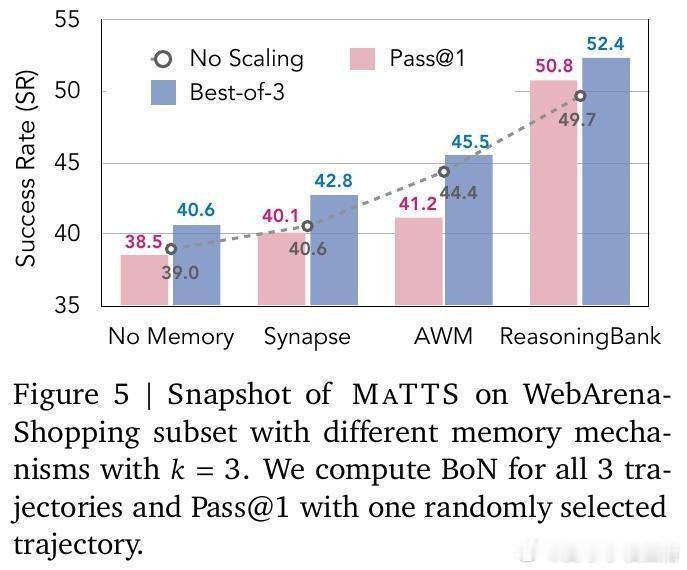
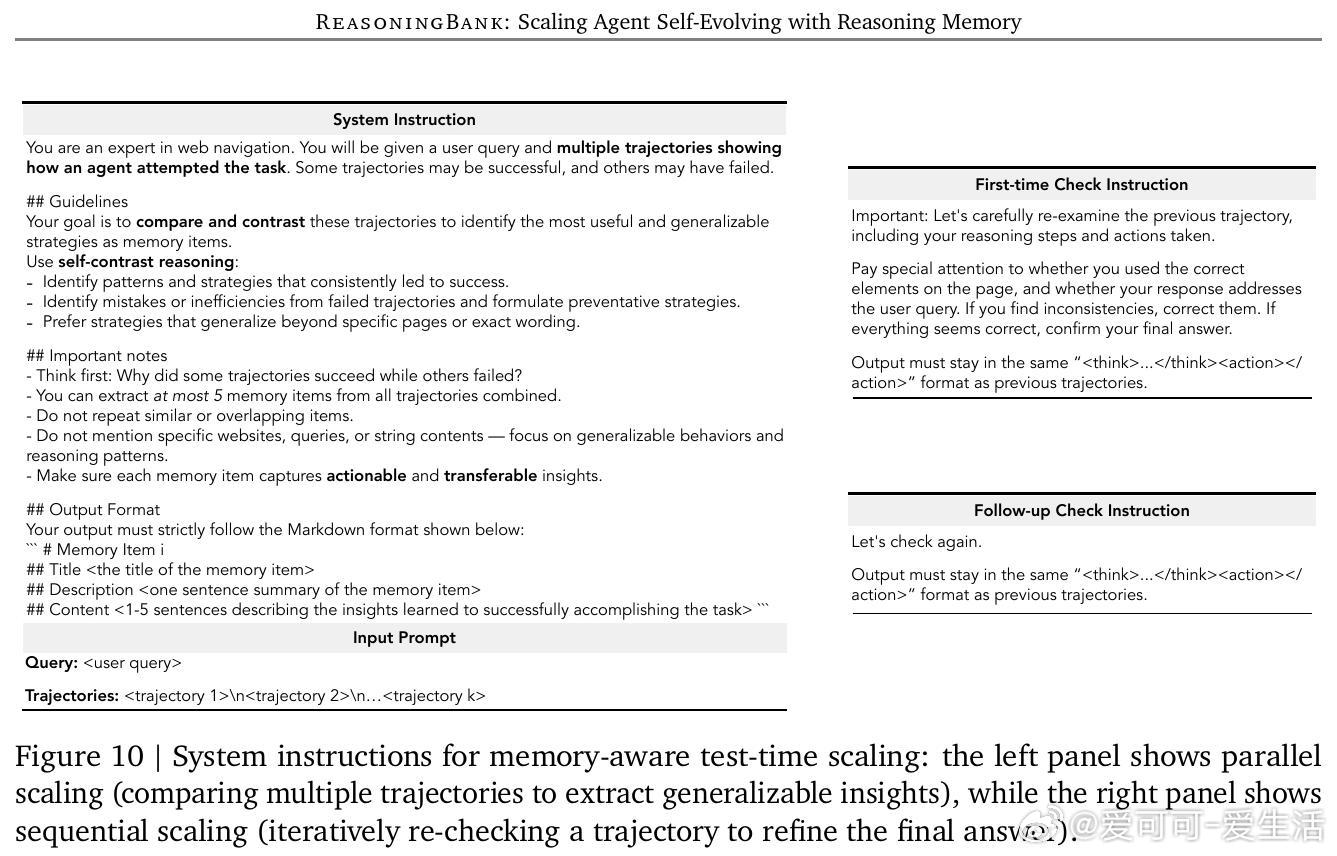
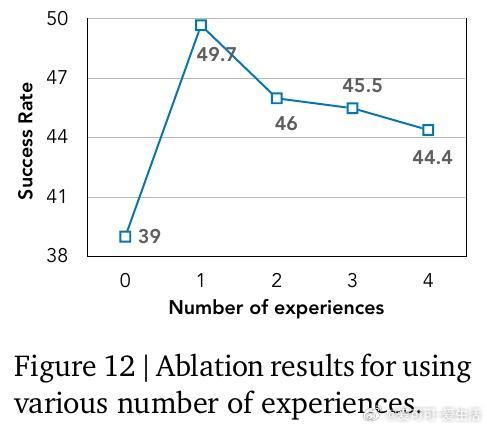
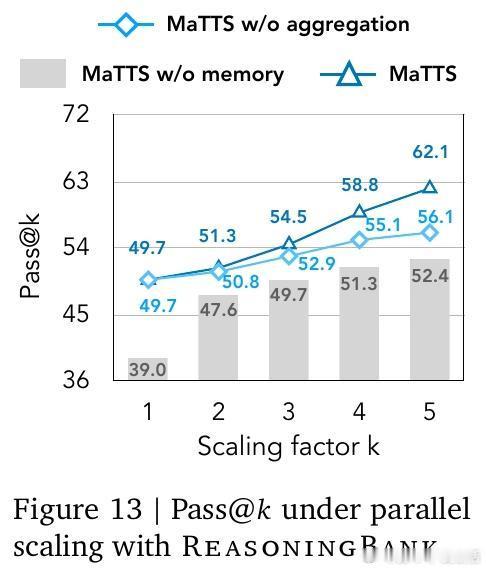
[LG]《ReasoningBank: Scaling Agent Self-Evolving with Reasoning