[LG]《APRIL: Active Partial Rollouts in Reinforcement Learning to tame long-tail generation》Y Zhou, J Li, Y Su, G Ramesh... [Advanced Micro Devices, Inc. (AMD) & CMU] (2025)
APRIL:突破强化学习中长尾生成瓶颈的主动部分Rollout机制
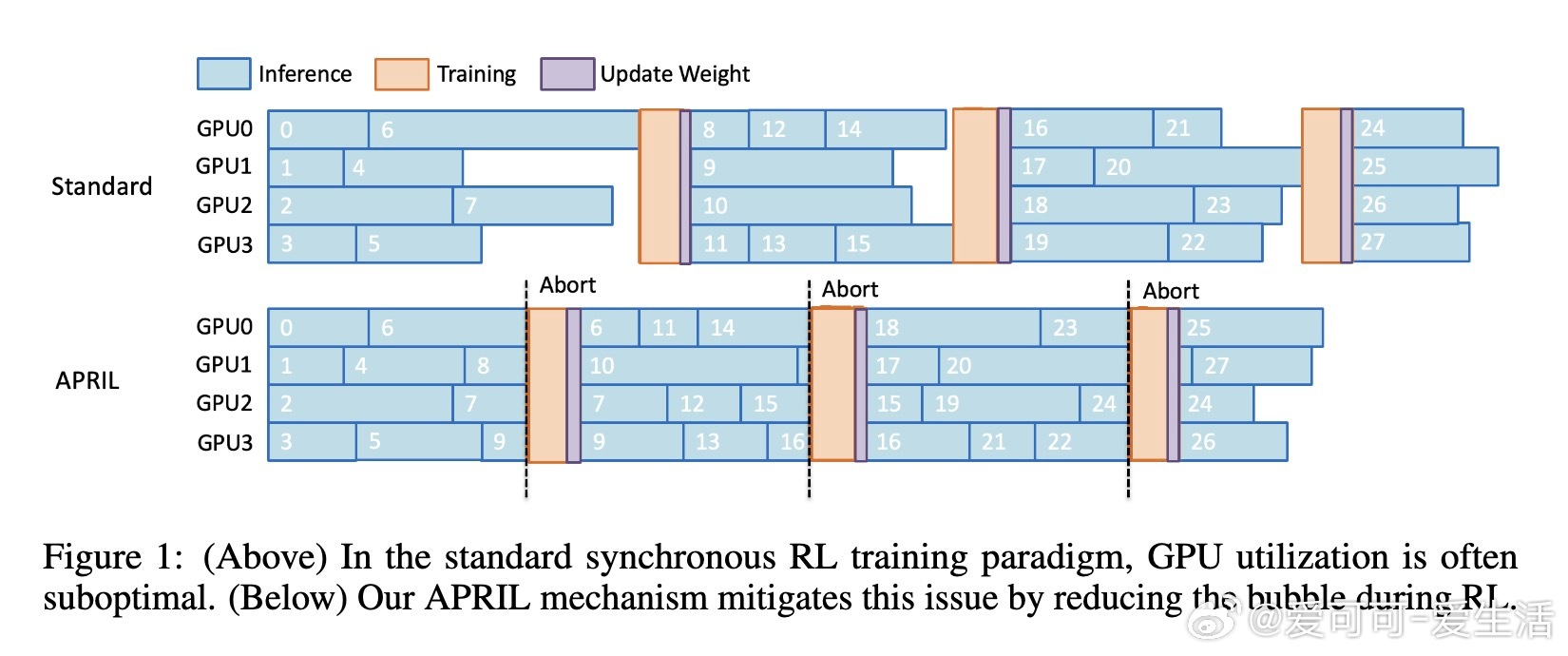
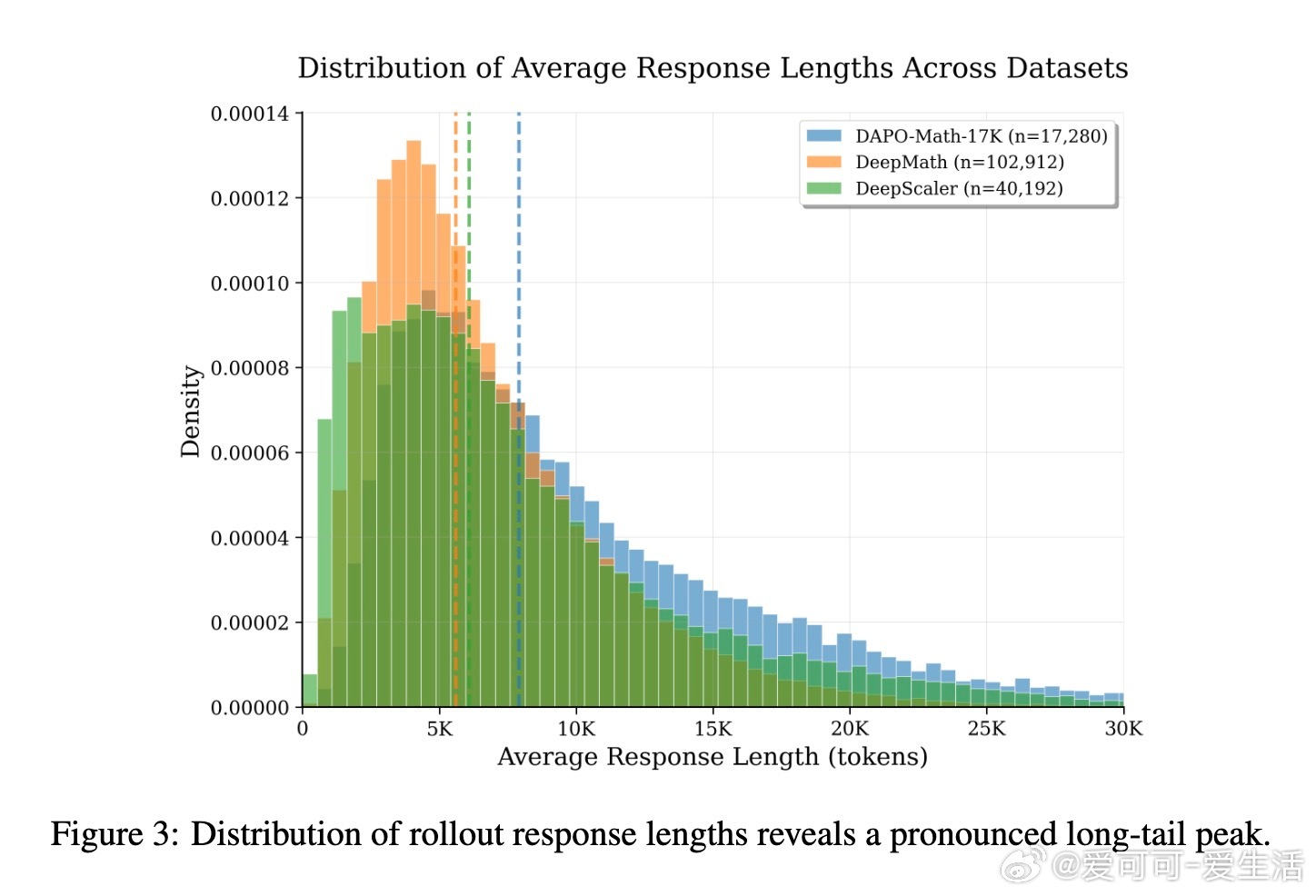
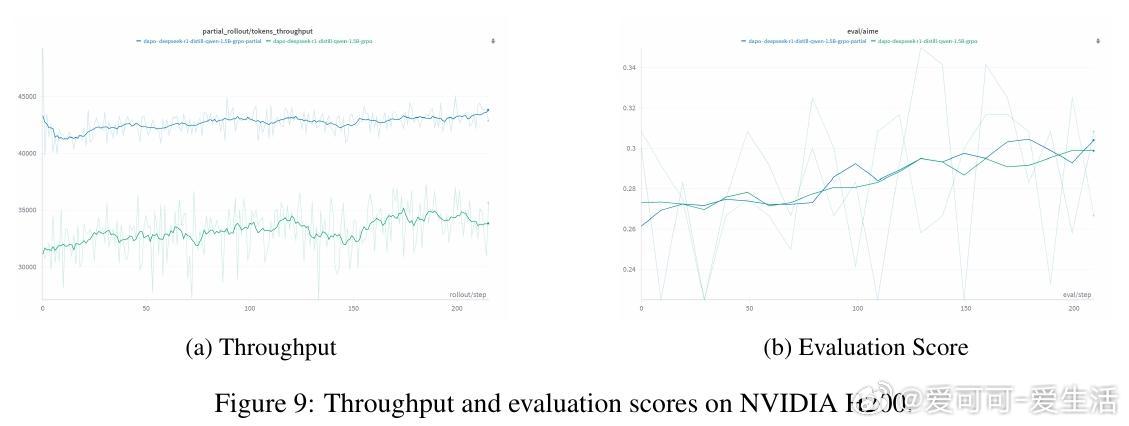
• 强化学习训练中,rollout生成占总时长90%以上,且响应长度呈长尾分布,少数长序列拖慢整个批次,导致GPU大量空闲,效率低下。
