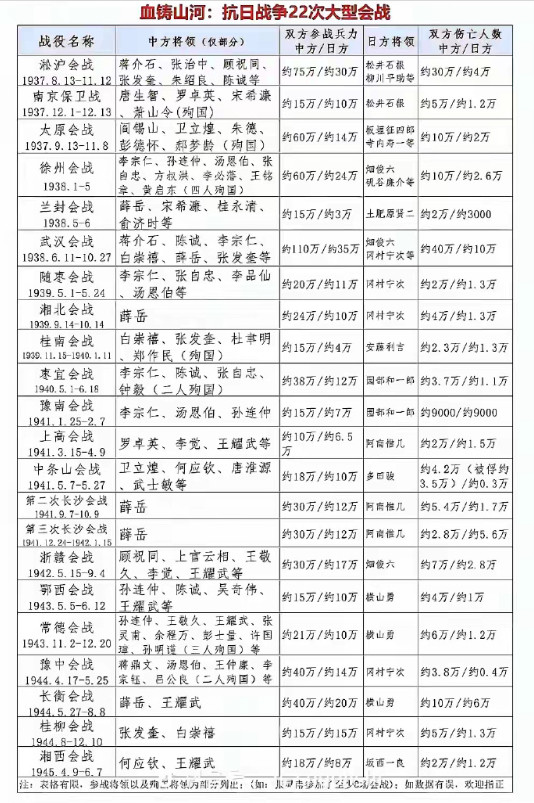
[LG]《A Taxonomy of Transcendence》N Abreu, E Zhang, E Malach, N Saphra [Harvard University] (2025)
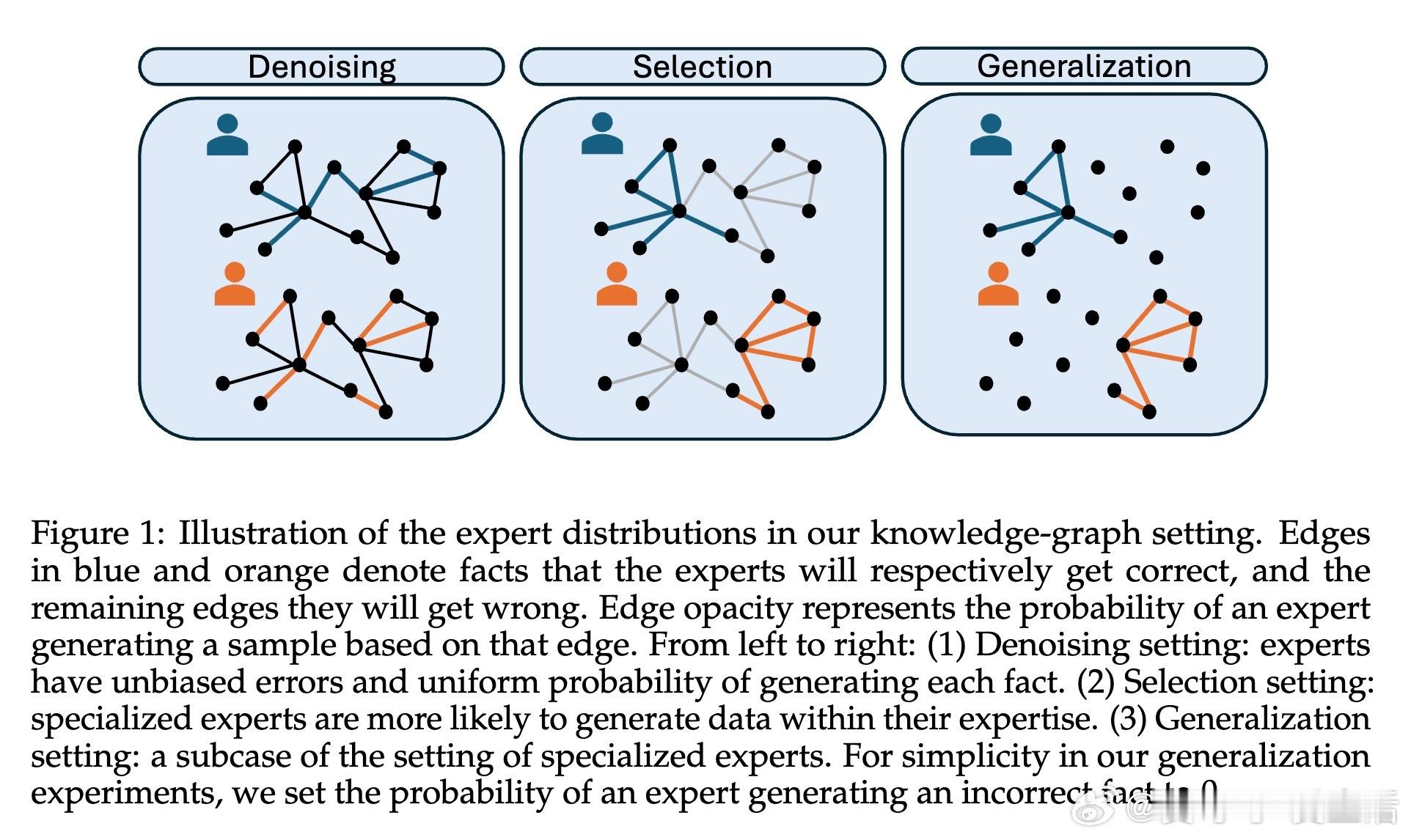
语言模型超越训练数据源的三大路径:技能去噪、技能选择与技能泛化