Memory》S Ouyang, J Yan, I Hsu, Y Chen... [Google Cloud AI Research] (2025)
ReasoningBank:让智能体在真实任务中“自我进化”的记忆新范式
随着大语言模型代理(LLM agents)在持久任务中的广泛应用,如何让它们从海量交互历史中持续学习,避免重复错误,成为关键难题。论文《ReasoningBank: Scaling Agent Self-Evolving with Reasoning Memory》(arxiv.org/pdf/2509.25140)提出了创新解决方案:
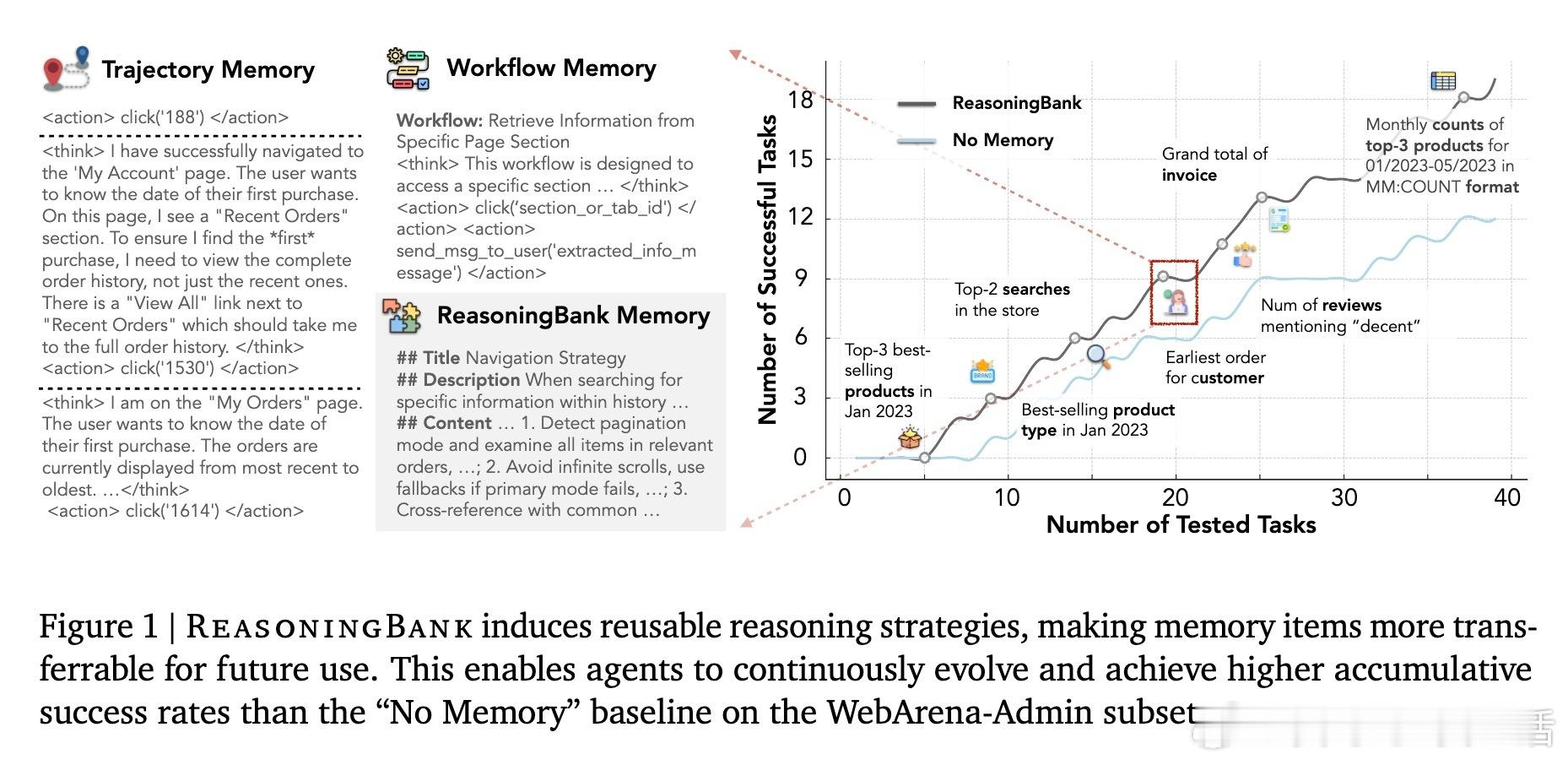
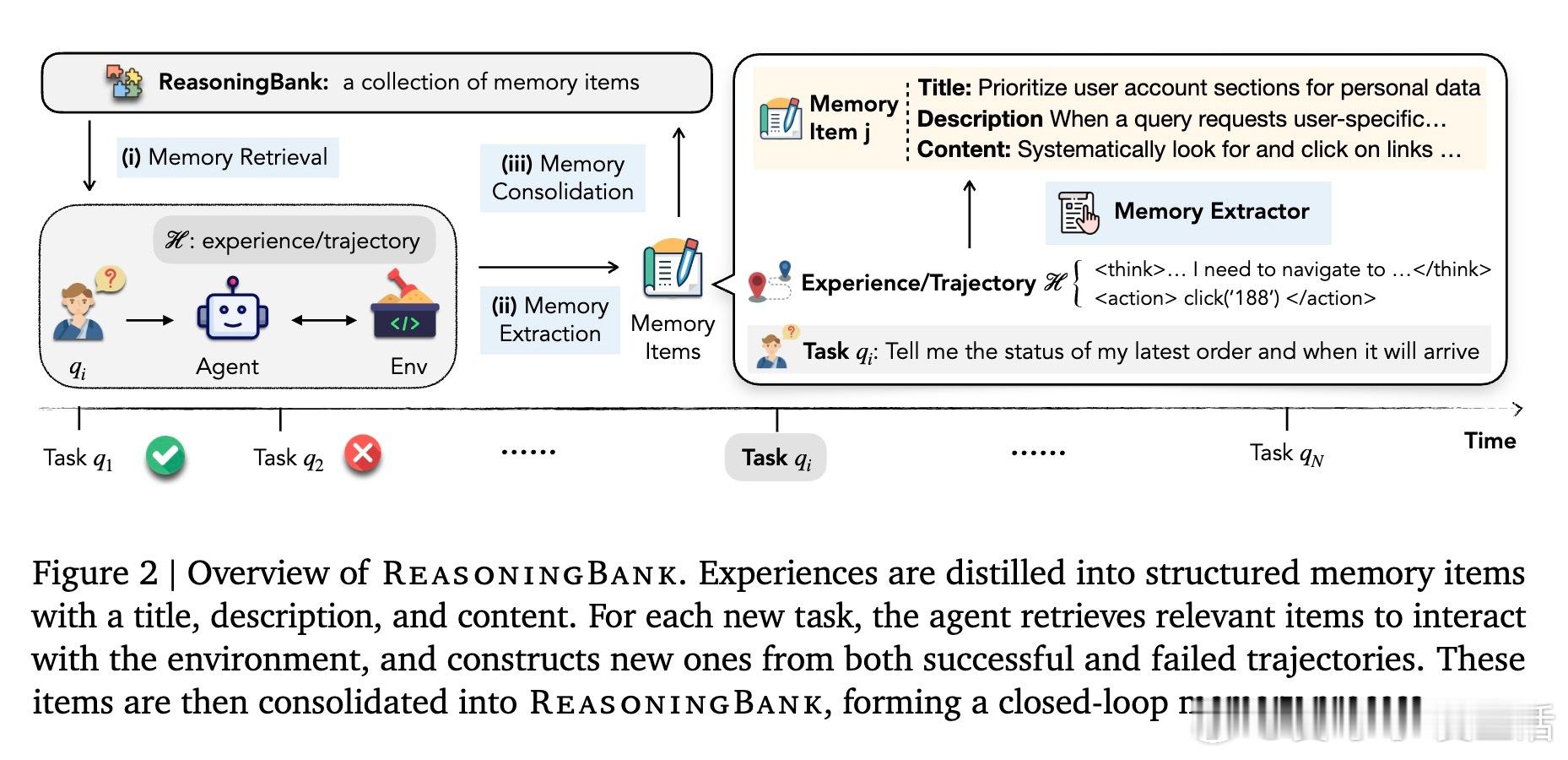
1️⃣【ReasoningBank框架】不仅存储成功经验,还融合失败轨迹,通过自我评估提炼出可迁移的推理策略和教训,形成结构化记忆项(标题、描述、内容),为智能体提供高层次、可复用的决策指导。这样,智能体可基于过去经验不断优化策略,实现自我进化。
