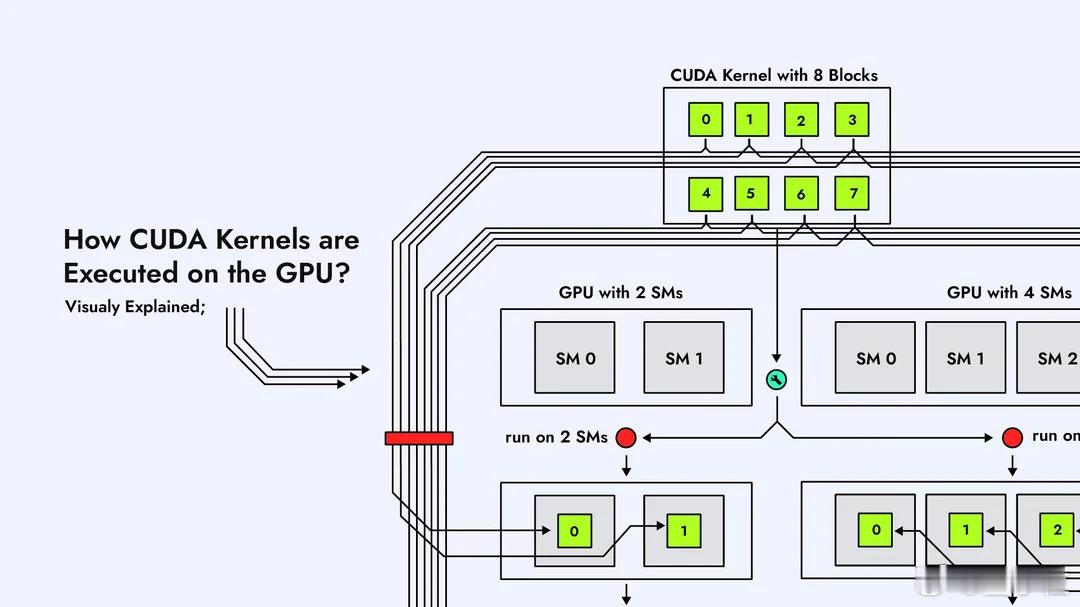
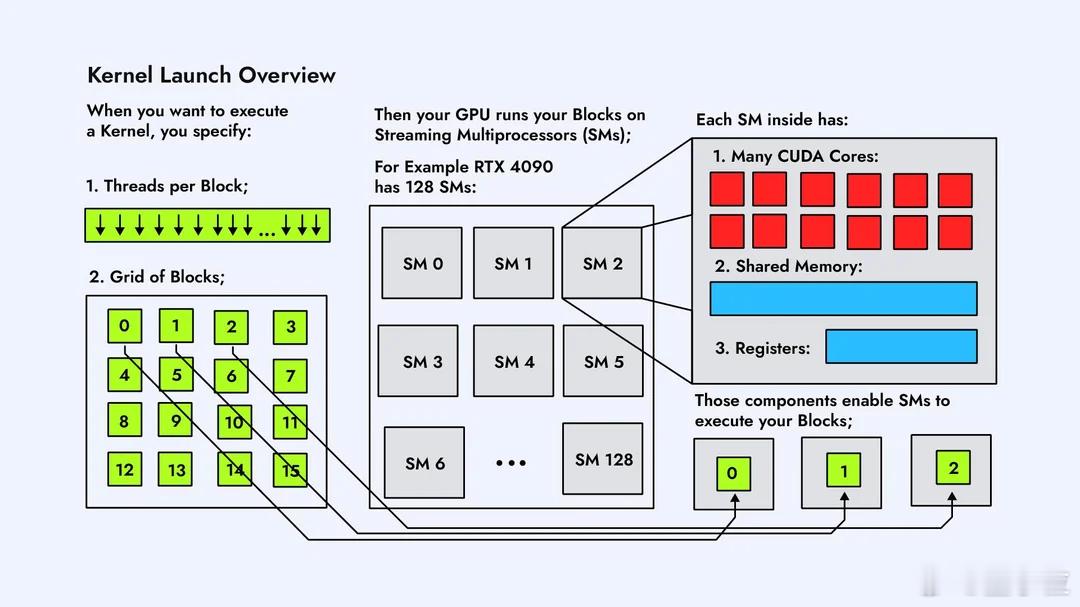
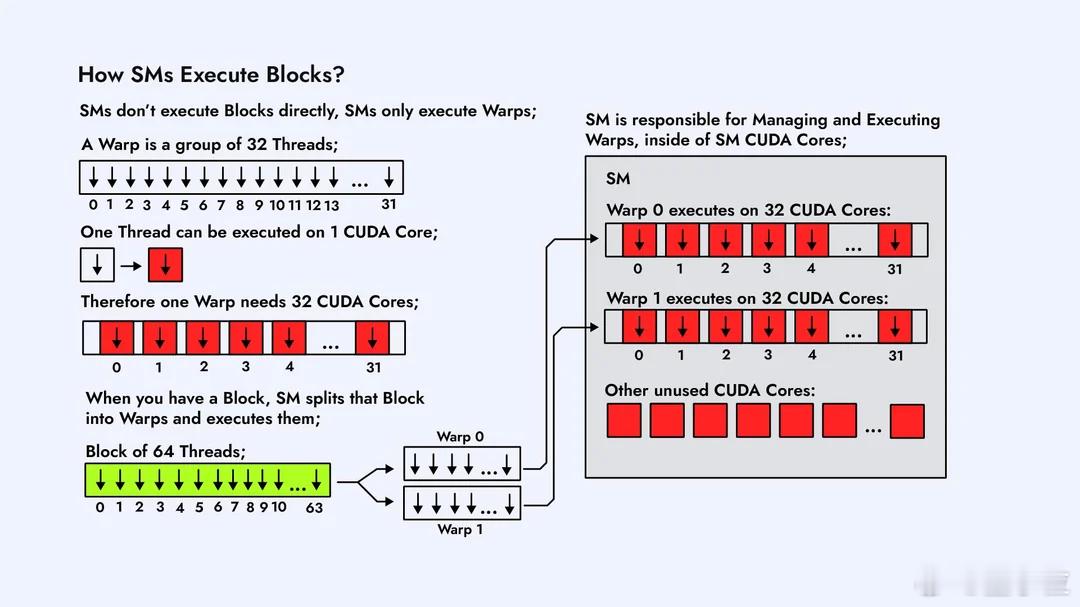
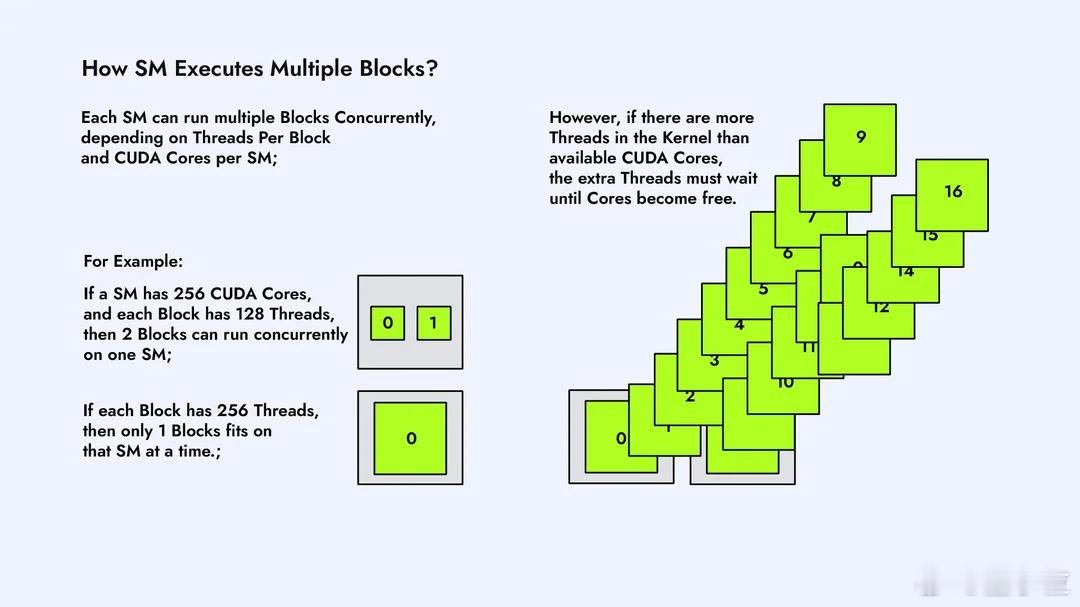
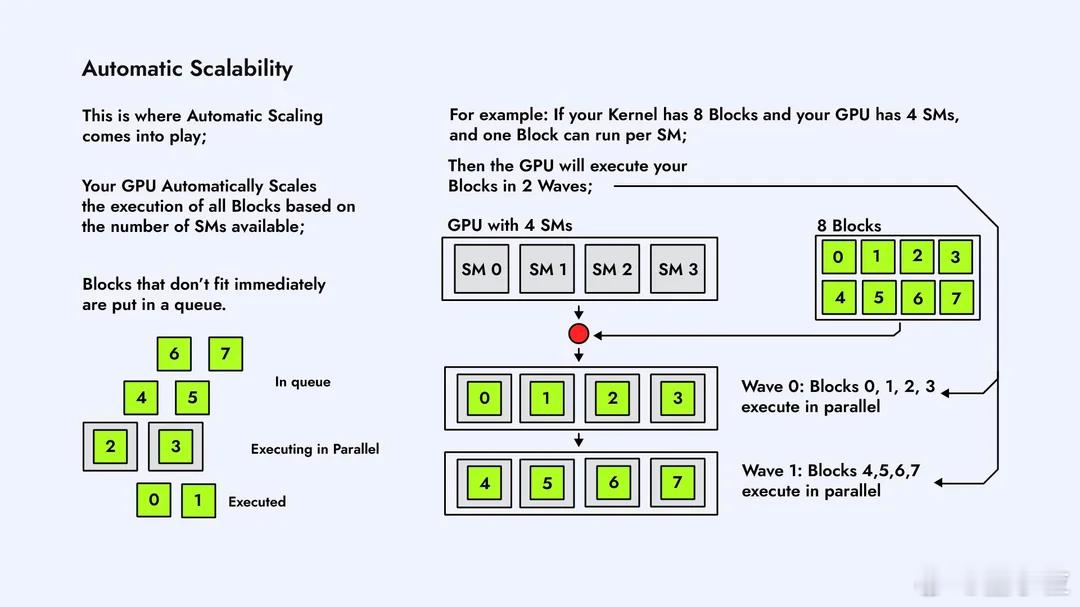
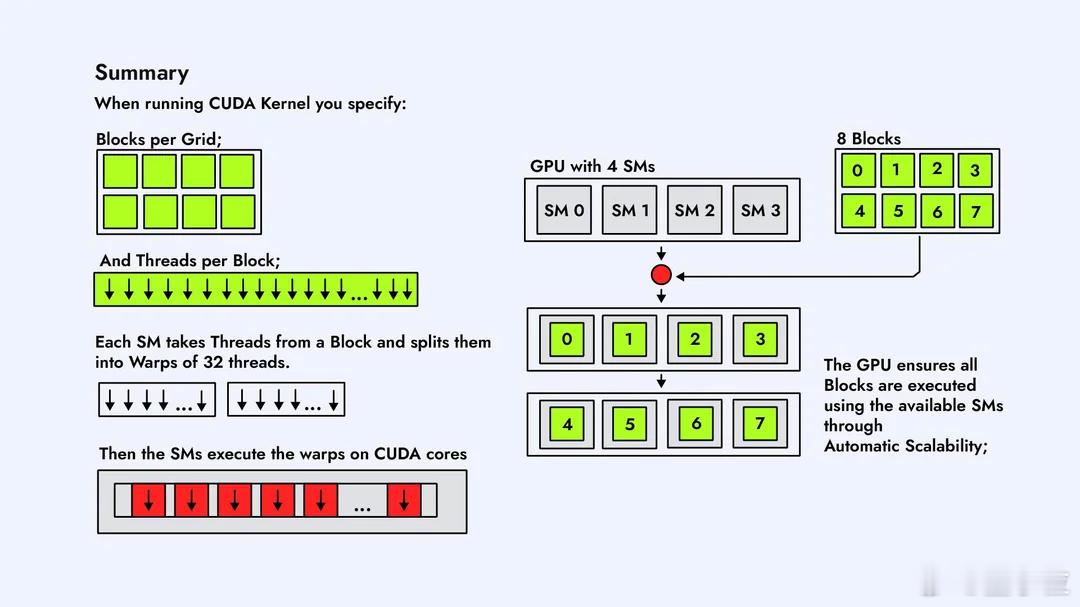
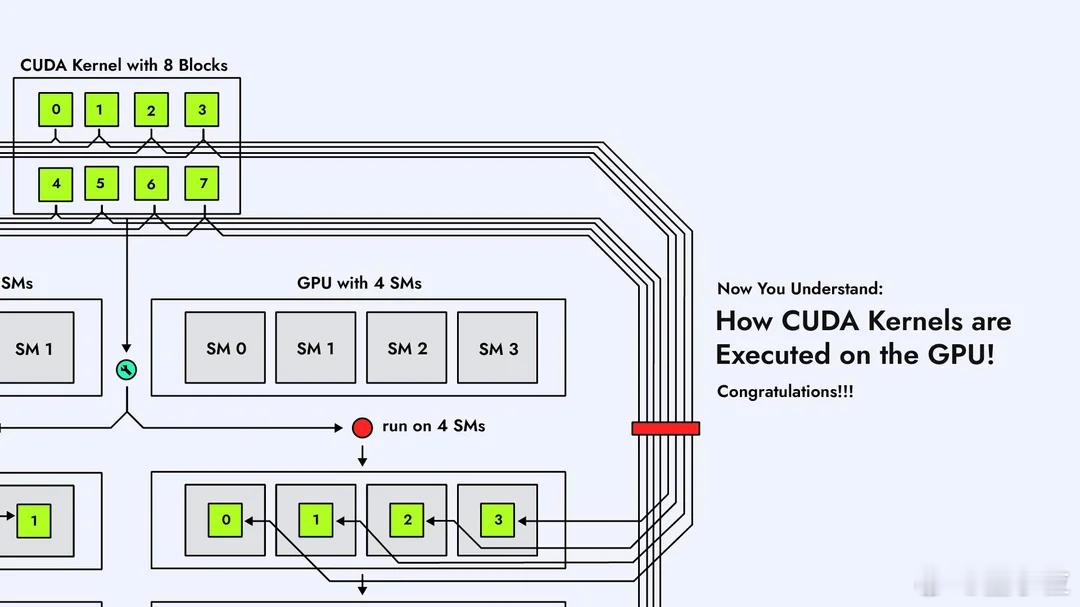
