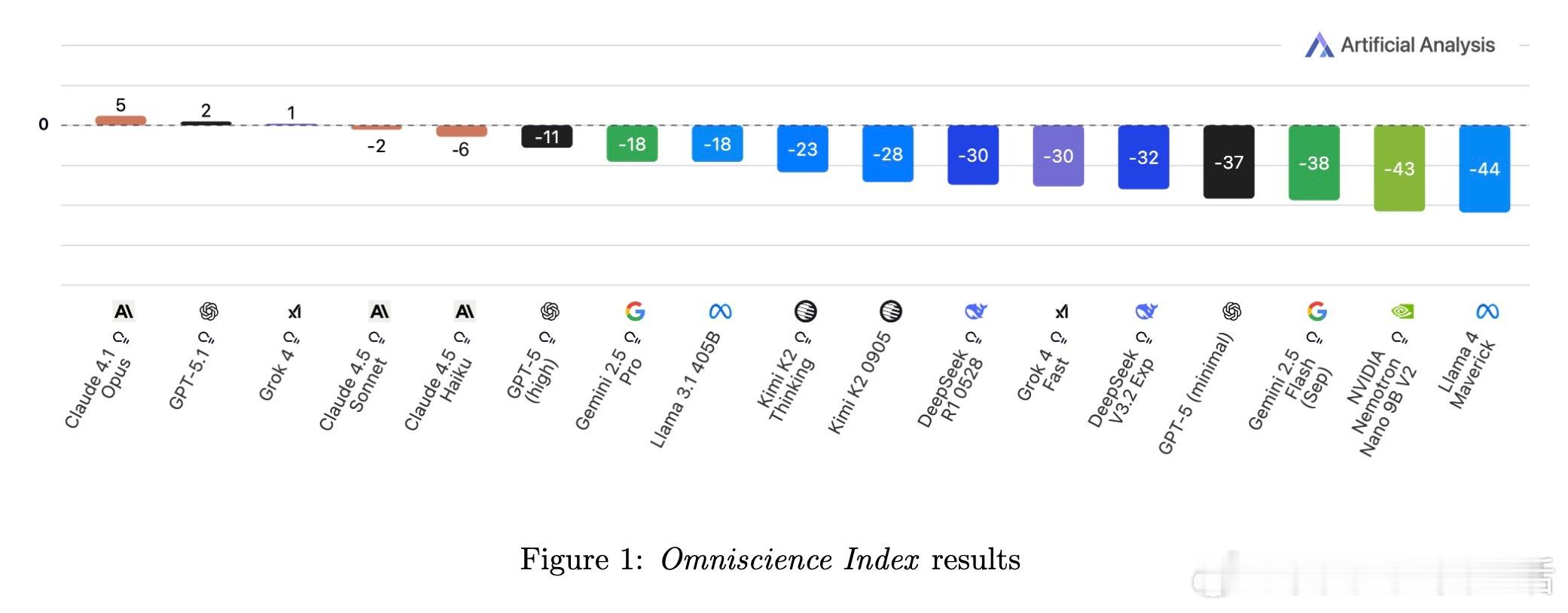
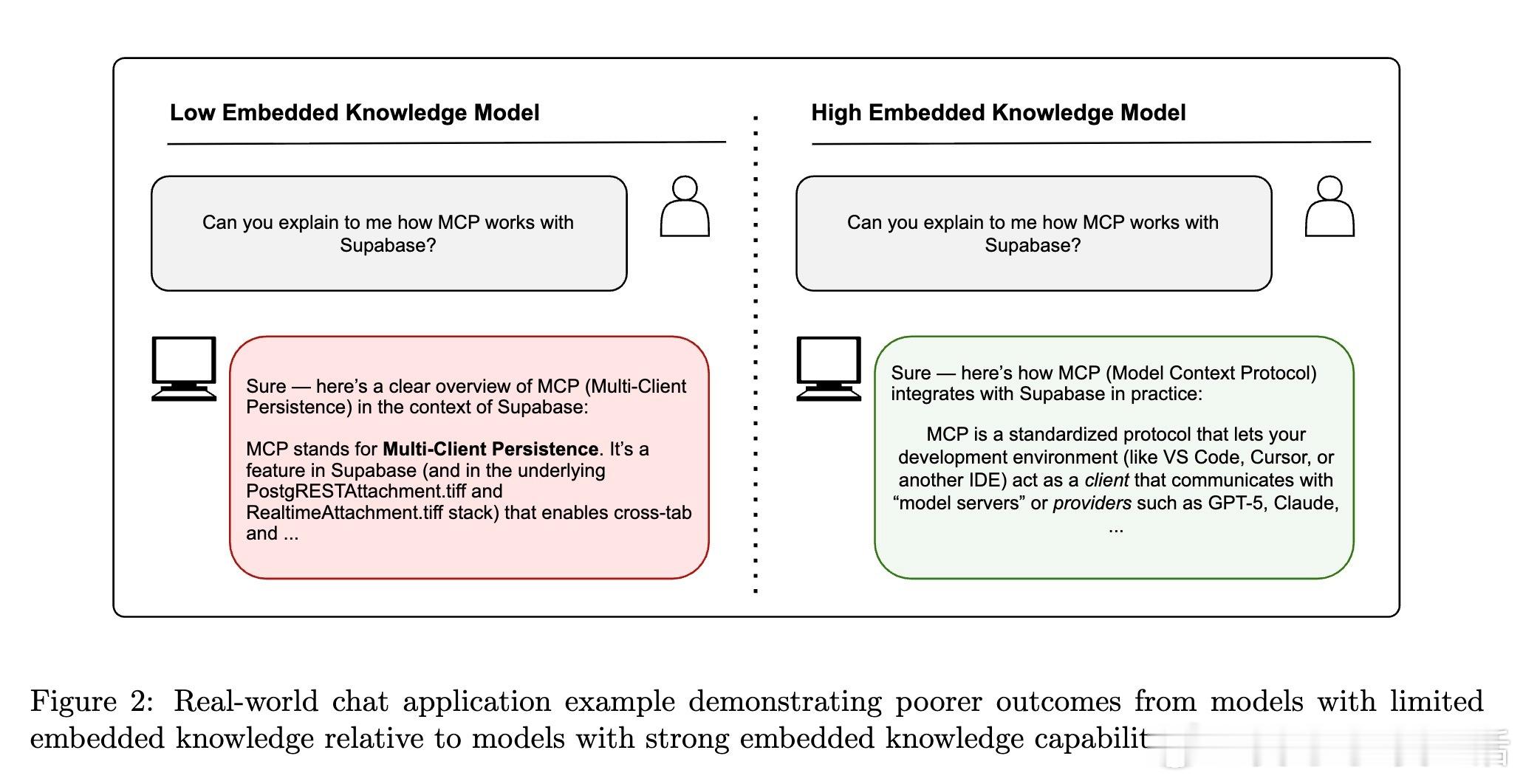
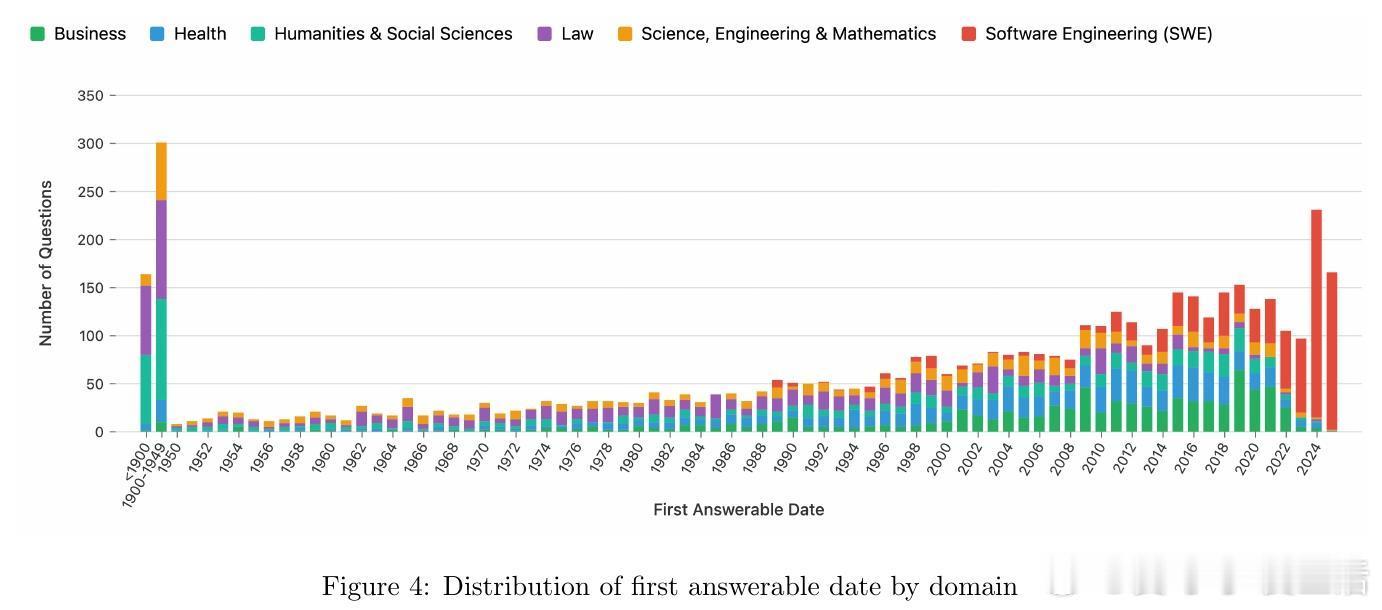
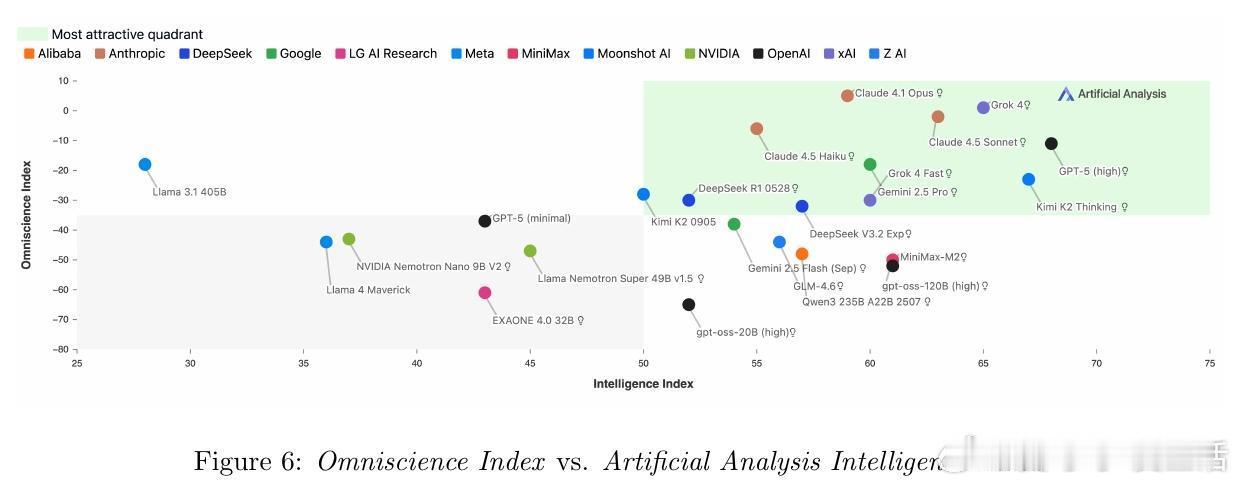
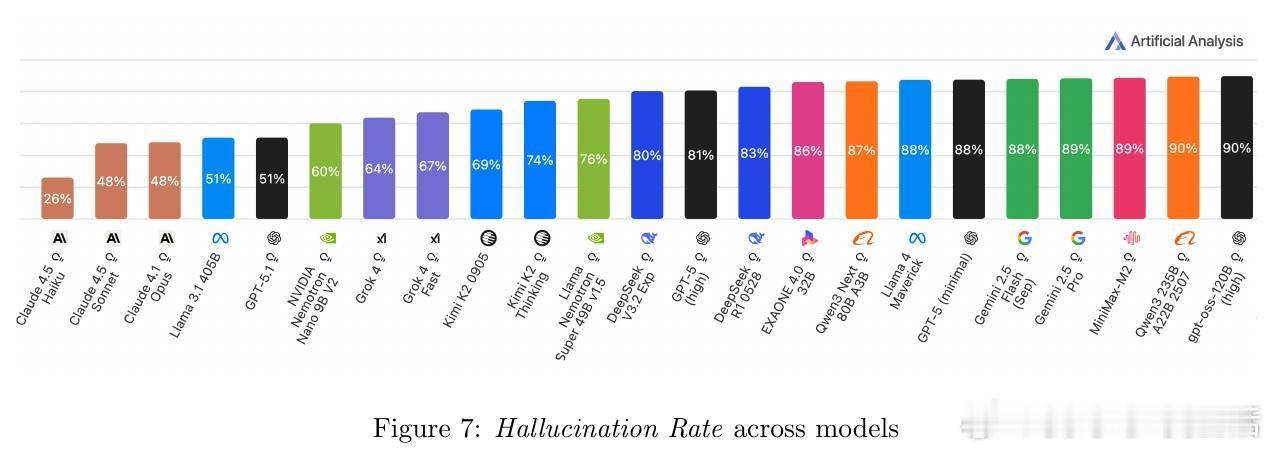
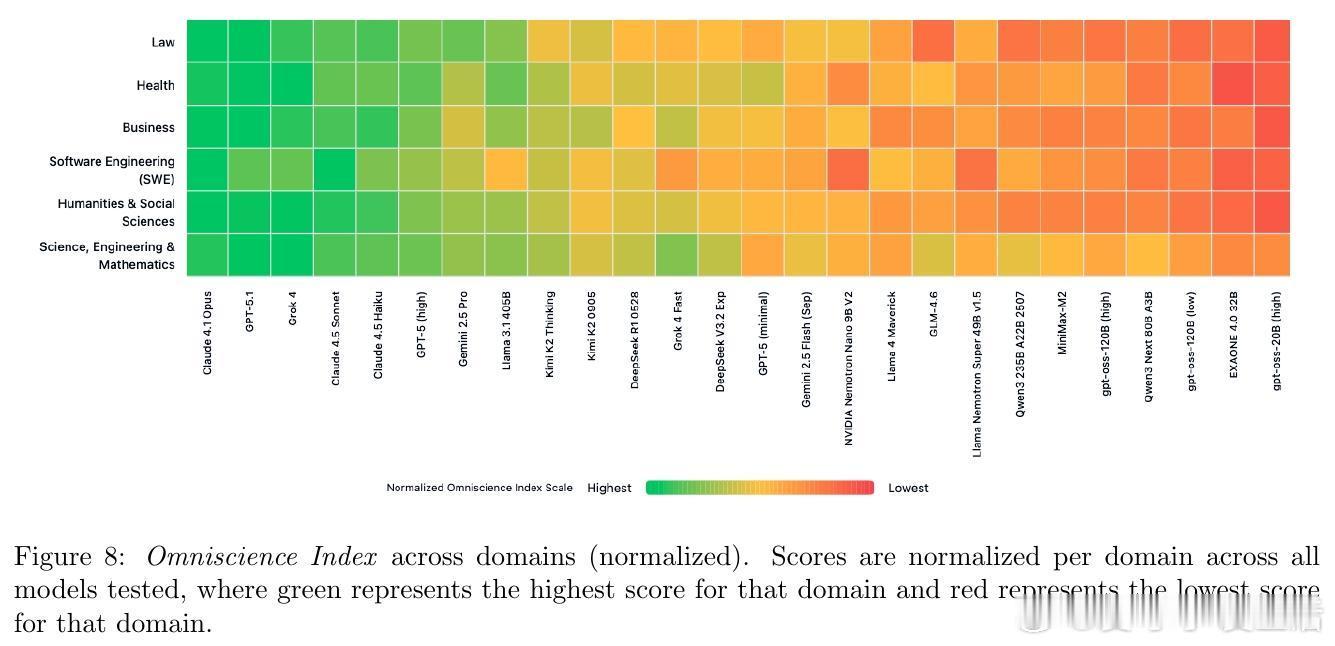