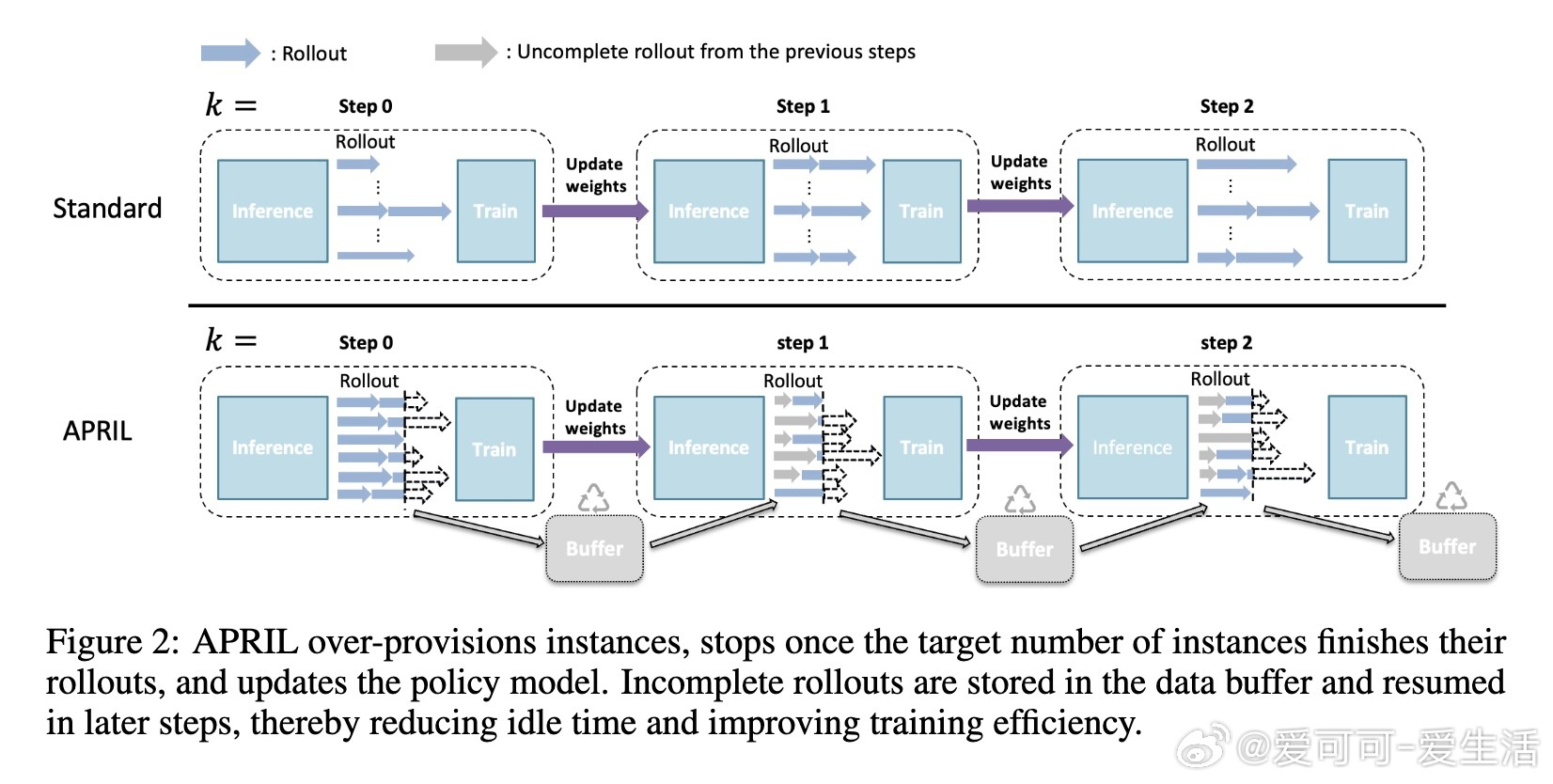
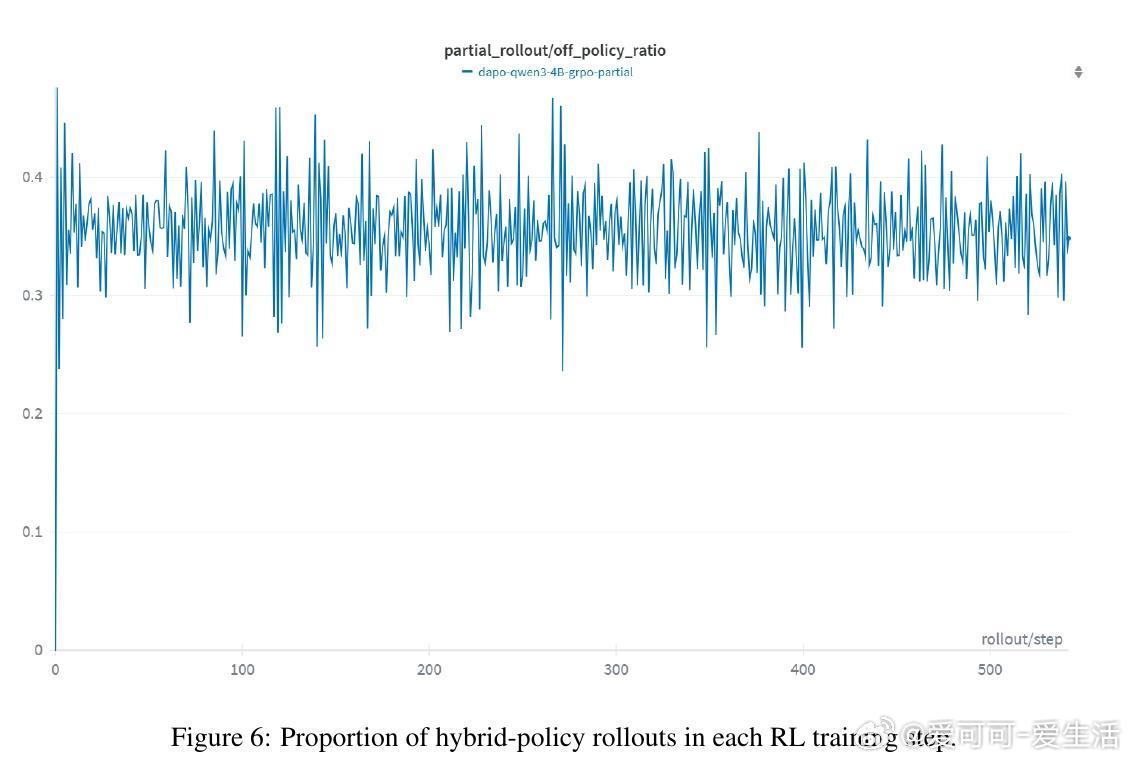
• APRIL通过过量请求rollout,达到目标数量即提前终止剩余生成,未完成的序列缓冲并在后续迭代续写,避免丢弃数据,有效减少GPU空闲时间。
