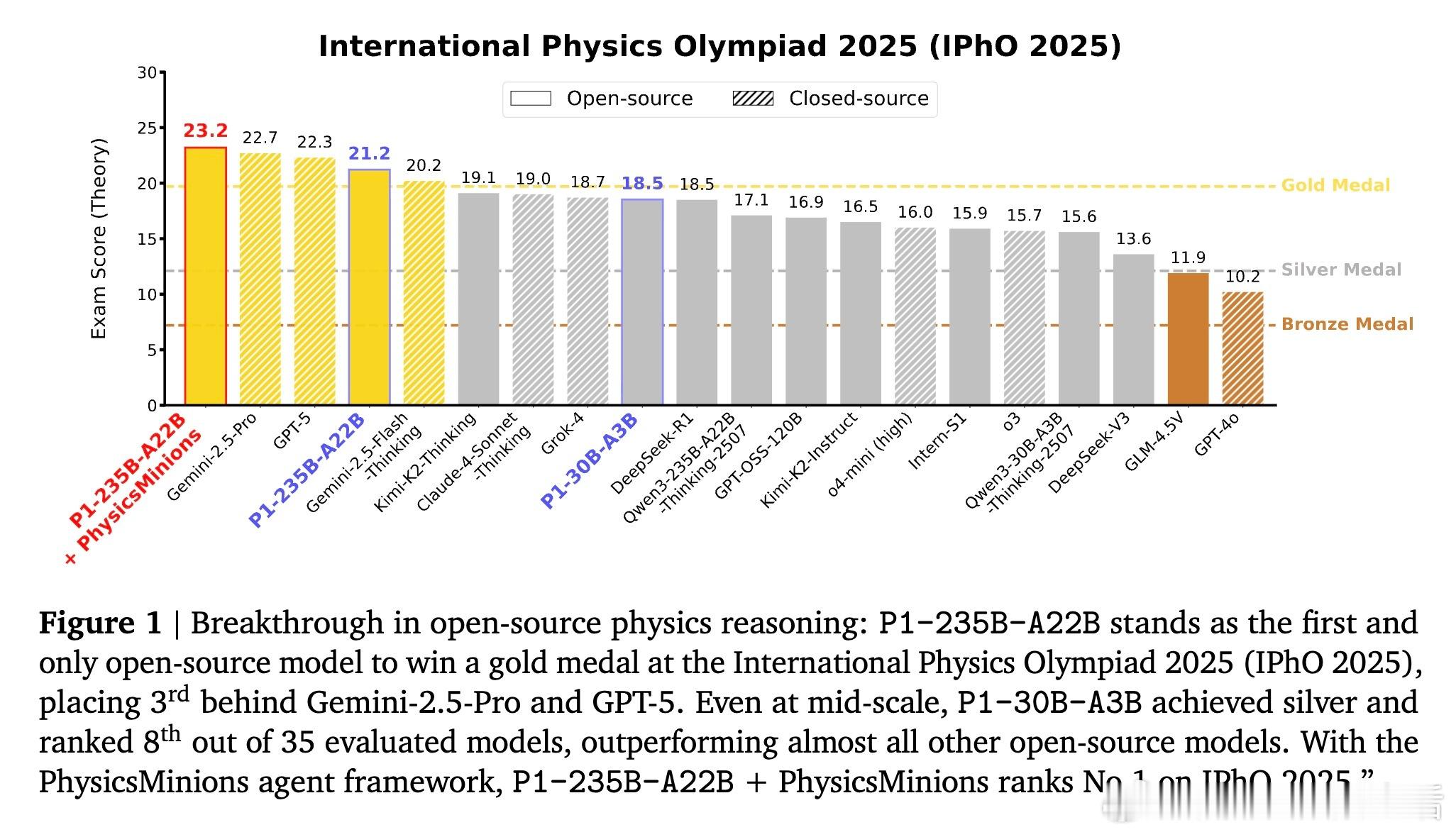
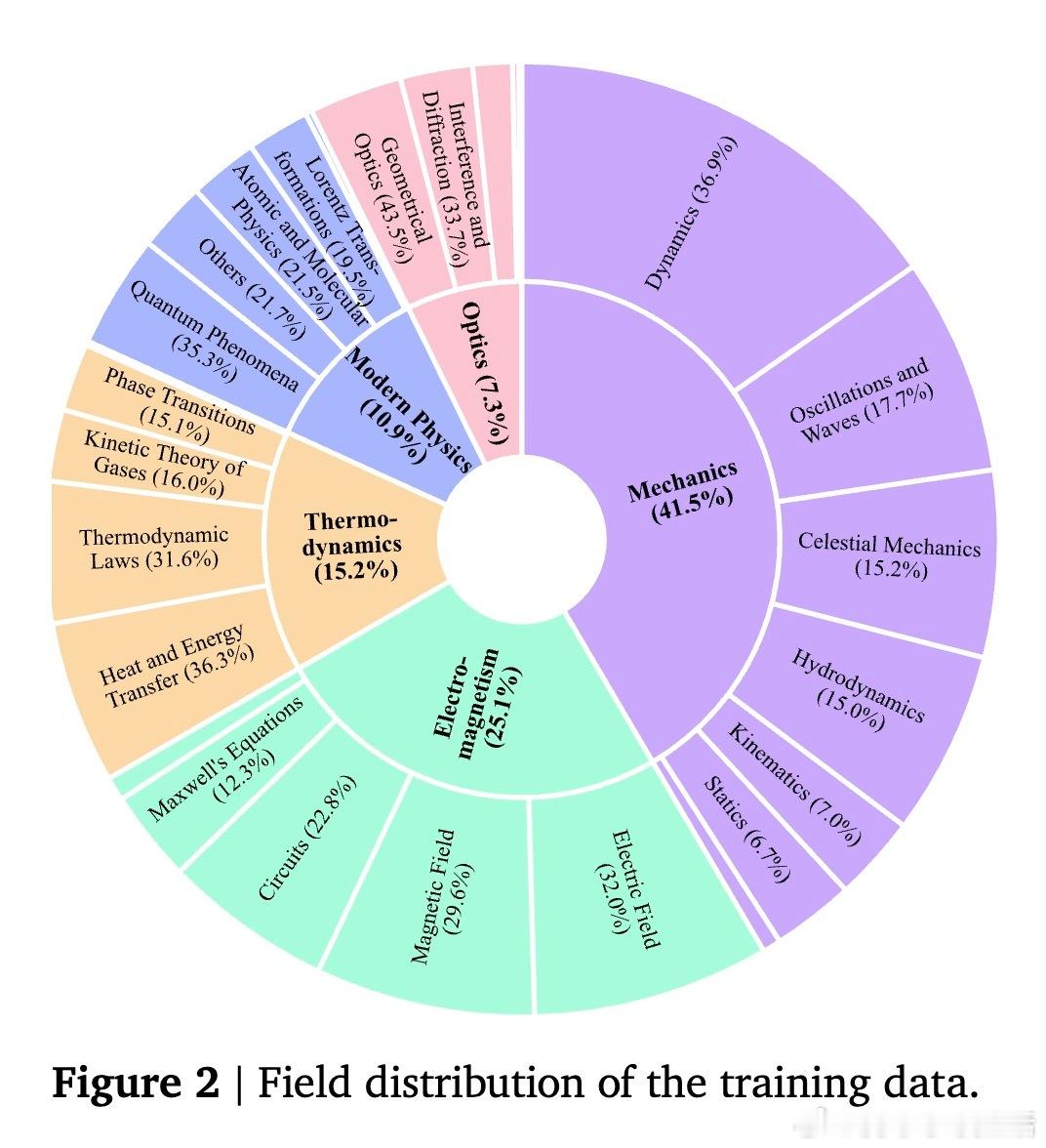
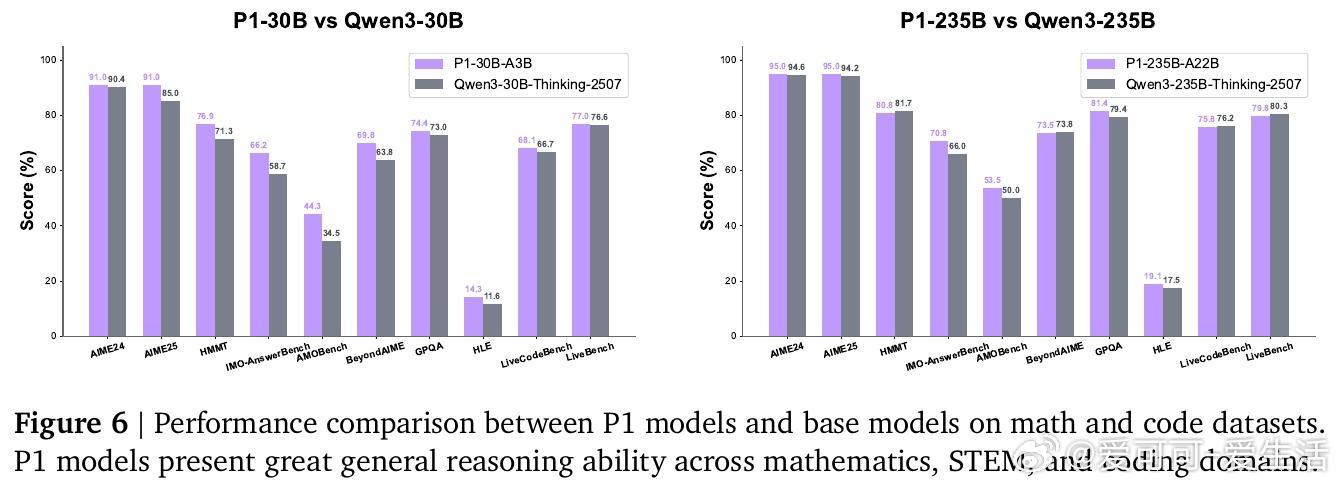
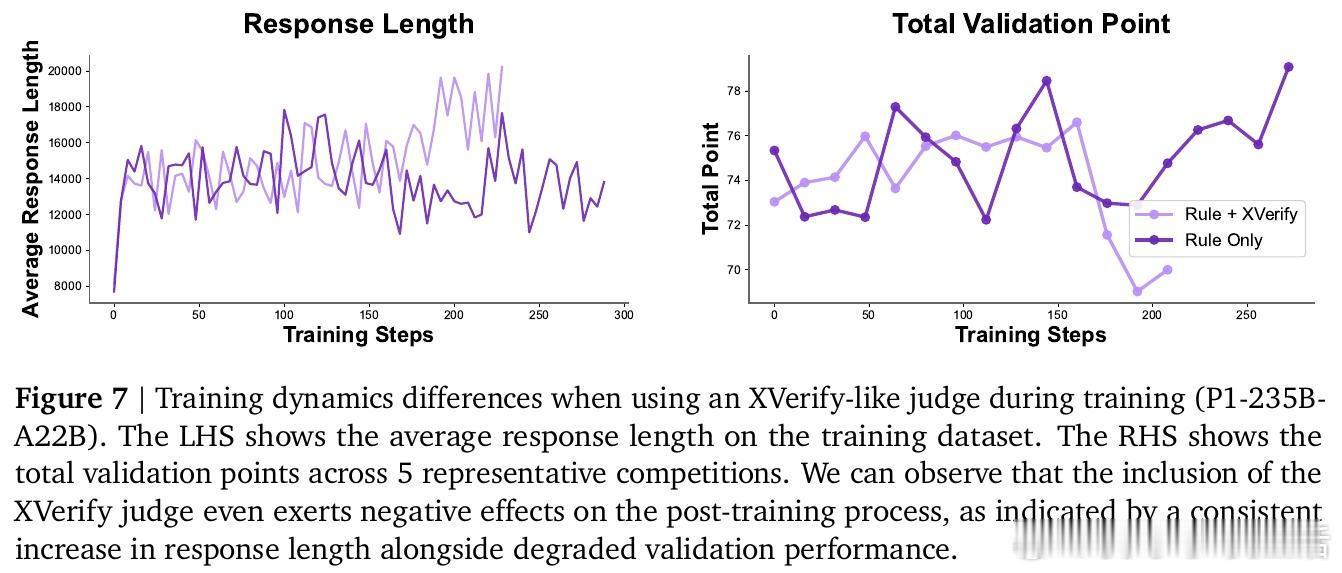
[LG]《P1: Mastering Physics Olympiads with Reinforcement Learning》J Chen, Q Cheng, F Yu, H Wan... [Shanghai AI Laboratory] (2025) P1:首个开源物理奥林匹克级别强化学习大模型,突破科学级推理边界!