华为给出中国AI高速方案华为打造全场景算力底座
上周,华为全联接大会集中展示了华为最新最强的一系列创新。
今年最受关注的自然是超节点技术带来的算力风暴和突破。但超节点带来的算力突破还不是全部,超节点架构带动的开源开放,还会把这场风暴推得更深更远。
更加直观类比来说,这是一场华为发起的"AI高速路"修路尝试,开放硬件相当于开放了修路材料,开源软件和灵衢组件相当于开源了修路方法和标准协议。
华为用开源开放,给出了中国AI高速公路枢纽建设的方案——
一个惠及各行业全场景,技术红利覆盖大中小各类玩家的生态。
在华为全联接大会上,华为重磅发布创新的超节点架构,推出覆盖数据中心到工作站的全场景超节点新品。
Atlas 950 SuperPoD是面向超大型AI计算任务的最佳选择,从基础器件、协议算法到光电技术,实现了系统级的创新突破。
其通过正交架构,让Atlas 950实现零线缆电互联,采用液冷接头浮动盲插设计做到零漏液,独创的材料和工艺让光模块液冷可靠性提升一倍。
此外,Atlas 950 SuperPoD创新的UB-Mesh递归直连拓扑网络架构,支持单板内、单板间和机架间的NPU全互联,以64卡为步长按需扩展,最大可实现8192卡无收敛全互联。
即便与英伟达产品对比,Atlas 950超节点也优势显著。
相比计划明年下半年上市的NVL144,其规模、总算力、内存容量、互联带宽分别达到后者的56.8倍、6.7倍、15倍(1152TB)、62倍(16.3PB/s)。
即便对标英伟达2027年计划上市的NVL576,依旧遥遥领先。【图1】
Atlas 850是业界首个企业级风冷AI超节点服务器,内部搭载8张昇腾NPU,有效满足企业模型后训练、多场景推理等需求。
Atlas 850支持多柜灵活部署,最大可形成128台1024卡的超节点集群,是目前业内唯一可在风冷机房实现超节点架构的算力集群,企业无需改造现有风冷机房即可部署算力集群。【图2】
Atlas 350标卡采用最新的昇腾950PR芯片,向量算力提升2倍,支持更细粒度的Cacheline访问,在推荐推理场景可实现2.5倍性能提升,且单卡即可运行。
Atlas 350支持灵衢端口互联,实现算力、内存等资源池化,让更大参数模型、更低时延应用可以在标卡上实现。【图3】
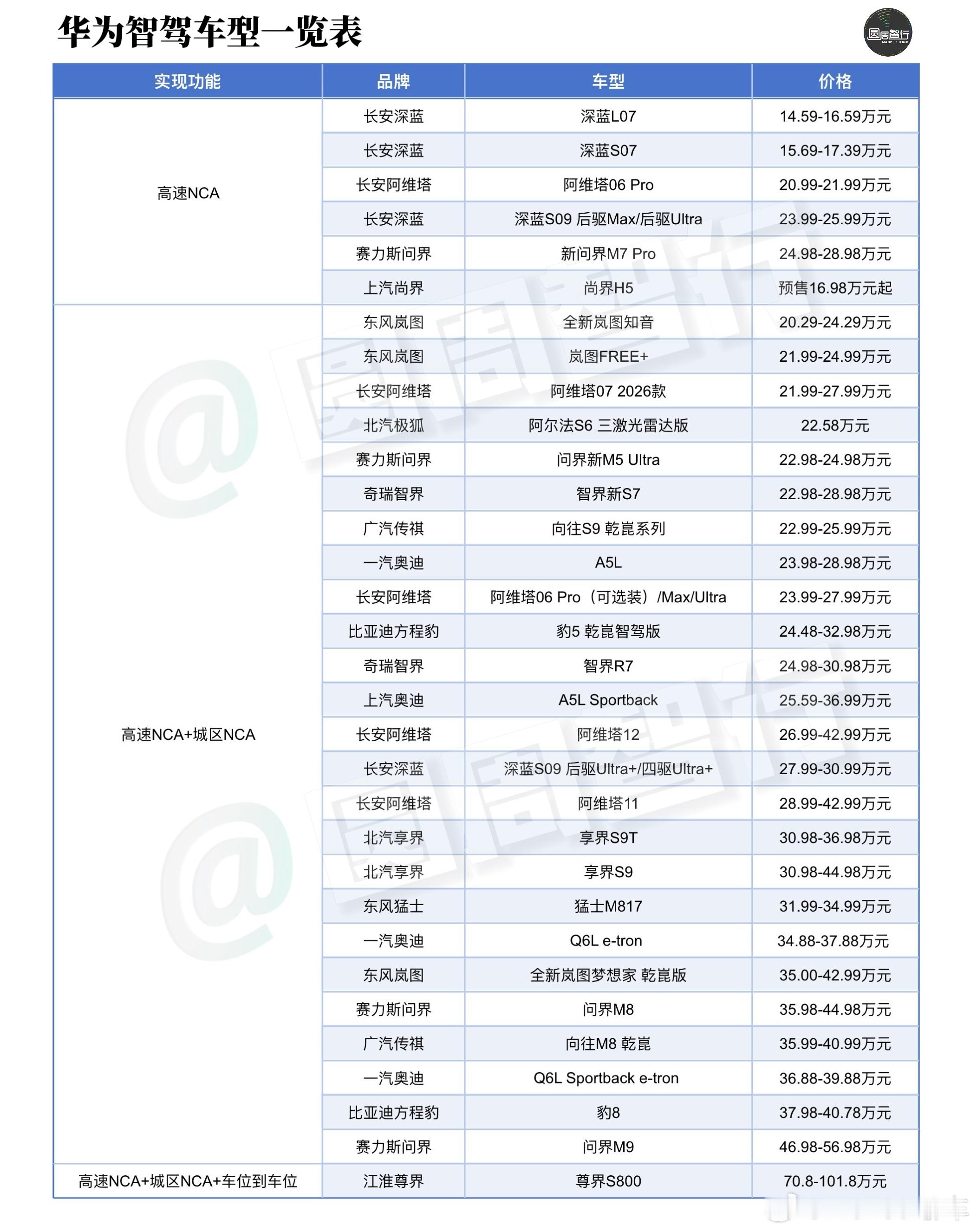