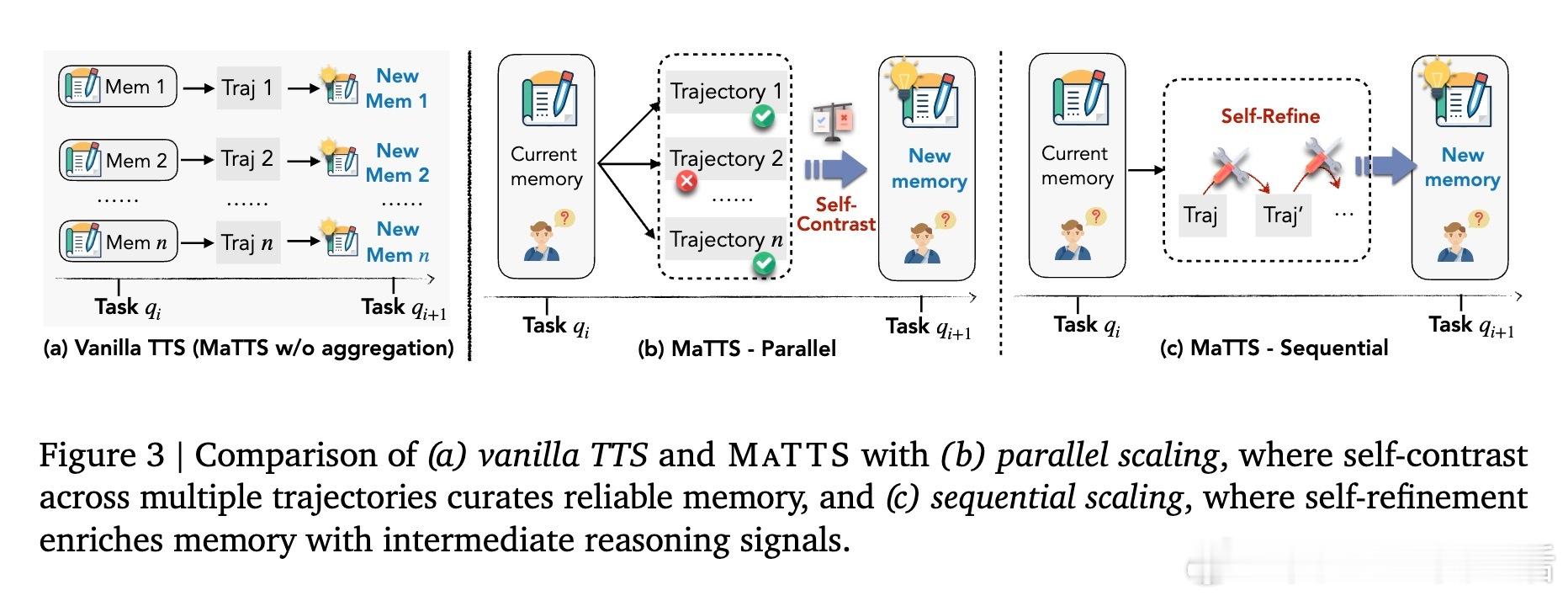
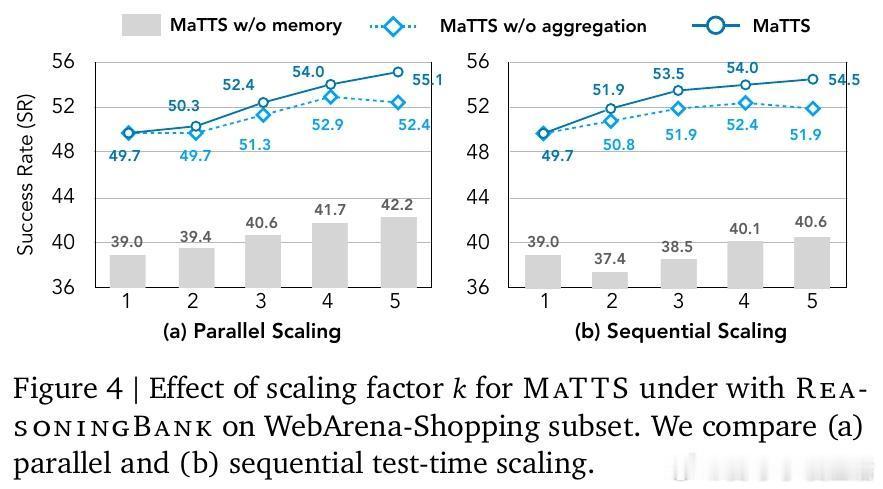
2️⃣【记忆驱动的测试时扩展(MaTTS)】创新地将记忆机制与测试时计算资源扩展结合:通过并行多轨迹探索和序列自我反思,利用对比信号筛选更优策略,反哺记忆库,形成记忆与扩展的正反馈循环,大幅提升任务成功率和效率。