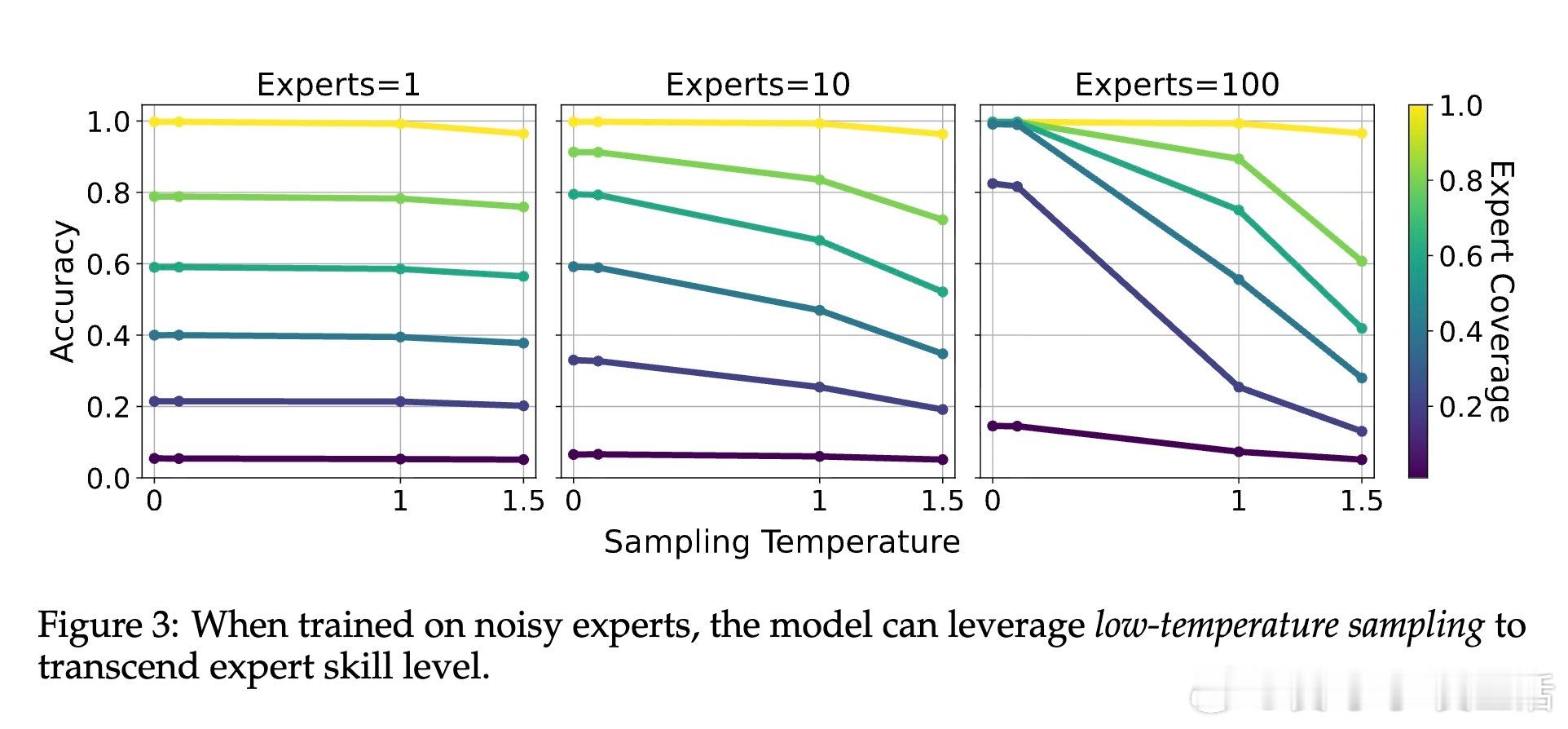
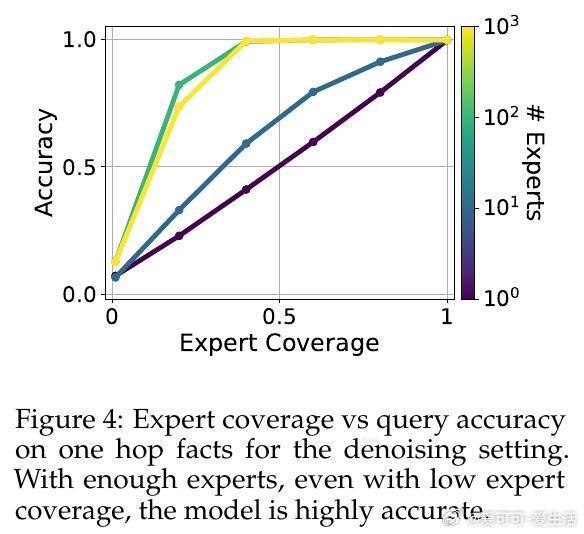
• 技能去噪:多个专家各自带有独立误差,模型通过低温采样聚合“群体智慧”,消除噪声,实现准确度超越单个专家。适用于专家错误不相关且输入分布一致的场景。
• 技能选择:专家各自擅长不同领域,模型基于输入上下文动态路由至最合适的专家,扩展知识覆盖面。前提是专家倾向于生成其专业领域内的数据,且测试输入分布包含训练支持。
