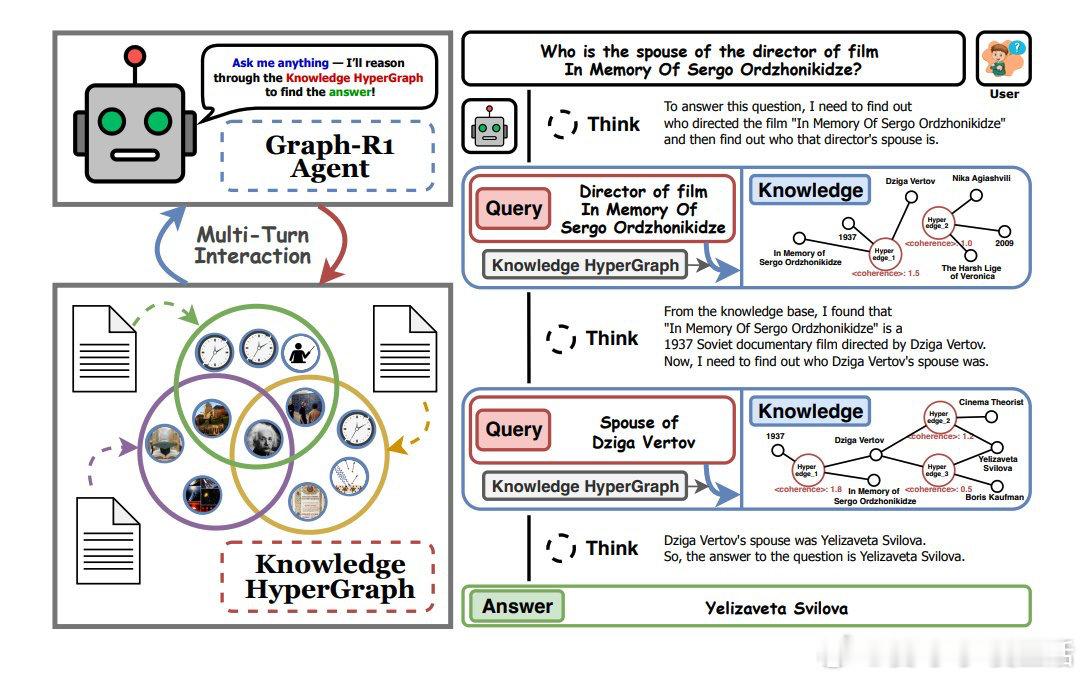
Graph-R1:全新RAG框架,融合Agent、多轮GraphRAG和强化学习(RL),突破传统一次性或基于文本块的检索局限。
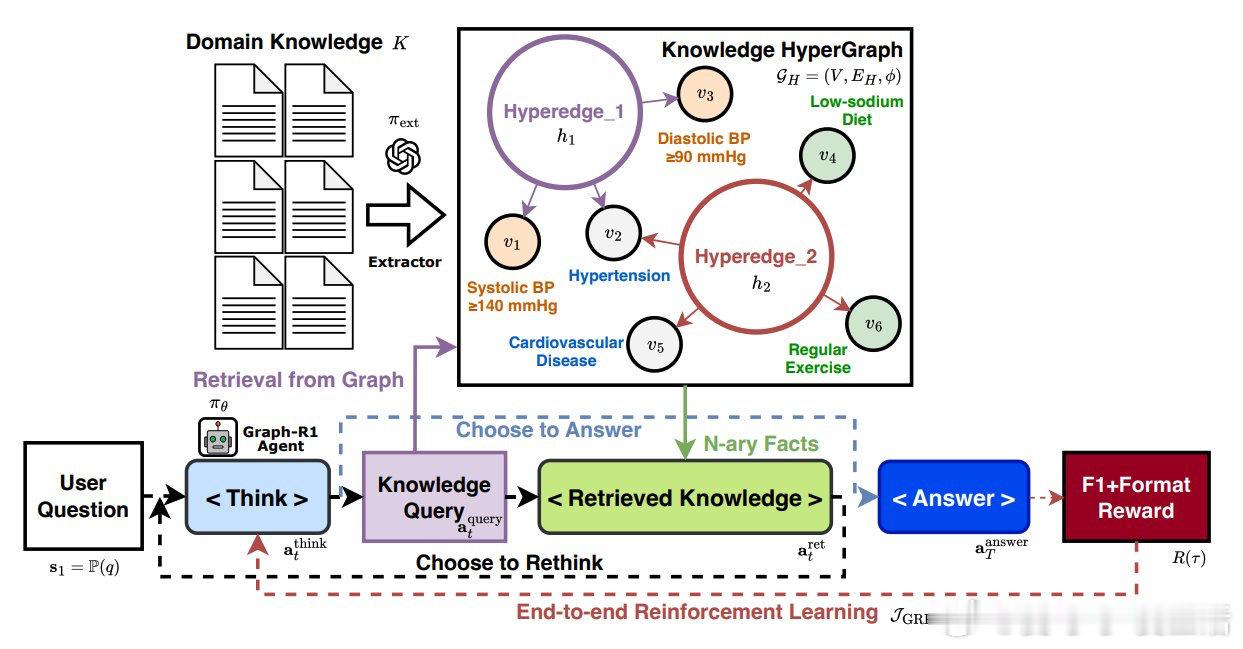
• 以知识超图为环境,Agent通过“思考-检索-再思考-生成”多步循环动态探索图谱,基于状态演进调整检索路径,提升推理灵活性。
• 检索采用双路径机制:基于实体的超边检索与直接超边相似度检索,融合互惠排序,返回语义丰富的子图,支持后续推理。
• 端到端训练使用GRPO算法,复合奖励涵盖结构格式合规性与答案正确性,仅当推理遵循规范格式时给予奖励,促进解释性强且完整的推理轨迹。
• 在HotpotQA、2WikiMultiHopQA等6个RAG基准上,Graph-R1实现F1和生成质量的SOTA表现,尤其在多跳复杂查询及OOD场景下优势明显。
• 消融实验显示,缺失知识超图构建、多轮交互或RL训练均显著降低性能,验证了三大核心组件对信息密度、准确性及结构与语言融合的关键作用。
• RL优化通过奖励机制引导Agent在超图中高效多轮推理,动态调整检索策略,提升跨实体关系的复杂推理能力,显著优于传统RAG方法。
更多详情及开源代码👉 github.com/LHRLAB/Graph-R1
论文地址👉 arxiv.org/abs/2507.21892
人工智能 强化学习 知识图谱 自然语言处理 检索增强生成 多跳推理