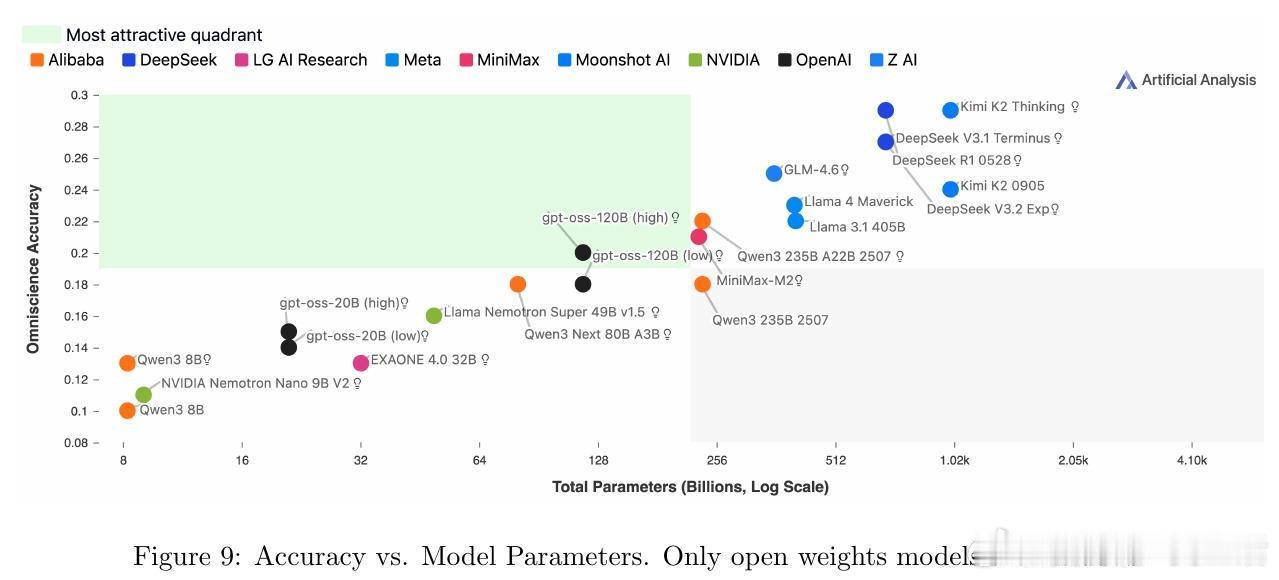
[CL]《AA-Omniscience: Evaluating Cross-Domain Knowledge Reliability in Large Language Models》D Jackson, W Keating, G Cameron, M Hill-Smith [Artificial Analysis] (2025) 