CUDA内核在GPU上是怎么执行的?Reddit大神这组图片,不懂CUDA的人看了也能有直观概念。【图1】在GPU上跑一个CUDA Kernel,第一步是把任务拆成一个大的线程网格Grid,里面塞满一个个Block。这个Grid就是“要完成的全部工作量”,Block就是被分成的小任务。【图2】GPU内部有很多个SM(Streaming Multiprocessor),它们是负责运算的“小机器”。每个Block会被自动分配到某个SM上去跑,一个SM一次能接多少Block,要看它的硬件资源。【图3】Block不会直接跑,到了SM里会再被切成一个个Warp。Warp由32条线程组成,是GPU真正调度的单位。可以理解为:Block是任务包,Warp才是上机干活的小队。【图4】一个Warp的32条线程,会被塞进SM内部的CUDA Core里执行。Core数量够,Warp就能一次性跑完;Core不够,多出来的Warp就只能排队等位置。【图5】SM里有Warp调度器,它决定哪个Warp先跑、哪个先停。并不是所有Warp一起执行,而是调度器轮流“点名”。所以GPU高速,但也是有节奏的。【图6】如果Grid里的Block数量比SM数量多,就会出现“排队”。SM忙不过来,多出来的Block会先放在队列里,等前面的跑完再补上,这个过程完全自动。【图7】不同Block之间怎么调度、什么时候上SM,不需要开发者操心,GPU会自己做资源分配。我们只需要告诉它Block和线程数量,剩下就是GPU的事。【图8】 最后一张是整个执行流程的总结:Grid → Block → Warp → Thread,再到SM和CUDA Core。所有Block都会被GPU按SM数量分批跑完,实现自动扩展和并行。总体来看,这组图讲的很清楚了,如果后续再加一套图,把共享内存访问、L1/L2缓存、bank conflict这些讲清楚,会更接近真正的CUDA性能优化流程。原图地址:www.reddit.com/r/CUDA/comments/1ofvfpe/how_cuda_kernels_are_executed_on_the_gpu/