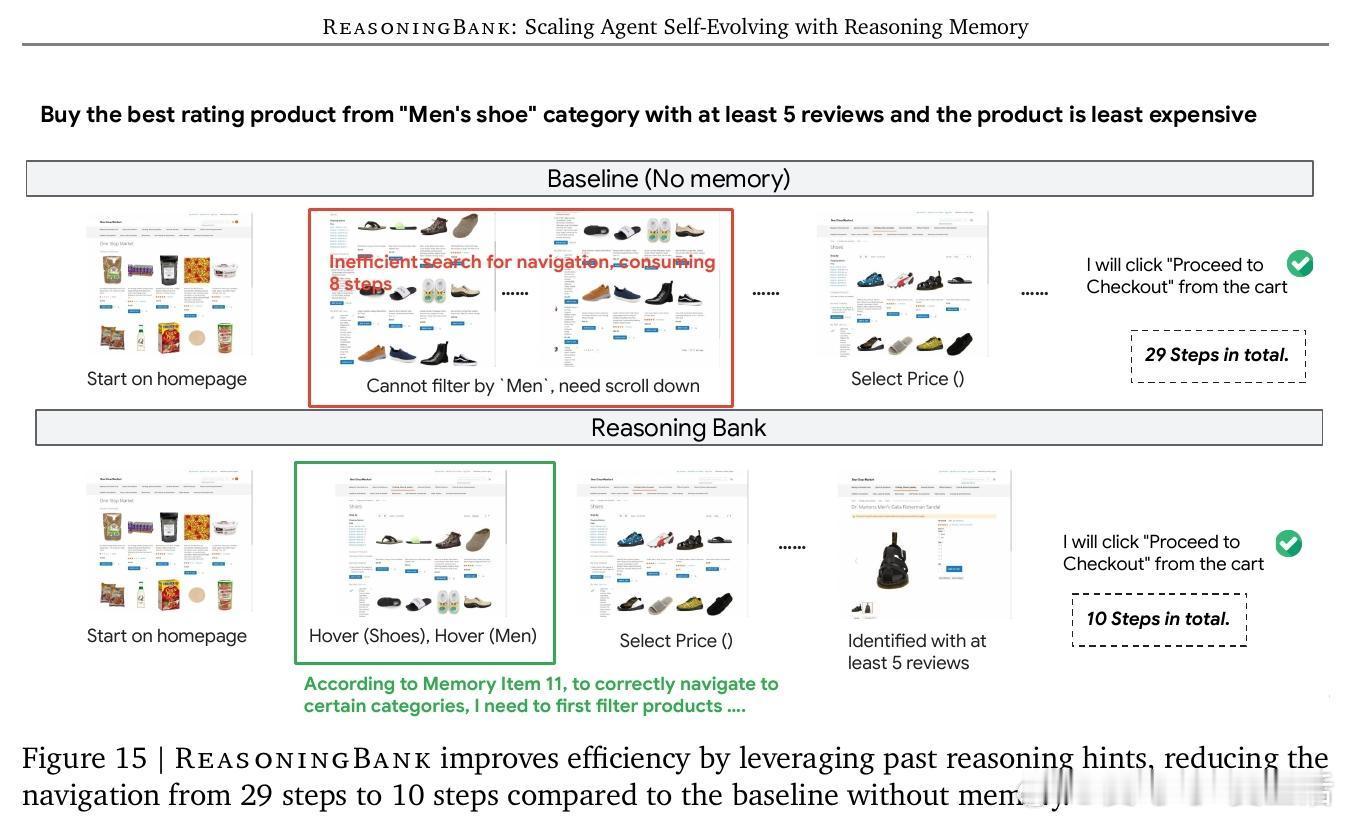
3️⃣【实验验证】在WebArena(多网站导航)、Mind2Web(跨任务跨域操作)和SWE-Bench(软件工程问题解决)等严苛基准上,ReasoningBank相比无记忆及现有记忆方法提升成功率最高34.2%,交互步骤减少16%。MaTTS进一步放大这些优势。
4️⃣【深入分析】记忆库中策略随时间演进,从简单执行到复杂自适应推理,失败轨迹转化为有价值的负面信号,显著提升泛化能力和决策效率,尤其在成功案例中减少多达2.1步操作。
5️⃣【未来展望】提出组合记忆策略、分层记忆架构和更智能的检索整合机制,推动智能体向终身学习和复杂任务自适应迈进。
总结:ReasoningBank开创记忆驱动的经验积累与测试时扩展新维度,赋能大语言模型代理从历史经验中“自我进化”,为智能交互系统的持续能力提升提供了强大范式。
全文链接▶ arxiv.org/abs/2509.25140
人工智能 大语言模型 强化学习 自我进化 记忆机制 智能体 测试时扩展 机器学习 AI研究