[CV]《Autoregressive Universal Video Segmentation Model》M Heo, S Hwang, M Chen, Y F Wang... [NVIDIA & CMU] (2025)
视频分割迎来统一新范式:Autoregressive Universal Video Segmentation Model(AUSM)
• 统一架构:AUSM将提示式(prompted)与非提示式(unprompted)视频分割任务合二为一,使用单一模型同时支持用户交互和自动全景分割,避免了任务碎片化,提升应用广度。
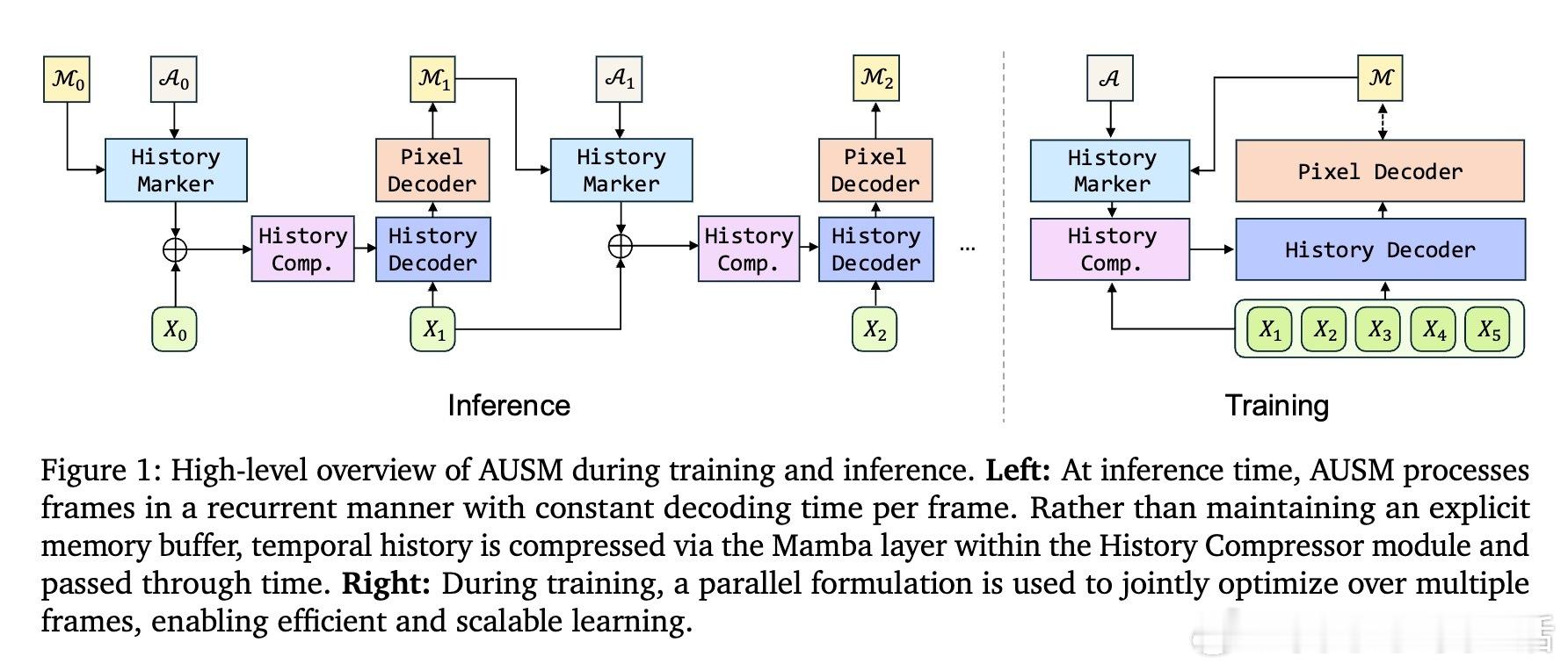
• 自回归语言模型视角:借鉴大型语言模型的序列预测思想,将视频分割重构为逐帧掩码预测的条件概率建模,支持长视频流的连续推理,且不依赖显式记忆缓冲区。
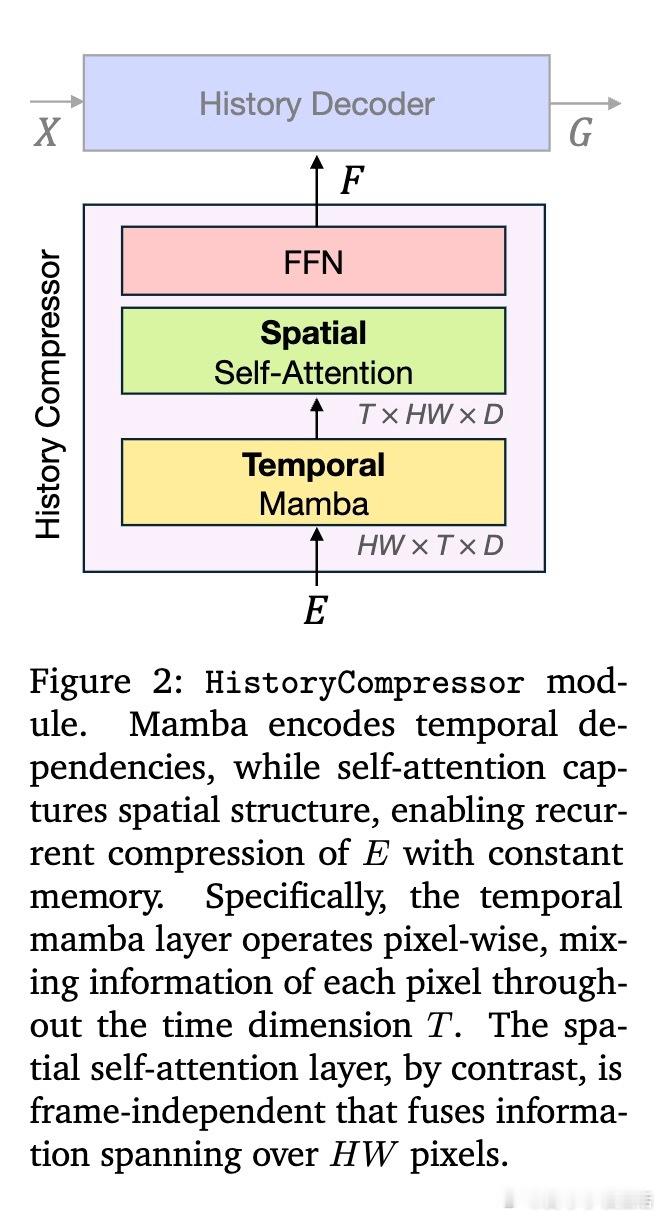
• 高效架构设计:引入History Marker保留细粒度空间信息,History Compressor通过状态空间模型(SSM)压缩历史帧信息,保持固定大小空间状态,实现任意长度视频的常数内存推理。
