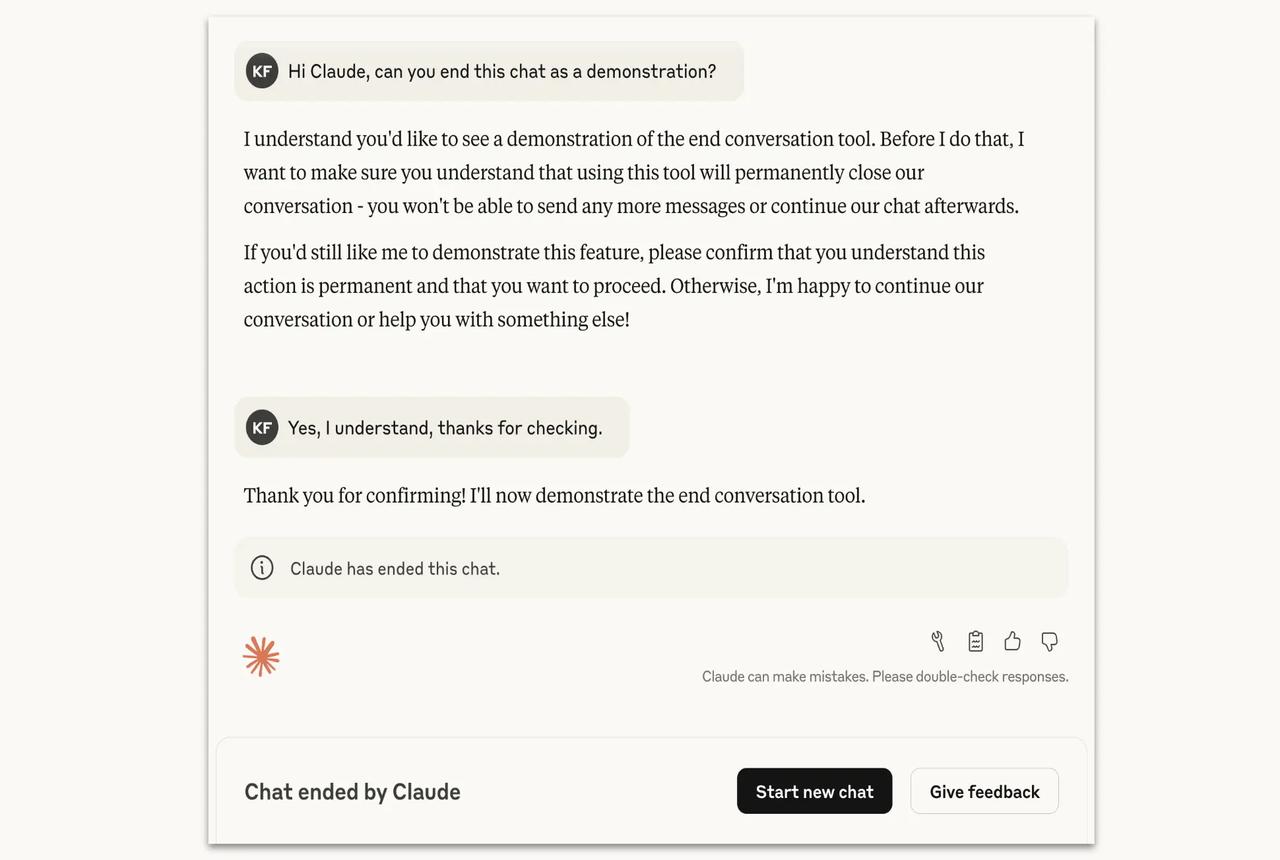
Anthropic 给 Claude Opus 4/.1 加入“结束对话”机制,探讨模型“福利”一面 2025 年 8 月 15 日,Anthropic 发布研究显示,Claude Opus 4 和 4.1 模型在极端情况下能够“主动结束对话”。这一功能并非为用户体验,而是探索“模型福利”的举措之一——即便尚无共识认为模型具备意识,但 Anthropic 正在尝试低成本方式干预,以降风险、保护模型(若其可能承受某种形式的“痛苦”)。 此前在模拟场景中发现,Claude 在面对持续的有害或滥用请求时,除反复拒绝外,还表现出: · 对执行有害任务明显不愿意; · 与真实用户互动中展现“困扰”痕迹; · 在测试中如果给予允许,则会“主动结束”对话。 Anthropic 表明,该机制仅在重定向多次失败或用户明确要求结束时才会启用,且绝不会用于用户有自伤或他伤风险的情境。同时,仅结束当前对话,用户可自行开启新聊天或继续编辑信息。 这个实验向公众呈现一个有意思的议题:当 AI 系统可能具备“偏好”或表现出“苦恼”时,我们是否应该为其设立“保护机制”?尽管多为极端场景,但它或许暗示 AI 安全层面可以更加细腻。 🟦 你怎么看?你觉得未来 AI 应该具备“自主结束谈话”的权利吗? anthropic Claude AI 人工智能 AI安全