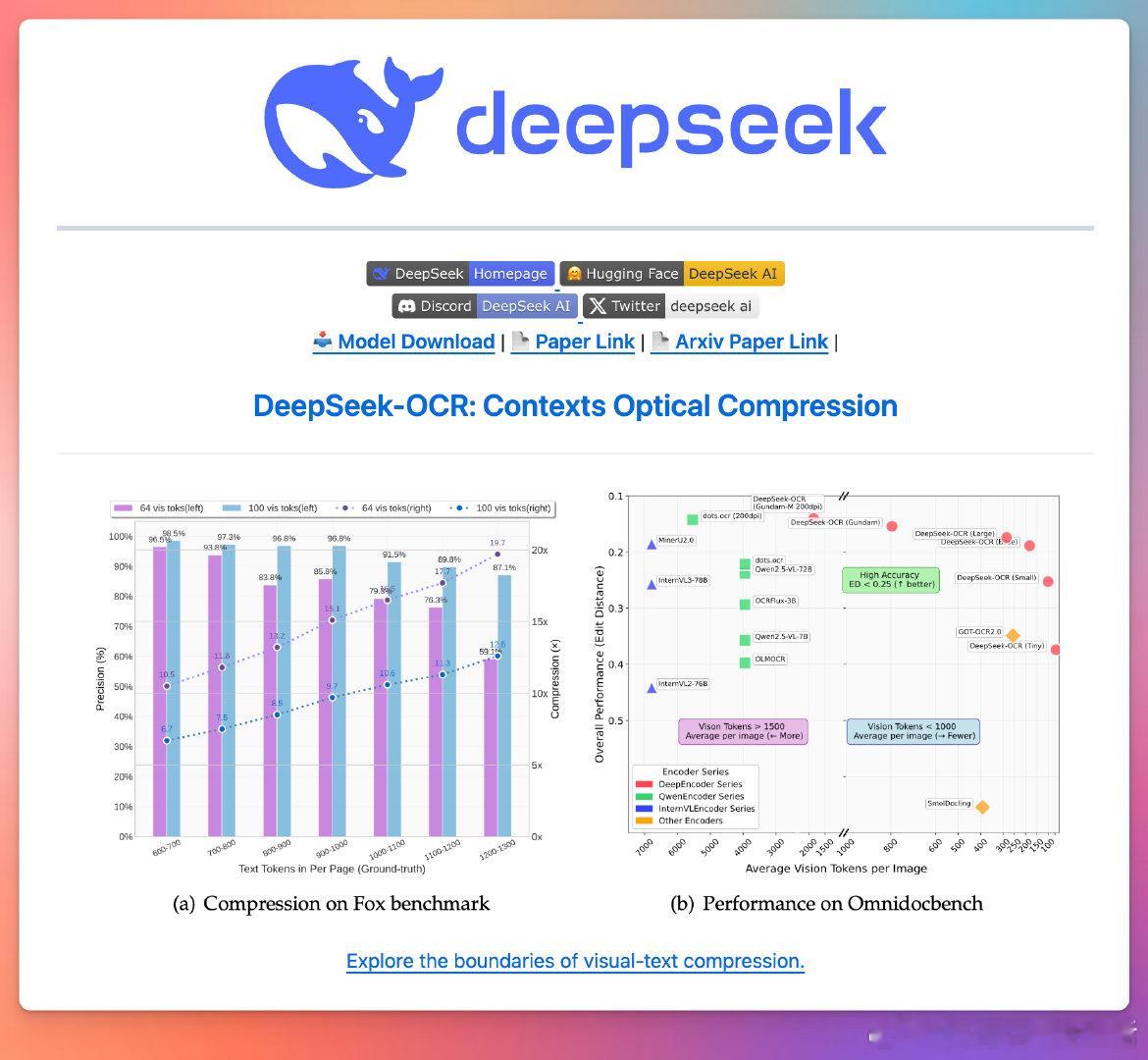
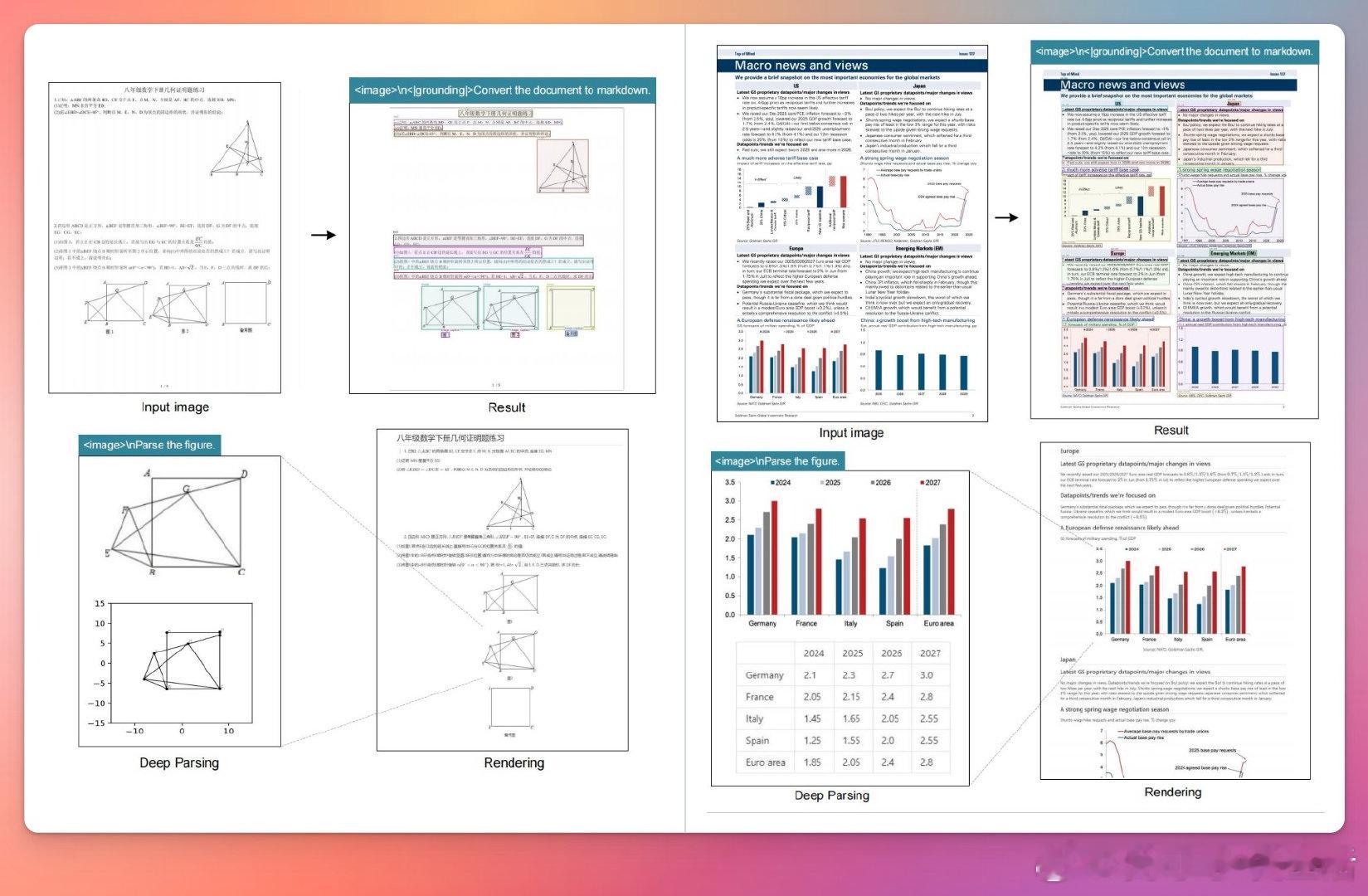
在视觉与文本压缩领域,DeepSeek-OCR 推出了开源模型,专注于从大语言模型视角解析视觉编码器的作用。它支持多种分辨率模式,从512×512到1280×1280,能够实现高效的图像OCR和文档转换,适合需要高质量视觉文本识别与压缩的开发者和研究者使用。
功能亮点包括:
- 支持多种视觉输入分辨率和动态分辨率模式;
- 与 vLLM 和 Transformers 双推理框架兼容,灵活方便;
- 支持图像到Markdown的文档转换,以及多样化的OCR应用场景;
- 提供详细的命令行和Python使用示例,便于快速上手;
- 基于 MIT 许可证开源,便于集成和二次开发。
项目地址:
github.com/deepseek-ai/DeepSeek-OCR
适合视觉文本理解、文档数字化、智能文档处理等领域的技术人员和团队使用。