TaiShan 950 SuperPoD是华为推出的业界首款通算超节点,具备百纳秒级超低时延、Tb级超大带宽和内存池化能力,能大幅提升数据库、虚机热迁移和大数据场景等业务性能,为通算性能提升开辟全新路径。
这一系列的超节点新品能实现从数据中心、企业部署、小型工作站的全场景覆盖,从而在硬件层面协同用户实现个性化部署,推动AI高速公路互通互联。
而就在超节点发布的同时,华为选择了全面的开放和开源。
首先是硬件层面的开放。
华为宣布全面开放超节点技术,与产业界共享技术红利,共同推动超节点技术走向普惠与协同创新。
一方面,开放灵衢协议和超节点参考架构,允许产业界基于技术规范自研相关产品或部件。
另一方面,全面开放超节点基础硬件,包括NPU模组、风冷刀片、液冷刀片、AI标卡、CPU主板和级联卡等不同形态的硬件,方便客户和伙伴进行增量开发,设计基于灵衢的各种产品。
其次是软件层面的开源。
超节点的运行离不开操作系统的深度支持,操作系统灵衢组件也将全部开源,组件代码将陆续合入openEuler等多个上游操作系统开源社区。
用户可以根据实际需求,将部分或全部源代码集成到现有操作系统中,自行迭代维护版本,也可以将整个组件直接合入现有操作系统,未来演进与开源社区版本同步。
开源是驱动技术创新和产业进步的核心力量,昇腾CANN全面开源开放,Mind系列组件也同步开源,并支持PyTorch、vLLM等业界开源社区,加速开发者自主创新。
可以说,华为这一手硬件、一手软件直接开源了个痛快!【图4】
华为为何要开源?
一方面,开源能够和产业界、开发者社区基于超节点架构自研相关产品或部件、自定义调试调优、共享技术红利,加速产业协同发展。
另一方面,开源还有利于消费者按需取用、降低适配成本,打造面向行业的超节点场景化解决方案。
华为董事、ICT BG CEO杨超斌表示:
华为将围绕超节点架构持续创新,让超节点技术不但用于大型数据中心,也可以用于企业级的数据中心和小型工作站。同时,坚持硬件开放,支持各个伙伴,灵活打造面向各个行业的超节点场景化解决方案。坚持软件开源,让开发者灵活高效创新,共建繁荣生态。
这就意味着,超节点技术不再是少数大型数据中心的专属利器,而是一个开放共享的算力生态。
每个行业、每个企业、每位开发者都能根据自身需求,灵活搭建自己的算力"高速路"。
无论是大型模型训练、复杂推理任务,还是企业级应用场景,用户都能按需获取硬件和软件能力,实现算力资源的高效利用和灵活扩展。