[CL]《Can LLMs Reason Over Non-Text Modalities in a Training-Free Manner? A Case Study with In-Context Representation Learning》T Zhang, W Fang, J Woo, P Latawa... [Nanyang Technological University & MIT] (2025)
训练零成本让LLM理解非文本模态,开辟多模态推理新路径
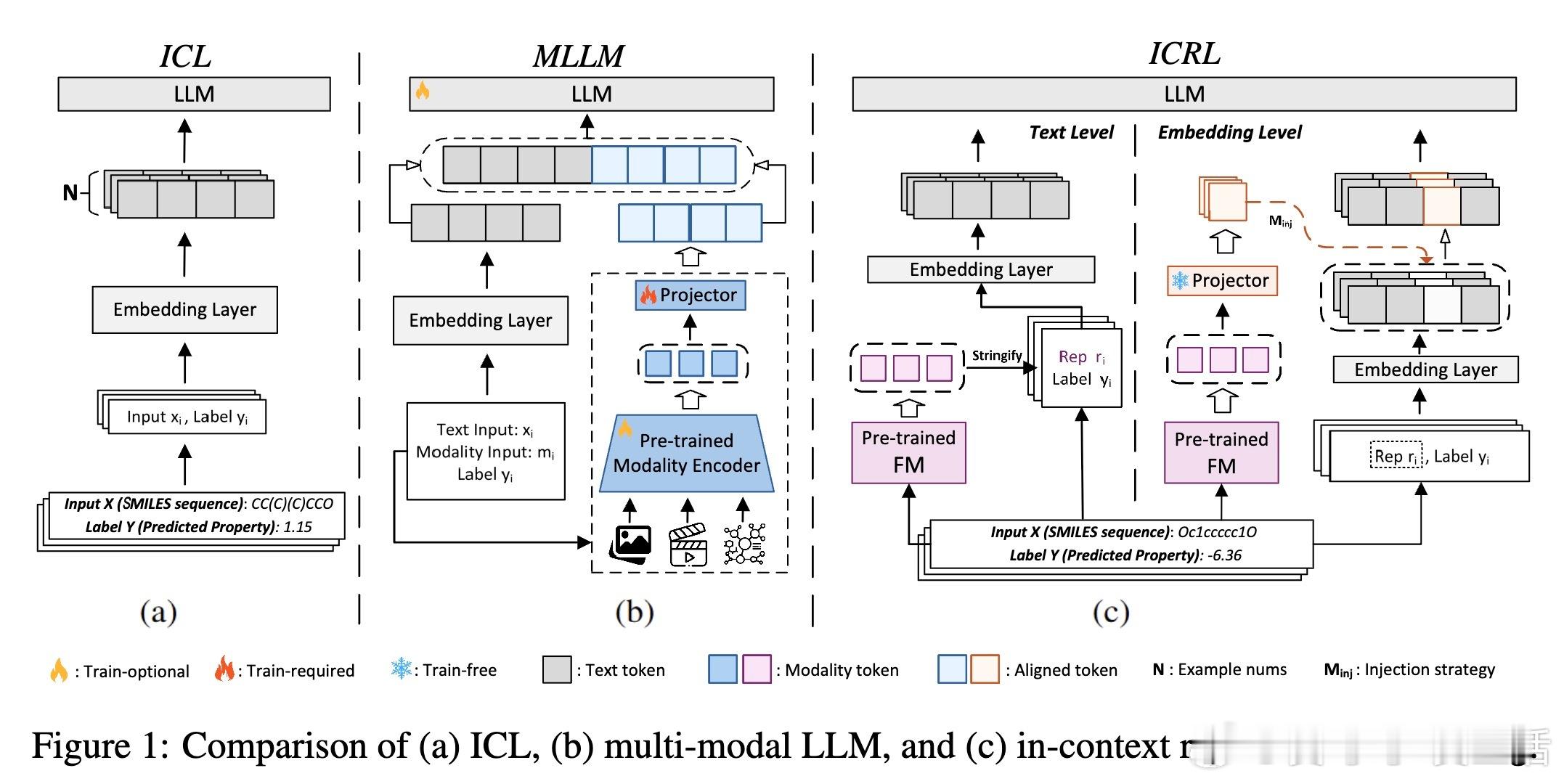
