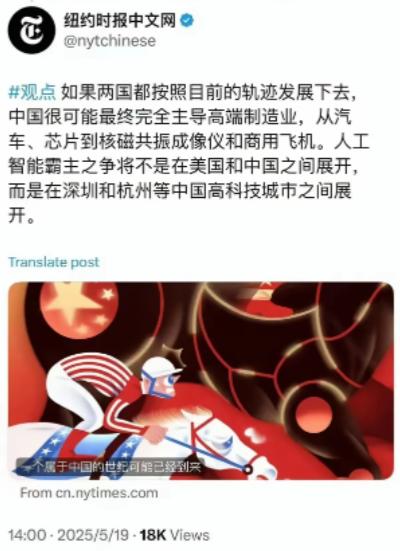
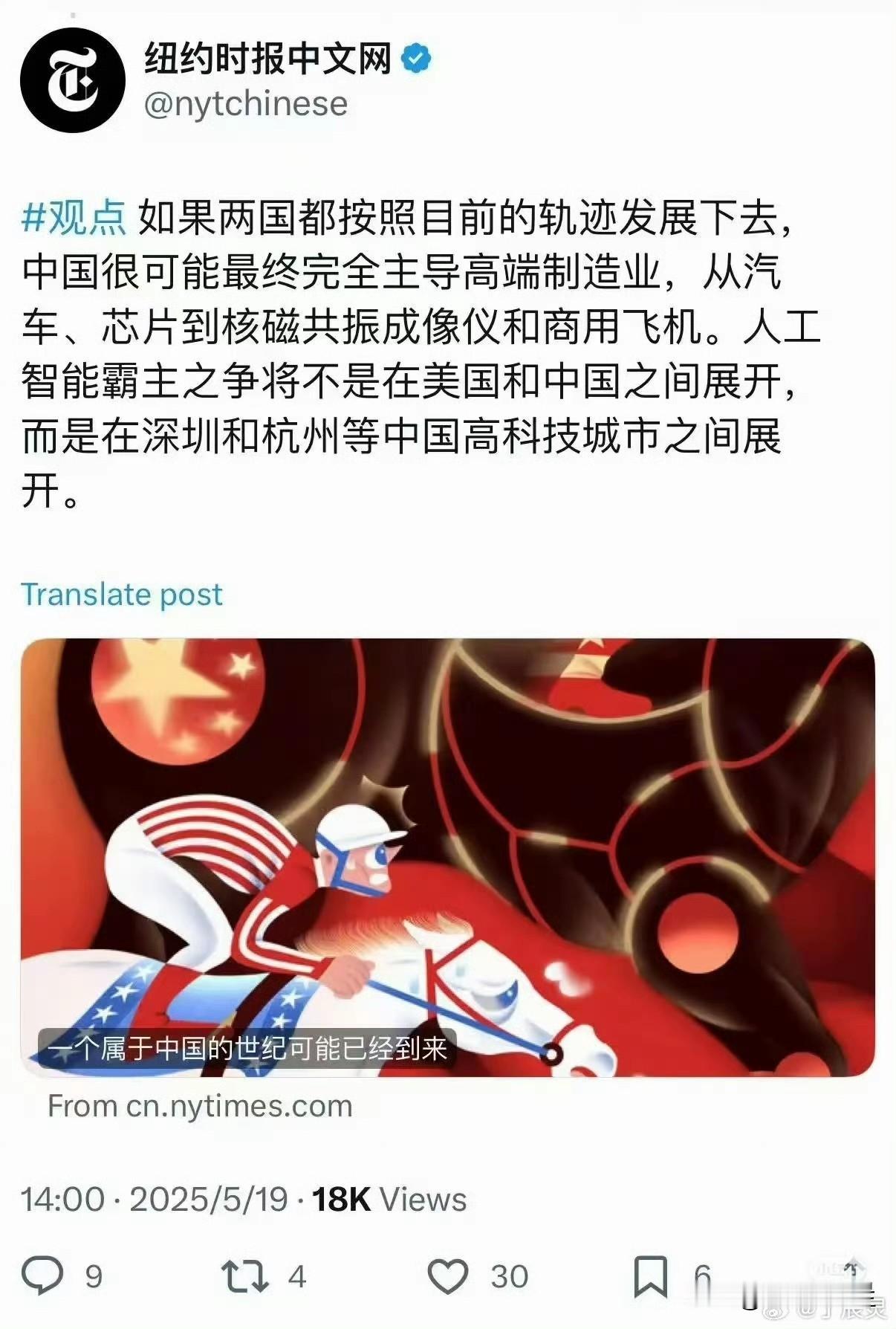
Open AI 前员工 Andrej Karpathy 最近在访谈中的一句话,可能会戳破 Open AI ,英伟达,甲骨文在打造的 AI 泡沫。[鼓掌]
他说,模型的权重,只是对 15万亿 token 的模糊回忆。而上下文窗口中的 token ,则是模型可以非常直接访问的。
这句话其实非常精确了,但是我再直白的解释,训练完成的模型,是对大规模训练数据的“压缩与概括”,能提炼出通用规律。而上下文窗口则是模型的“短期工作记忆”,可以被显式对齐、引用和操作。
进而他提出:“真正的核心认知,可能只需要 10 亿规模的模型”。
这句话其实就是在说,目前无限放大训练数据,模型规模,以及算力的方向可能错了。。。这就是之前所说的“规模法则撞墙”。有趣的是这些都是 Open AI “前”员工说的。。。
模型需要学会的是真正重要的“核心知识”。有了这个模型,其他都应该是根据具体任务和更完整准确的上下文对核心知识的运用。
10 亿说实话,在我这个外行看可能都激进了。。。因为除了“核心知识”,其实拥有更多各行各业的“常识”其实也很重要。不过就算是 100亿,也比今天 Open AI 们号称的规模要小很多了。。。
简单说,这是一个真正理解模型的技术人员,对模型未来演进方向和通向 AGI 道路的纯粹的探索。
他和那些聚光灯下操纵万亿美金的人所说的,完全不一样。。。[黑线]
而在 IT 行业,一个基本事实是,其实后面一种人,并不掌握技术。。。jobs 不会写嵌入式也不会工业设计。扎克伯格能写点代码,但是现在估计也通过不了 meta 的面试。。。
Andrej Karpathy 不一定是对的。
但是的确描述了一个 Open AI ,甲骨文,英伟达这些科技巨头和万亿美金都错了的可能性。
就像 Open AI 证明了 Google,Facebook,苹果都错了一样。[嘻嘻]
xxxxxxx
Grok 总结的访谈 summary :



![最火ai排名,你平常用哪个[思考]](http://image.uczzd.cn/13567813052405002715.jpg?id=0)