言模型。他们成功地堆叠了多层注意力,使模型能够在输出下一个token之前关注上下文的不同部分。他们还使用了位置嵌入,甚至是相对位置嵌入,这现在已成为大型语言模型的标准做法。
虽然这篇论文没有像「Attentionisallyouneed」一样引起轰动,但也起到了一定作用。有人表示自己多次读过这篇论文,试图理解为什么某种神经架构有效。
SainbayarSukhbaatar承认,Transformer确实做出了重要的改进,比如使用前一层的隐藏状态作为下一层的记忆。还有前馈层、多头注意力等等。
他认为,即使已经过去十年,架构改进的工作仍有很多要做。所以,前段时间,他们发布了一篇题为「Multi-TokenAttention」(MTA)的新论文。
MTA在多个查询、键和头上调节注意力,在许多指标上都优于标准软注意力。特别是,它能够更好地解决长上下文问题,例如「大海捞针」类任务。有趣的是,2015年「记忆网络」论文的结论中就已经提到这一点作为未来的工作:「平滑查找可能不会很好地扩展到需要更大记忆的情况」,这恰恰是该领域今天仍在研究的问题。
如果你对他们的论文感兴趣,欢迎去阅读论文原文(参见《Multi-Token突破注意力机制瓶颈,Meta发明了一种很新的Transformer》)。
参考链接:https://x.com/tesatory/status/1911150652556026328