近期大语言模型(LLMs)已从简单解题跃升到科学级推理,而物理学是最严苛的试金石——它将符号与现实紧密绑定,是现代科技基石。本文推出了P1系列模型,专注于物理奥赛难题的强化学习训练,标志着AI科学推理的里程碑。核心成果:- P1-235B-A22B成为首个在2025年国际物理奥林匹克(IPhO 2025)夺得金牌的开源模型,2024/2025年共斩获13场国际/区域物理竞赛12金1银。- P1-30B-A3B中型模型也获得银牌,优于几乎所有开源对手。- 配合PhysicsMinions智能代理框架,P1-235B-A22B+PhysicsMinions实现IPhO 2025综合排名第一,13项竞赛平均成绩最高。- 除物理外,P1系列在数学、编码等推理任务中表现优异,显示出极强的泛化能力。技术亮点:- 纯强化学习后训练:采用多阶段RL框架,动态调整学习难度及探索空间,克服稀疏奖励、熵崩溃等训练瓶颈,实现持续性能提升。- 结构化物理数据集:精心构建含5,065道题的高质量物理奥赛文本数据,结合专家解答与规则可验证答案,确保训练监督的科学严谨。- Hybrid验证机制:结合符号计算和模型验证,保障答案判定的精准与广泛覆盖。- 代理式推理框架PhysicsMinions:模拟人类物理学家“解题—自检—修正”流程,多轮迭代提升解题深度和准确度。- 训练稳定性保障:采用截断重要性采样缓解训练推理策略差异带来的偏差,确保优化过程稳定高效。性能表现:- P1-235B-A22B在IPhO 2025理论考试中得分21.2/30,位列全球前三,仅次于Gemini-2.5-Pro和GPT-5,领先所有开源模型。- 在中国物理奥林匹克(CPhO 2025)理论赛中,P1-235B-A22B得分227/320,超越最高人类得分199分,展现出超越人类精英的实力。- 结合PhysicsMinions后,P1模型在13项奥赛综合评测中均领先,实现了开源领域前所未有的统治力。泛化能力:P1不仅专精物理,其数学(包括IMO难度)、STEM和编程推理能力均显著优于基础模型,表明强化学习后训练在提升科学推理的同时,增强了模型的跨领域迁移力。深度思考:“科学推理的力量不仅在于准确解答,更在于能否贯通自然法则与抽象逻辑。”P1的成功证明,AI通过强化学习与多轮自我校验,能够迈向真正的科学智能,助力未来物理研究的突破。开放生态:P1提供端到端开源方案,涵盖模型、训练算法、评测基准与代理推理框架,期待全球科学与AI社区共筑未来。详情阅读论文:arxiv.org/abs/2511.13612