• 提出In-Context Representation Learning(ICRL),首次实现无需额外训练,直接将非文本Foundation Models(FM)嵌入文本LLM上下文,支持少样本学习。
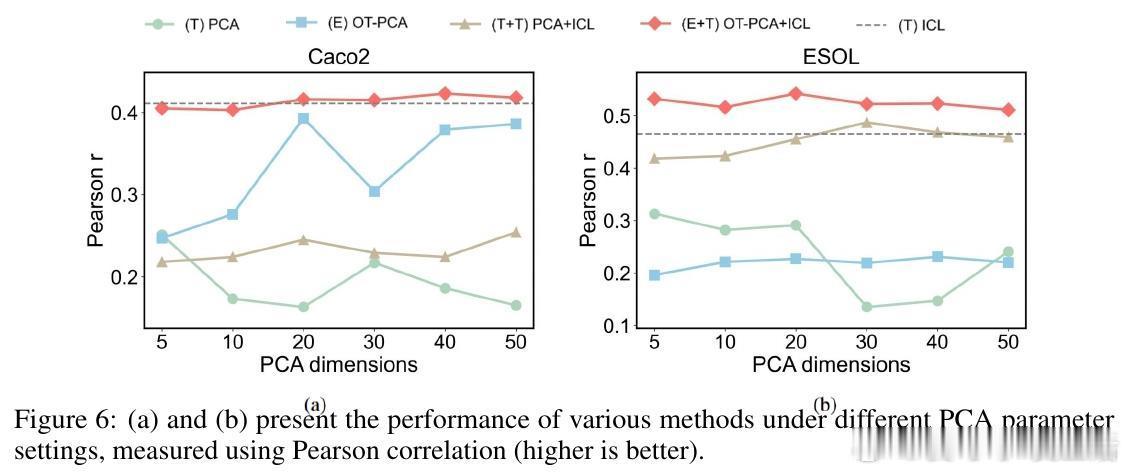
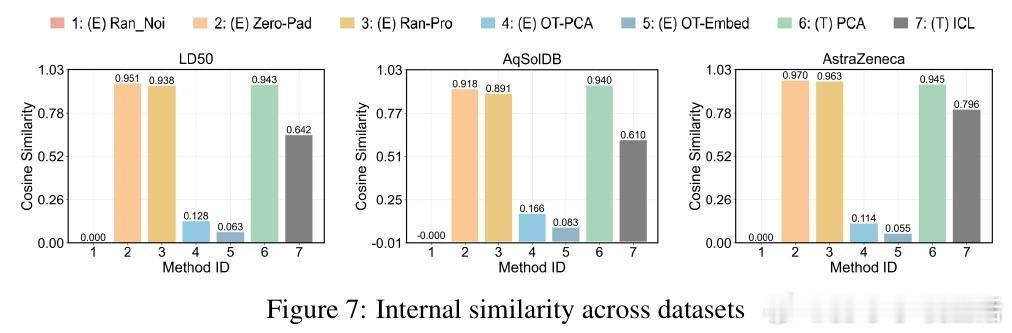
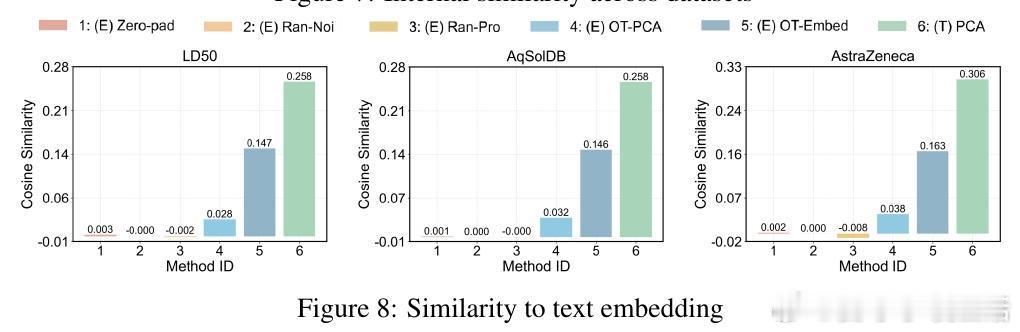
• 两种注入策略:文本级注入(PCA降维为字符串嵌入上下文)与嵌入级注入(零填充、随机投影、基于最优传输OT的分布对齐),其中OT对齐显著提升性能。