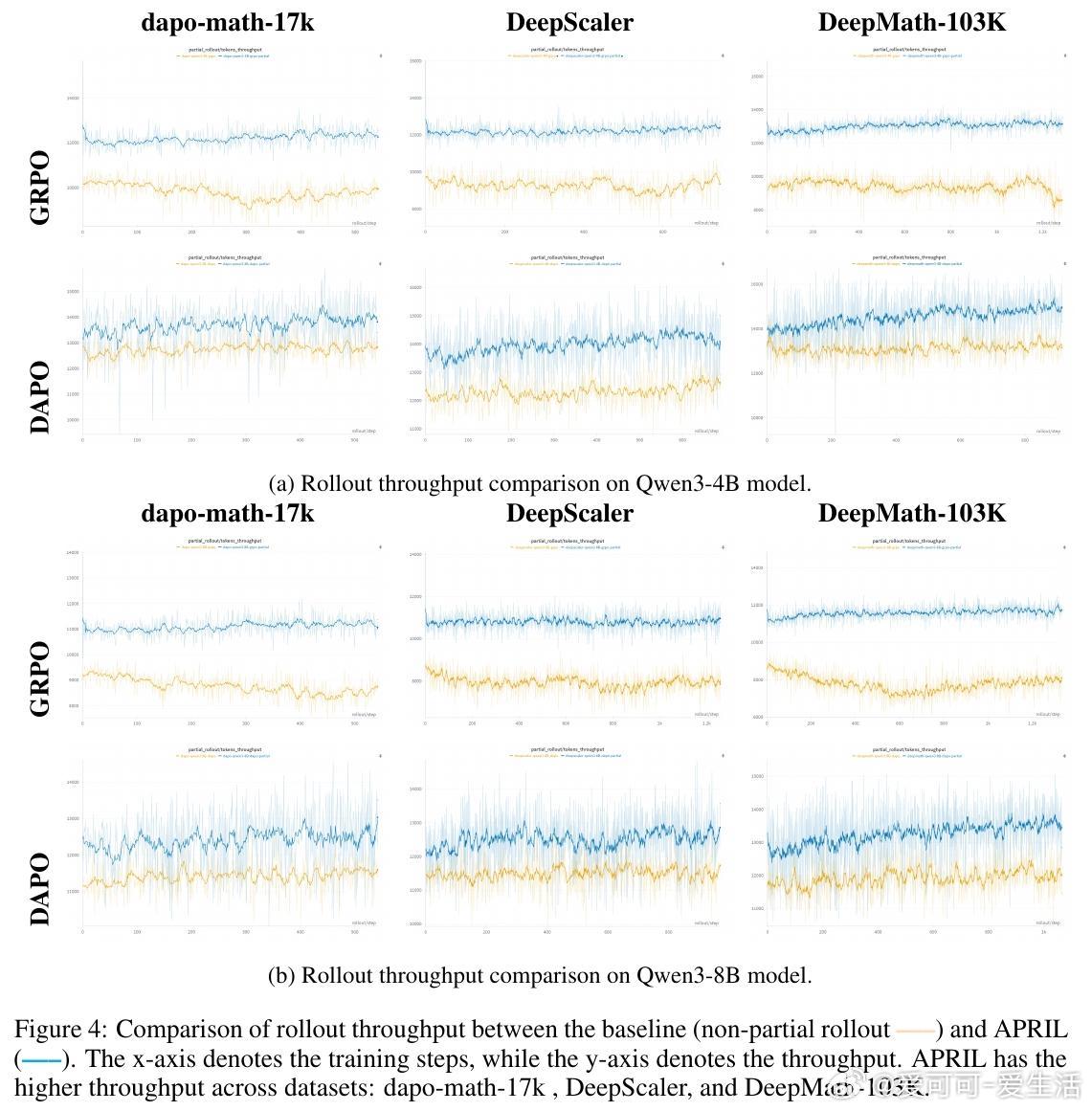
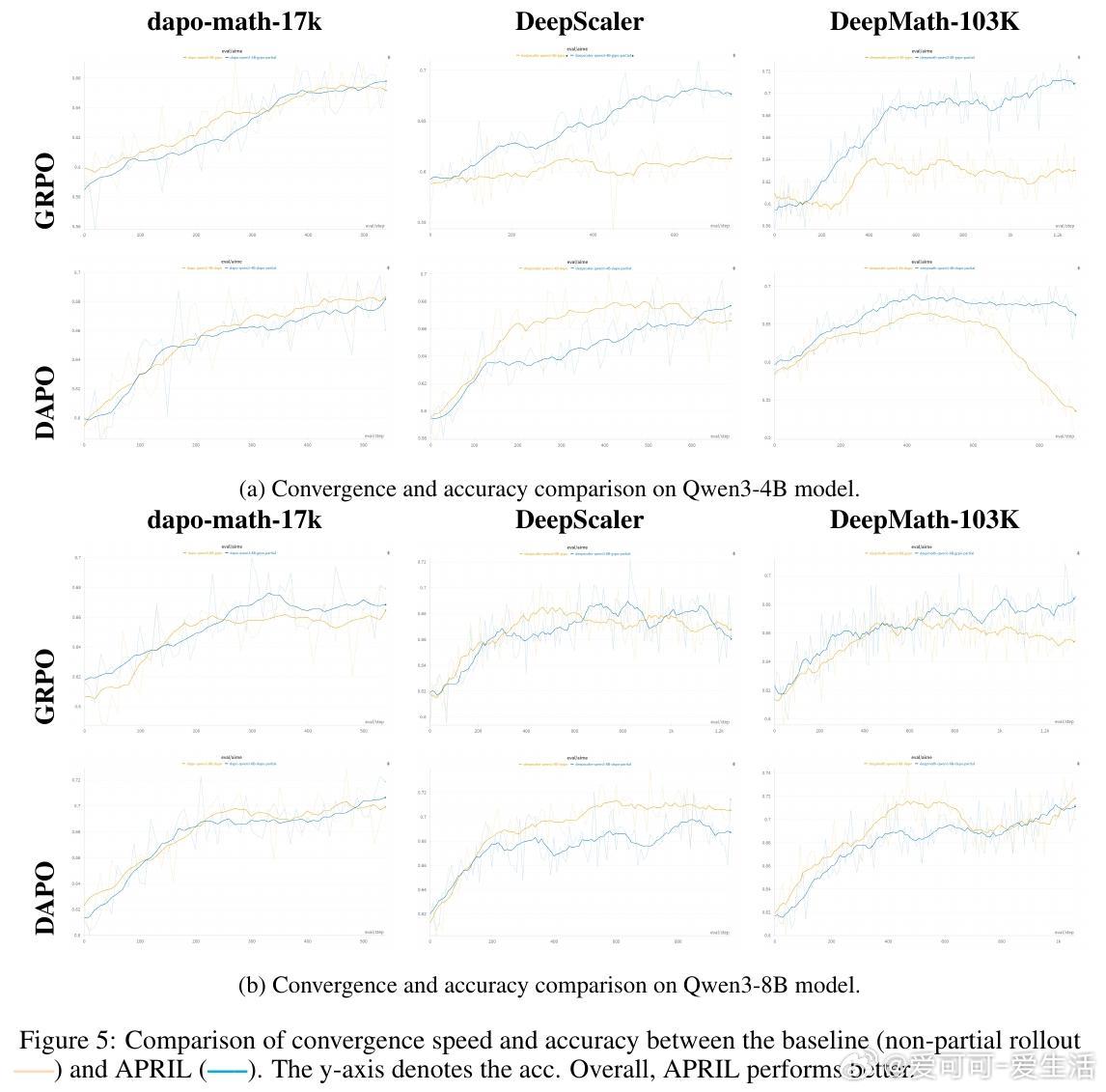
• 实验表明,APRIL在GRPO、DAPO、GSPO等主流算法及Qwen3-4B/8B大模型上,rollout吞吐量提升最高达44%,训练收敛更快,最终准确率提升约2%-8%。
• 部分rollout引入轻度off-policy数据,未破坏训练稳定性,反而增强多样性,避免生成异常长序列,提升训练鲁棒性。
• APRIL兼容多框架(已集成slime)和硬件(NVIDIA、AMD GPU),具备良好普适性和扩展性。
• 与推理层面加速策略(如连续批处理、推测解码)互补,APRIL从系统调度层面优化rollout生命周期,推动RL训练效率跨越瓶颈。
心得:
1. 长尾分布带来的资源浪费是普遍且严重的性能瓶颈,主动管理生成流程比单纯加速推理更关键。
2. 适度引入off-policy数据并非训练“毒药”,反而通过数据多样性促进模型稳定与性能提升。
3. 系统级与算法级的联合优化是提升大模型RL训练效率的必由之路,单一层面优化难以满足日益增长的算力需求。
详情见👉 arxiv.org/abs/2509.18521
强化学习大语言模型长尾问题推理加速系统优化