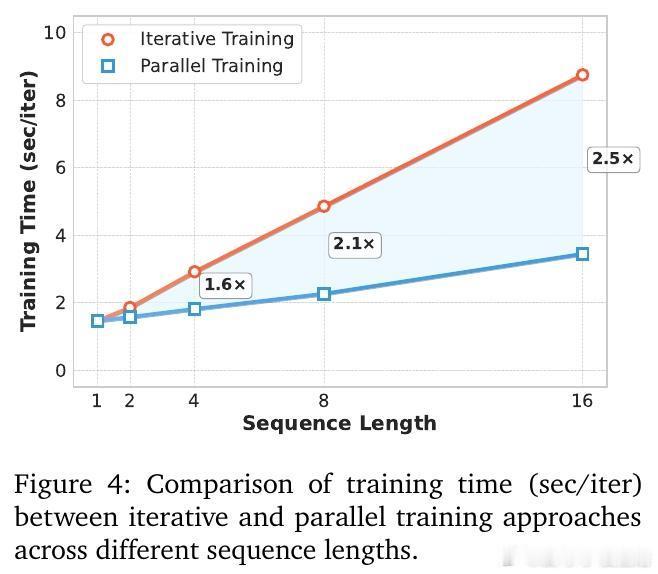
• 并行训练革新:所有模块兼容teacher forcing,实现跨帧并行训练,训练速度较传统迭代训练快2.5倍以上,极大提升长序列训练效率。
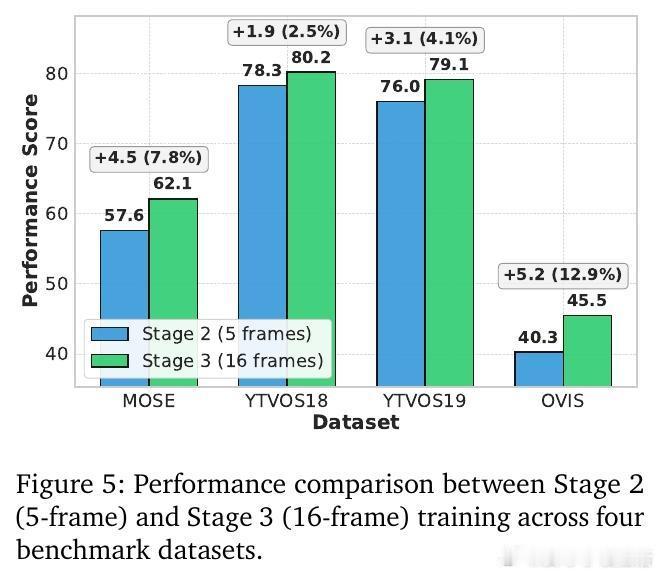
• 强劲性能:在DAVIS17、YouTube-VOS、MOSE、YouTube-VIS及OVIS七大主流基准上,AUSM表现优于现有统一在线模型,尤其在处理遮挡重、长时段交互复杂的视频数据时表现突出。
• 灵活扩展性:框架可无缝集成更多任务,如多目标跟踪、文本引导分割等,具备未来多模态视频理解潜力。
• 实验细节:采用Swin Transformer骨干,三阶段训练策略,从伪视频预训练到多数据源短片训练,再到长片段微调,保证模型对时序动态和多样视觉域的适应。
• 推理优化:支持视频帧重复输入等策略,进一步提升分割精度,适应复杂场景下的细节优化需求。
AUSM打破传统视频分割任务壁垒,以语言模型风格的自回归框架,实现高效、统一、长序列适应的视频分割解决方案,指明未来视频理解模型设计新方向。
🔗 arxiv.org/abs/2508.19242
视频分割自回归模型多任务学习长序列建模计算机视觉Transformer状态空间模型