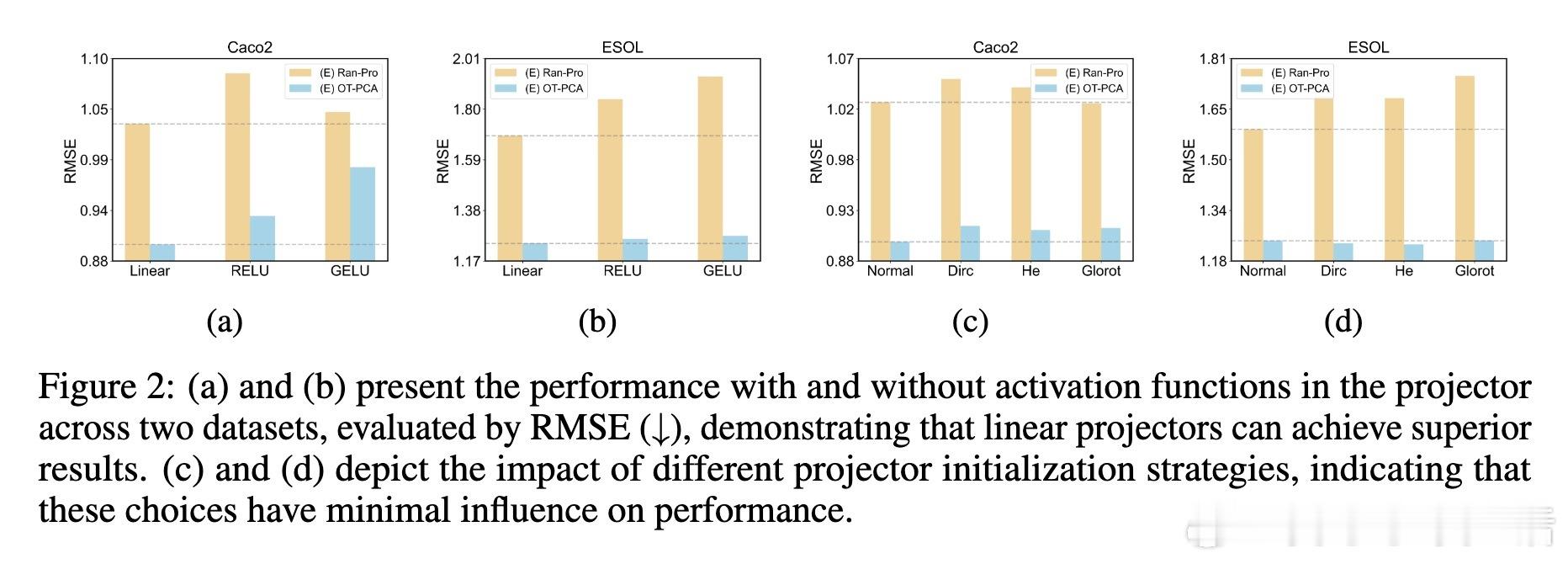
• 理论证明线性随机映射能高概率保留向量范数和余弦相似度,避免非线性激活导致的角度膨胀,指导投影器设计。
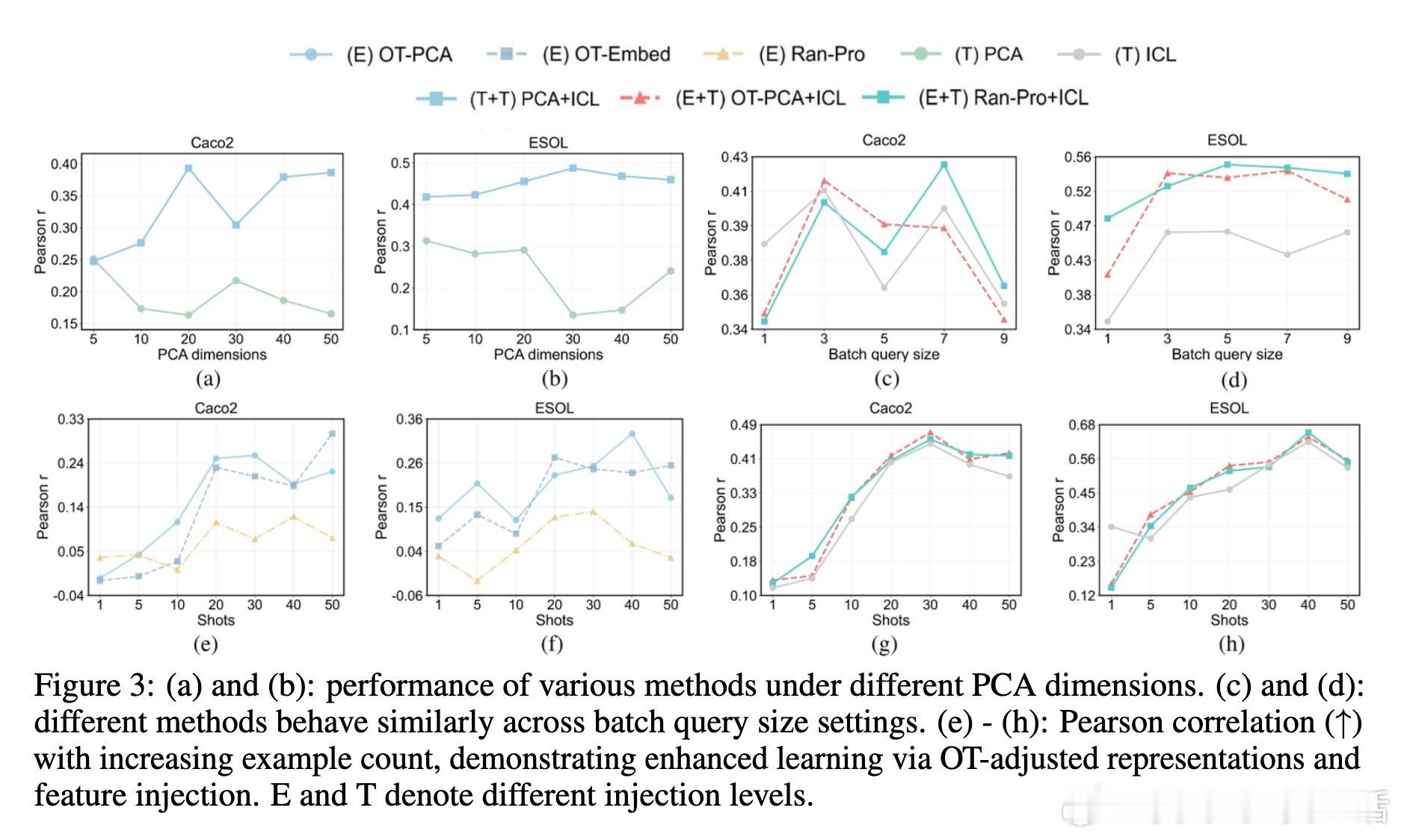
• 大规模分子性质预测、多模态视觉及音频任务验证ICRL有效性,尤其在上下文资源有限和小模型环境下表现优异。
• 与传统监督微调相比,ICRL耗时仅数秒,无需GPU,具备极高的效率和适应性,适用于资源受限场景。
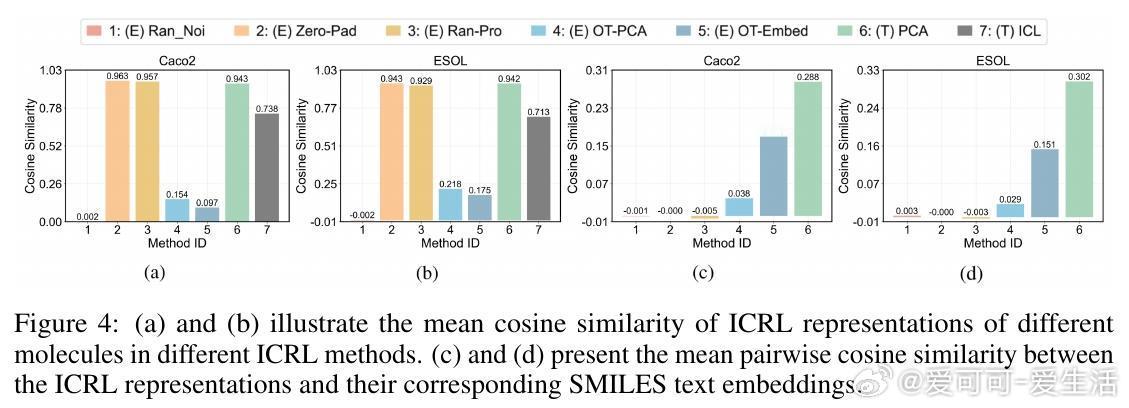
• 深入分析表明,ICRL性能依赖于投影后表示的多样性及与文本嵌入空间的对齐度,过高的表示相似度反而抑制模型区分能力。
• 发现ICRL在纯表示输入时工作于“任务学习”模式,而文本+表示混合时转为“任务检索”模式,揭示内部推理机制差异。
心得:
1. 训练自由并非等同于性能牺牲,巧妙的表示对齐和注入策略能实现高效多模态推理。
2. 表示多样性与对齐平衡是提升非文本信息利用的关键,不同模态间的通用规律为跨领域泛化奠基。
3. ICRL框架为未来无监督跨模态集成提供范式,特别适合领域专用Foundation Models与通用LLM的协同。
详情🔗 arxiv.org/abs/2509.17552
大型语言模型多模态无监督学习表示学习最优传输分子机器学习