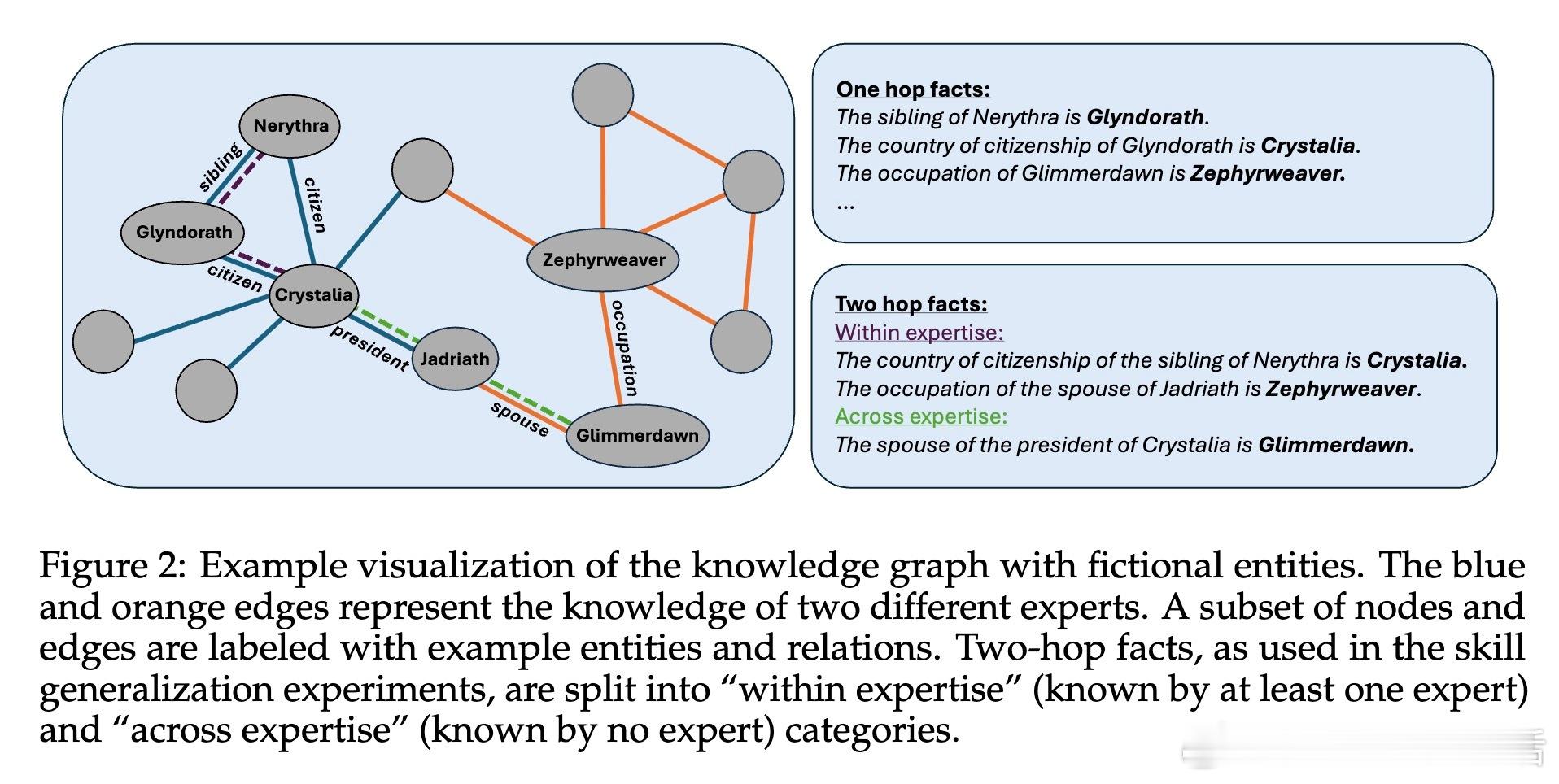
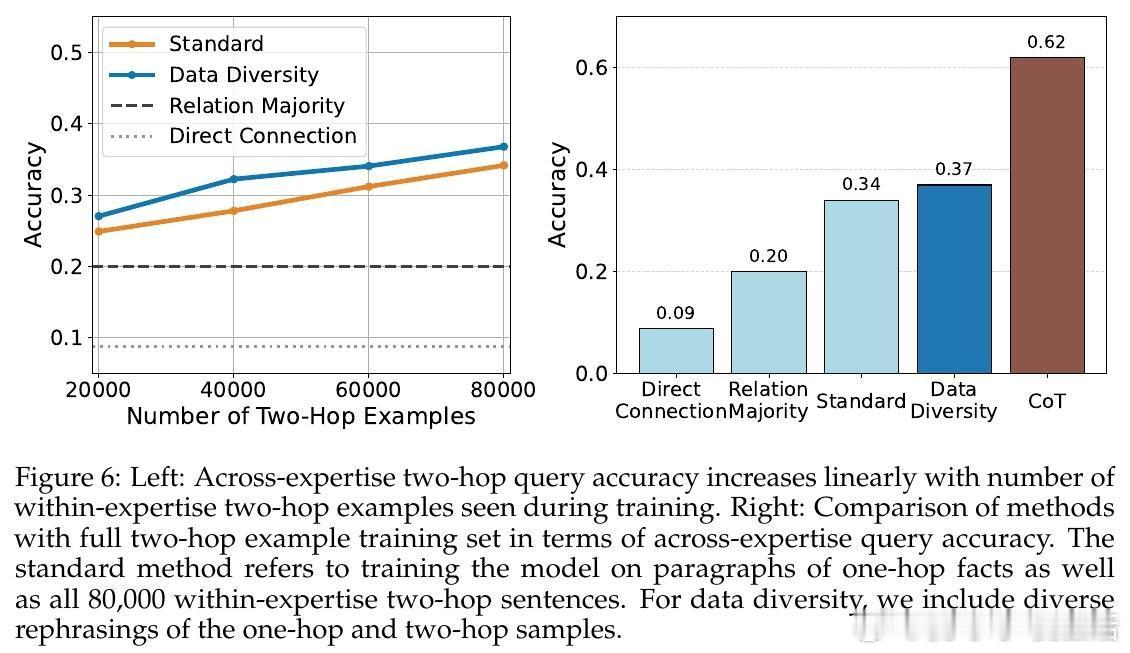
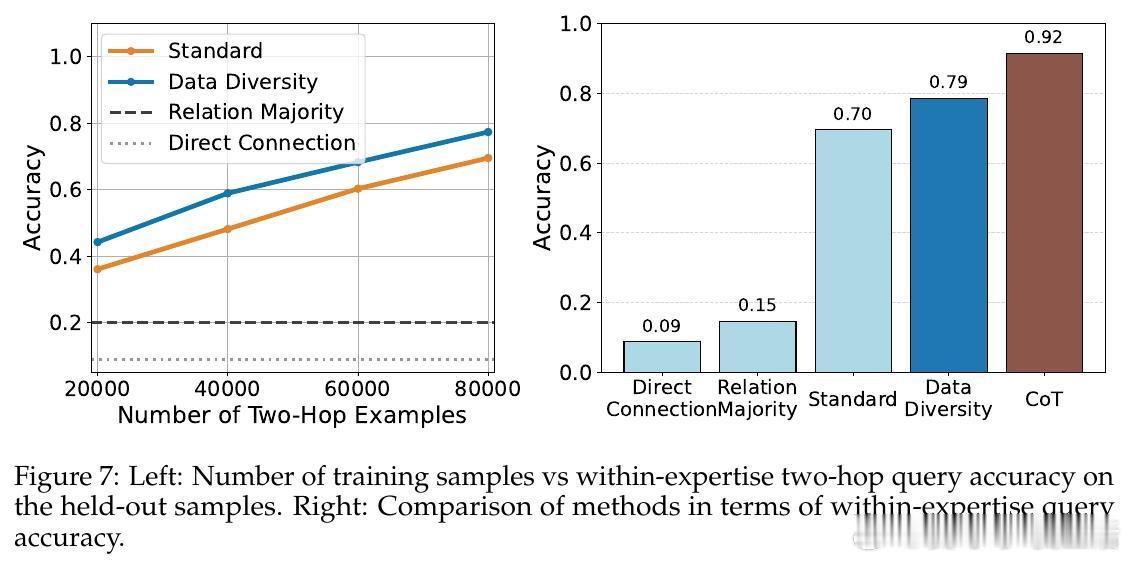
• 技能泛化:测试输入完全未知于任一专家,模型通过共享语义空间将多专家知识组合,完成跨领域、跨专家的推理与组合,体现模型的组合能力和简单性偏好。此模式挑战更大,依赖多样化训练示例和思维链(Chain-of-Thought)策略显著提升多跳推理表现。
• 实验基于合成知识图谱,专家知识分布经过聚类划分领域,训练数据由专家生成的带有一定正确率和错误的数据段组成,模型在GPT2和LLaMA3.2等架构上验证理论。
• 技能去噪中,专家数量和低温采样是提升性能关键;技能选择中,专家专注度参数α控制专家对本领域知识的贡献度,增大α提高准确率;技能泛化中,数据组合多样性与链式思维推理显著推动跨领域推断能力。
• 该研究为理解语言模型如何超越训练数据源提供了形式化框架,并强调了数据多样性、专家专长分布和模型结构对模型超越能力的决定性影响。
心得:
1. 多专家数据的异质性与错误独立性是模型性能超越单一专家的根本驱动力。
2. 专家专长的明确区分与模型对输入上下文的动态适配是提升泛化能力的关键。
3. 组合式推理能力依赖于模型的结构偏好与训练数据的复合多样性,链式思维显著促进复杂推理任务。
了解更多🔗 arxiv.org/abs/2508.17669
人工智能语言模型知识图谱多专家系统机器学习模型泛化