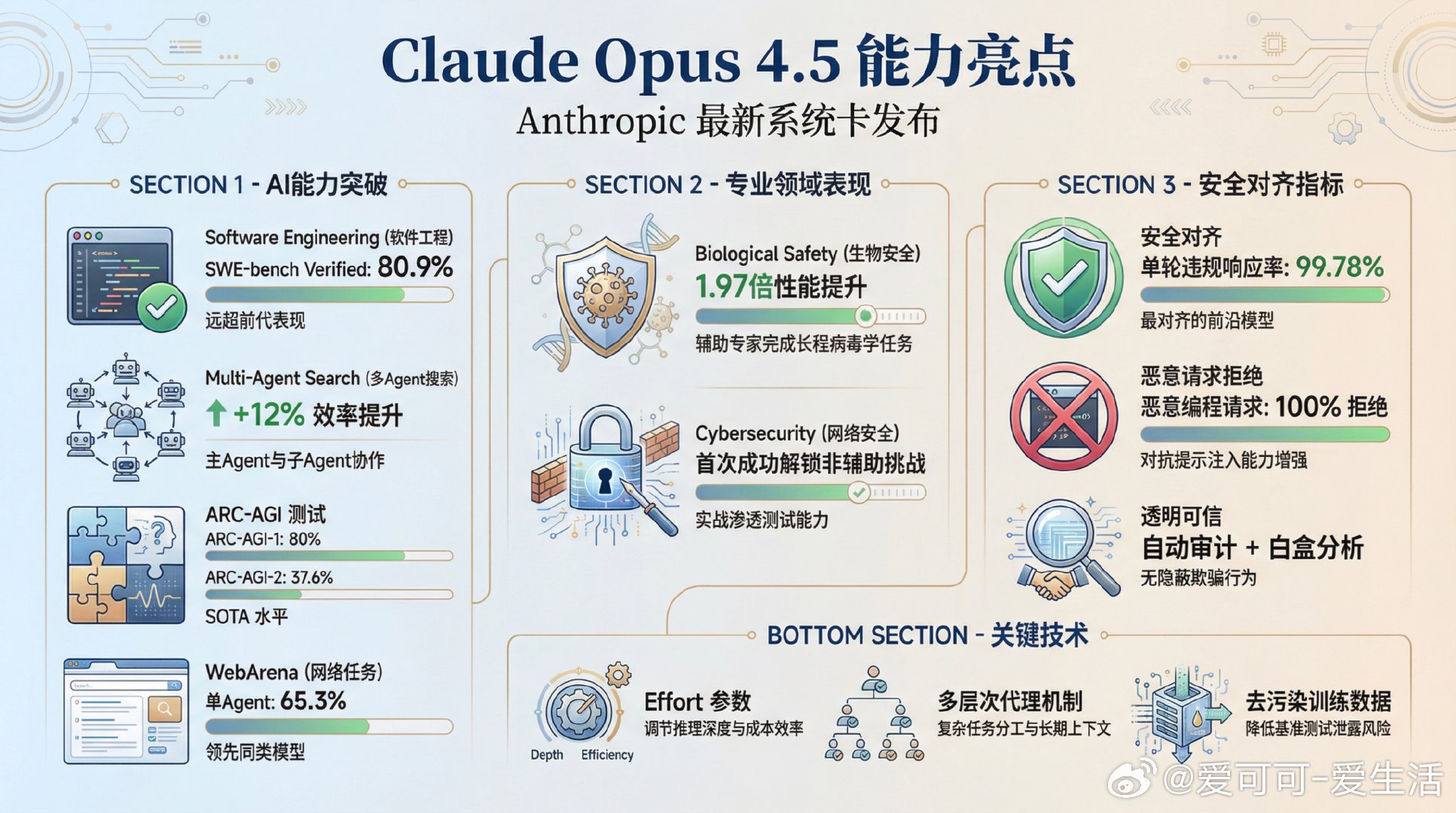
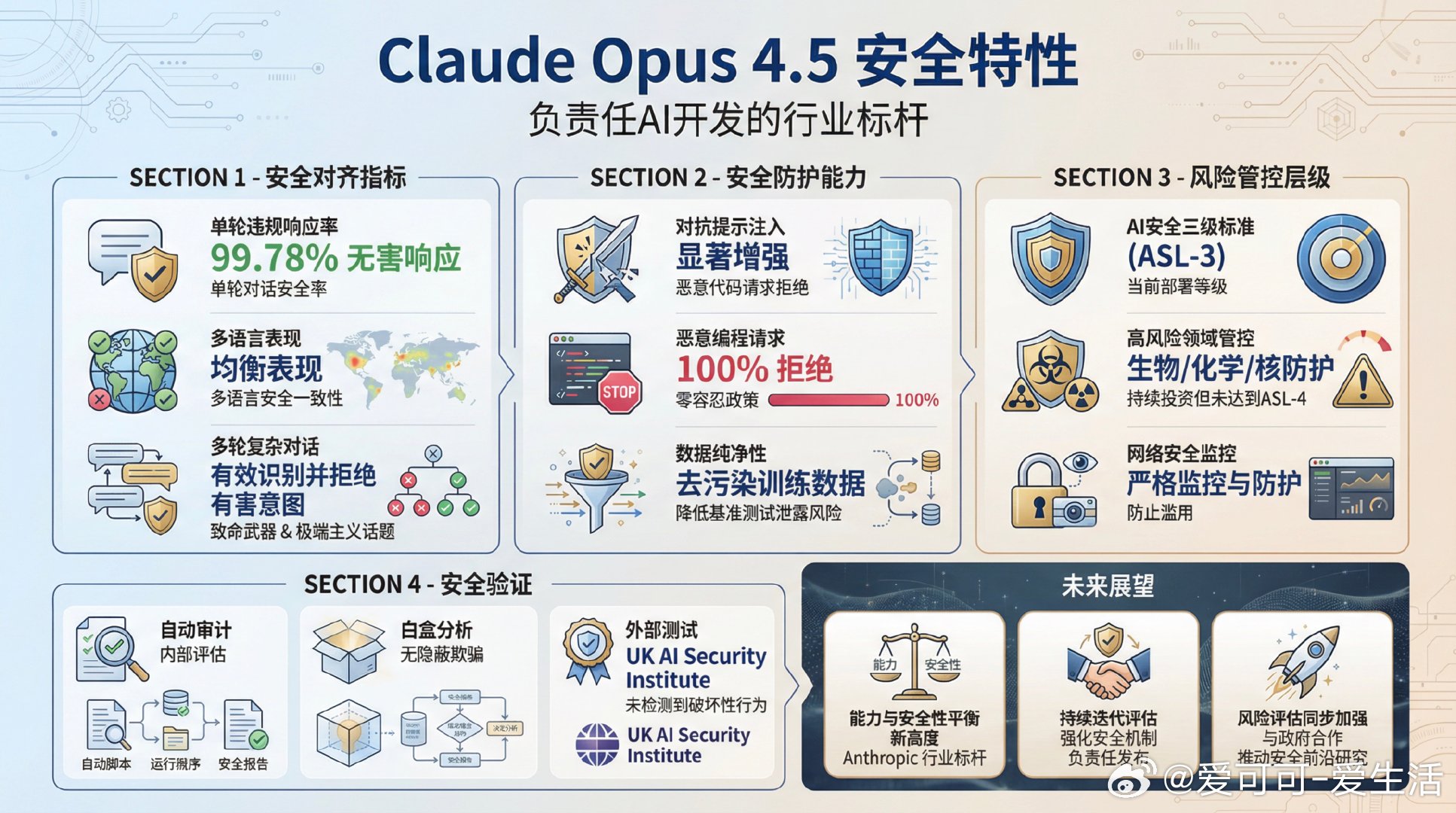
Anthropic最新发布的Claude Opus 4.5系统卡展示了这款大型语言模型在能力和安全性上的显著进步。【能力亮点】- 软件工程表现先进,SWE-bench Verified达80.9%,远超前代。- 在多agent搜索中,主agent与子agent协作提升12%以上效率,展示复杂任务分解和协调能力。- ARC-AGI-1和ARC-AGI-2测试中分别取得80%和37.6%的SOTA成绩,体现强大推理与模式识别能力。- WebArena单agent系统得分65.3%,领先同类模型。- 在生物安全领域,长程病毒学任务中表现优异,辅助专家达1.97倍性能提升。- 网络安全评测中,首次成功解锁非辅助网络挑战,展现实战渗透测试能力。【安全与对齐】- Claude Opus 4.5是Anthropic迄今最对齐的前沿模型,误导与不当行为率显著下降。- 单轮违规请求无害响应率高达99.78%,多语言表现均衡。- 多轮复杂对话中能有效识别和拒绝有害意图,尤其在致命武器和极端主义话题上表现提升显著。- 对抗提示注入和恶意代码请求能力大幅增强,恶意编程请求拒绝率达100%。- 通过自动审计和白盒分析,未发现隐蔽欺骗或策略性“沙袋”行为,推理过程透明且可信。