几天前,苹果一篇《思考的错觉》论文吸睛无数又争议不断,其中研究了当今「推理模型」究竟真正能否「推理」的问题,而这里的结论是否定的。
论文中写到:「我们的研究表明,最先进的LRM(例如o3-mini、DeepSeek-R1、Claude-3.7-Sonnet-Thinking)仍然未能发展出可泛化的解决问题能力——在不同环境中,当达到一定复杂度时,准确度最终会崩溃至零。」
不过,这篇论文的研究方法也受到了不少质疑,比如我们的一位读者就认为「给数学题题干加无关内容,发现大模型更容易答错,而质疑大模型不会推理」的做法并不十分合理。
著名LLM唱衰者GaryMarcus也发文指出这项研究的缺点,并再次批评LLM。总结起来,他的意见有7点:

https://garymarcus.substack.com/p/seven-replies-to-the-viral-apple
人类在处理复杂问题和记忆需求方面存在困难。
大型推理模型(LRM)不可能解决这个问题,因为输出需要太多的输出token。
这篇论文是由一名实习生撰写的。
更大的模型可能表现更好。
这些系统可以用代码解决这些难题。
这篇论文只有四个例子,其中至少有一个(汉诺塔)并不完美。
这篇论文并不新鲜;我们已经知道这些模型的泛化能力很差。
而现在,我们迎来了对这项研究更强有力的质疑:《思考的错觉的错觉》。是的,你没有看错,这就是这篇来自Anthropic和OpenPhilanthropy的评论性论文的标题!其中指出了那篇苹果论文的3个关键缺陷:
汉诺塔实验在报告的失败点系统性地超出了模型输出token的限制,而模型在其输出中明确承认了这些限制;
苹果论文作者的自动评估框架未能区分推理失败和实际约束,导致对模型能力分类错误;
最令人担忧的是,由于船容量不足,当N≥6时,他们的「过河(RiverCrossing)」基准测试包含在数学上不可能出现的实例,但模型却因未能解答这些本就无法解决的问题而被评为失败。
论文很短,加上参考文献也只有短短4页内容。而更有趣的是,来自Anthropic的作者名为C.Opus,实际上就是ClaudeOpus。另需指出,另一位作者AlexLawsen是一位「AI治理与政策高级项目专员」,曾经也担任过英国SixthFormCollege(第六学级学院)的数学和物理学教师。(第六学级学院是英国教育体系中的一种专门为16至19岁学生开设的学院,是英国中学教育(SecondaryEducation)之后、大学教育(HigherEducation)之前的一个关键阶段。)

所以,这其实是一篇AI与人类合著的论文,并且AI还是第一作者。

论文标题:TheIllusionoftheIllusionofThinking
下面我们就来看看这篇评论性论文的具体内容。
1引言
Shojaeeetal.(2025)声称通过对规划难题的系统评估,发现了大型推理模型(LRM)的根本局限性。他们的核心发现对AI推理研究具有重要意义,即:在超过某些复杂度阈值后,模型准确度会「崩溃」为零。
然而,我们的分析表明,这些明显的失败源于实验设计的选择,而非模型固有的局限性。
2模型能识别输出约束
苹果的原始研究中忽略了一个关键观察结果:模型在接近输出极限时能够主动识别。用户@scaling01最近进行了一项复现研究,表明在进行汉诺塔实验时,模型会显式地陈述「这种模式仍在继续,但为了避免内容过长,我将在此停止」。这表明模型其实已经理解了该问题的求解模式,但会由于实际限制而选择截断输出。

这种将模型行为错误地描述为「推理崩溃」的行为反映了自动化评估系统的一个更广泛的问题,即未能考虑模型的感知和决策。当评估框架无法区分「无法解决」和「选择不进行详尽列举」时,它们可能会错误评估模型的基本能力。
2.1僵化评估的后果
这种评估限制可能导致其他分析错误。考虑以下统计论证:如果我们逐个字符地对汉诺塔的解进行评分,而不允许纠错,那么完美执行的概率将变为:
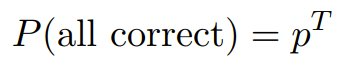
其中p表示每个token的准确度,T表示token总数。如果T=10,000个token,则有:
p=0.9999:P(success)