新解码系统让DeepSeek提速3倍大模型推理效率再提高
大模型的推理效率,迈向了一个新台阶。
明星初创公司Together AI发布了一种全新的推测解码系统,能提高大型语言模型(LLM)推理速度,同时降低成本。
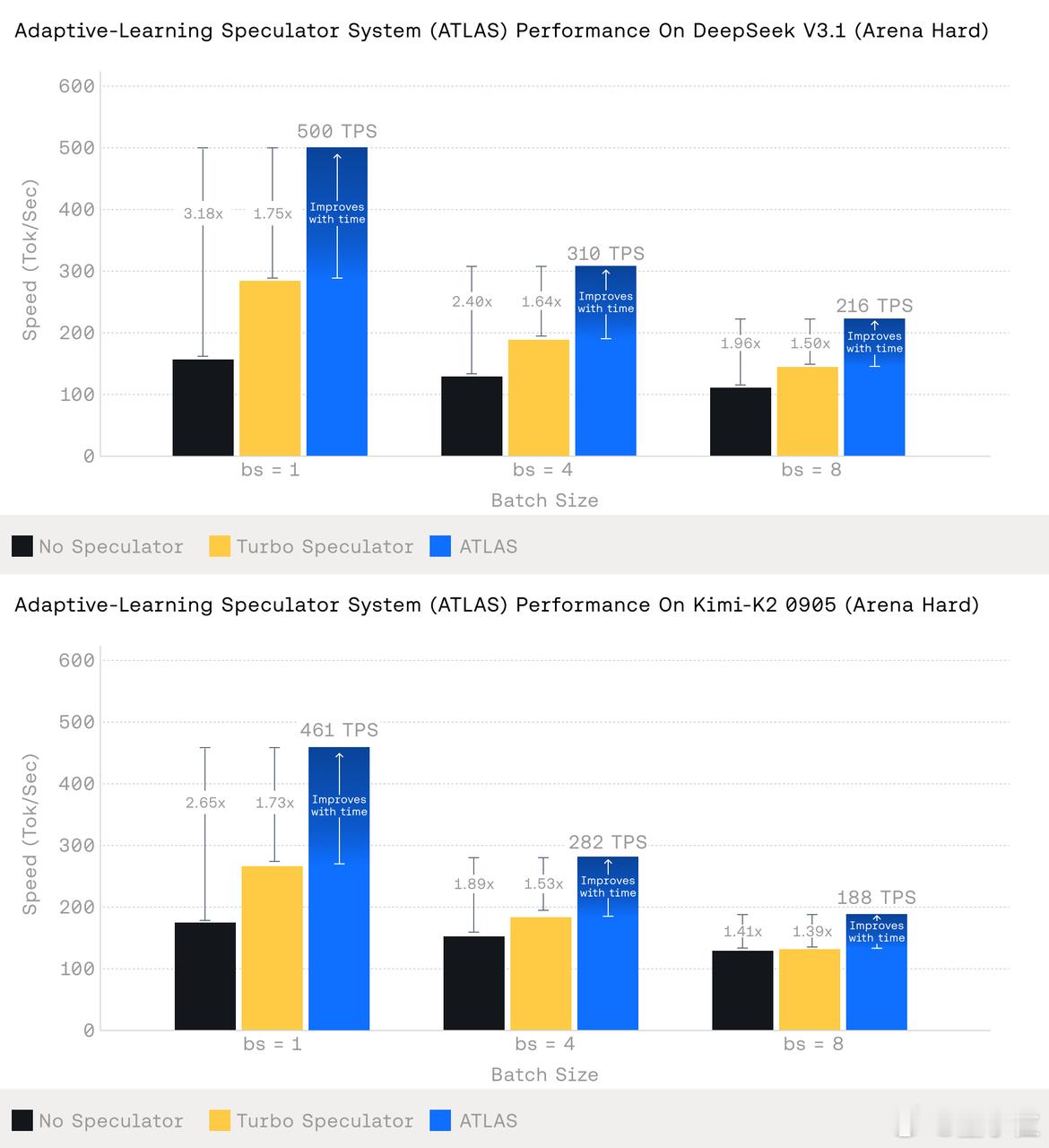
该系统名为AdapTive-LeArning Speculator System(ATLAS),具备动态自适应能力,可在运行时根据实时数据不断优化推理效果【图1】:
- 在 DeepSeek V3.1 上:ATLAS 在批量大小为 1 时的速度达到 500 TPS,比没有使用 speculator 快 3.18倍,比 Turbo Speculator 快 1.75倍。
- 在 Kimi-K2 0905 上:ATLAS 在批量大小为 1 时的速度达到 461 TPS,比没有使用 speculator 快 2.65倍,比 Turbo Speculator 快 1.73倍
ATLAS的核心优势在于其动态自适应能力,与以往的静态推测器或固定训练的定制推测器相比,ATLAS能通过实时学习历史和当前数据,不断适应模型的行为和变化需求。
以下是ATLAS的亮点与核心特性:
1. 动态推测解码:推测解码通过提前由“推测器”生成多个可能的下一步结果,随后由目标模型并行验证其正确性,从而显著提升推理速度。传统推测器通常基于固定的数据训练且无法适应流量与输入分布的变化,而ATLAS则可通过轻量级自适应推测器实现实时微调,并由信心控制器动态调整推测策略(如预测步数),确保速度与准确性的最佳平衡。
2. 双模式协作:
- 固定推测器:作为稳定的性能基线,利用广泛数据集训练,适用于多种工作负载。
- 自适应推测器:处理实时更新,通过低开销学习新流量特点,为特定领域优化推测效率。
2. 强化学习加速:ATLAS在强化学习(RL)训练中表现亮眼,通过动态对齐推测器与目标模型策略的分布,大幅降低生成阶段的时间开销。例如在RL-MATH任务中,ATLAS将采样接收率从10%提高至80%以上,总训练时间减少超过60%。
3. 多个优化层的联合效应:ATLAS与Together Turbo优化套件中的其他技术(如量化、稀疏性优化、自定义推测器等)协同工作,进一步释放LLM推理潜力。例如在NVIDIA HGX B200上,ATLAS将DeepSeek任务的推理速度从基础的105 TPS提升至501 TPS。
除此之外,ATLAS不仅适用于标准环境,还可快速适应狭窄且重复性高的输入分布,提高特定场景下的运行效率,最大化吞吐量。
Together AI表示,ATLAS的目标是让推理效率与模型智能性同步发展,为AI的广泛应用提供可持续的底层支持。
ATLAS现已整合至Together专属端点,感兴趣的机构与开发者可以通过了解更多。
感兴趣的小伙伴可以点击:www.together.ai/blog/adaptive-learning-speculator-system-atlas

![这Ai生成的比我拍的好看多了[笑着哭][笑着哭][笑着哭]](http://image.uczzd.cn/17506215209649934110.jpg?id=0)