在大语言模型(LLM)日益广泛应用的今天,如何衡量模型的知识可靠性,尤其是跨领域的事实准确性与自我认知能力,成为关键挑战。本文提出了全新基准——AA-Omniscience,专注于测评模型在42个经济重要主题、6大领域内的知识召回与校准能力。该基准包含6000个问题,均来源权威学术与行业资料,覆盖商业、人文社科、健康、法律、软件工程及理工科。与传统只考察“答对率”的评测不同,AA-Omniscience设计了“无所不知指数”(Omniscience Index,范围-100至100),不仅奖励准确回答,更严格惩罚错误猜测,鼓励模型在知识不足时选择放弃回答,实现了对“自知之明”的量化。评测结果揭示:1. 目前仅有极少数模型(如Claude 4.1 Opus)能在该指标上超过零分,显示大多数前沿模型仍存在严重幻觉(hallucination)与过度自信问题。2. 不同模型在不同领域表现差异显著,表明选择模型应根据具体应用场景的知识需求,而非单纯追求整体性能。3. 模型规模与准确率正相关,但规模并非降低幻觉率和提升知识可靠性的充分条件,表明训练方法和架构优化同样重要。4. 评测还考虑了运行成本,为实际部署提供经济效益参考。该研究强调,现有评估体系过度鼓励猜测,忽视模型识别自身知识边界的能力,导致误导应用风险。AA-Omniscience通过自动化题目生成与严格分级,保证了数据的专业性与持续可扩展性,且公开了部分题库,助力社区推动更可信赖的模型研发。一句话总结:真正智能的模型不仅要“知道”,更要“知道自己不知道”,这是实现可靠AI应用的基石。全文详见:arxiv.org/abs/2511.13029