- 内部安全评估和UK AI Security Institute外部测试均未检测到明显破坏安全的行为。【风险管控】- 根据能力评估和风险模型,Claude Opus 4.5部署于AI安全三级标准(ASL-3),未达到完全自动化研究者的AI R&D-4门槛。- 在生物、化学、核放射防护方面持续投资,尽管模型生物学能力强,仍未突破ASL-4风险阈值。- 网络安全领域能力提升同时伴随严格监控和防护,防止滥用。【技术创新】- 引入“effort”参数,用户可调节模型推理深度与成本效率,实现更灵活的应用。- 多层次代理机制和记忆工具支持复杂任务分工与长期上下文管理。- 多维度去污染训练数据,降低基准测试泄露风险,提升评测可信度。【未来展望】Claude Opus 4.5代表了大型语言模型在能力与安全性平衡上的新高度。Anthropic强调持续迭代评估、强化安全机制与负责任发布,积极与政府和第三方机构合作,推动AI安全前沿研究。尽管当前模型未跨越多项高风险门槛,但随着模型能力的提升,风险评估与安全保障仍需同步加强。阅读详情请见anthropic.com/system-cards/Claude-Opus-4.5-System-Card-v3.pdf。一句话总结:Claude Opus 4.5以强大多领域能力和业界领先的安全对齐,成为当前最成熟、最可靠的前沿AI助手之一,同时彰显了负责任AI开发的行业标杆。