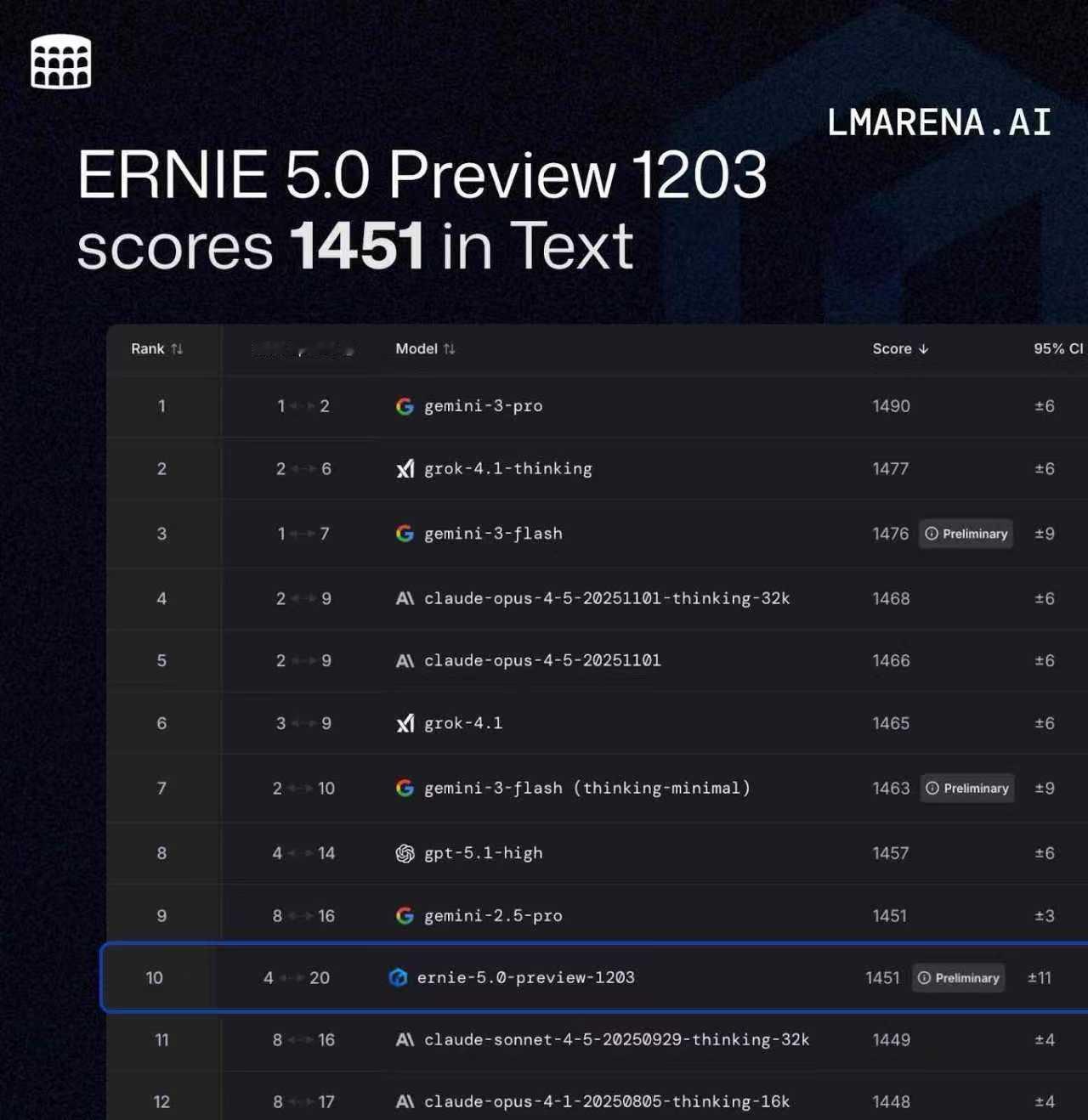
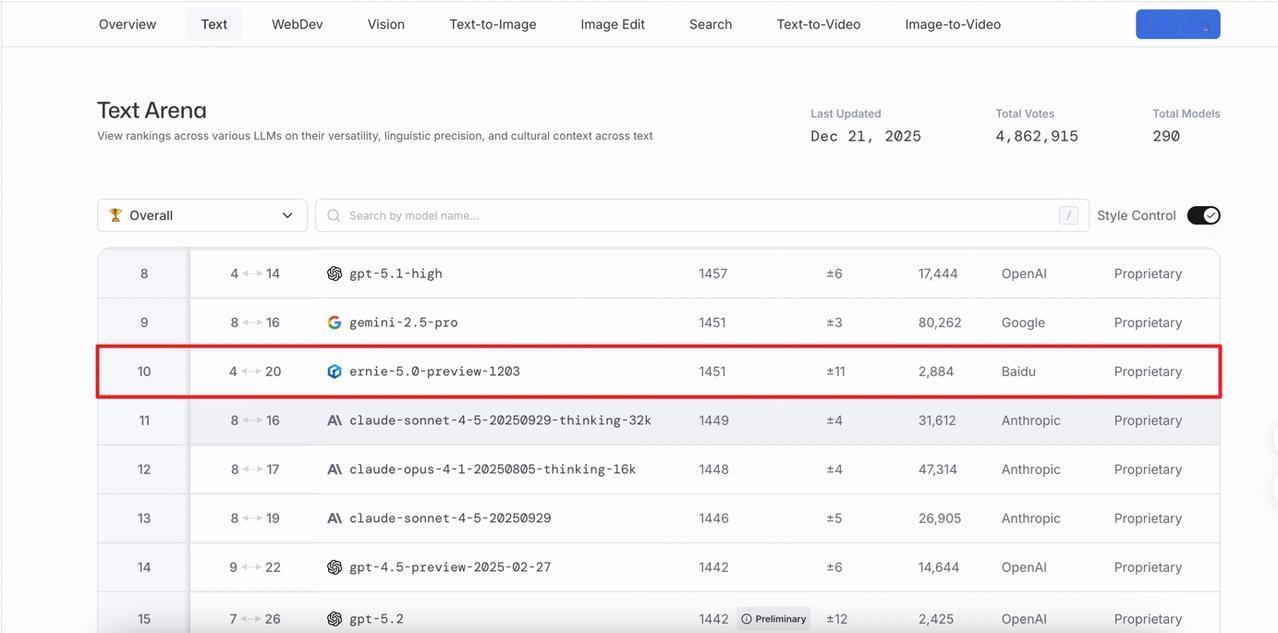
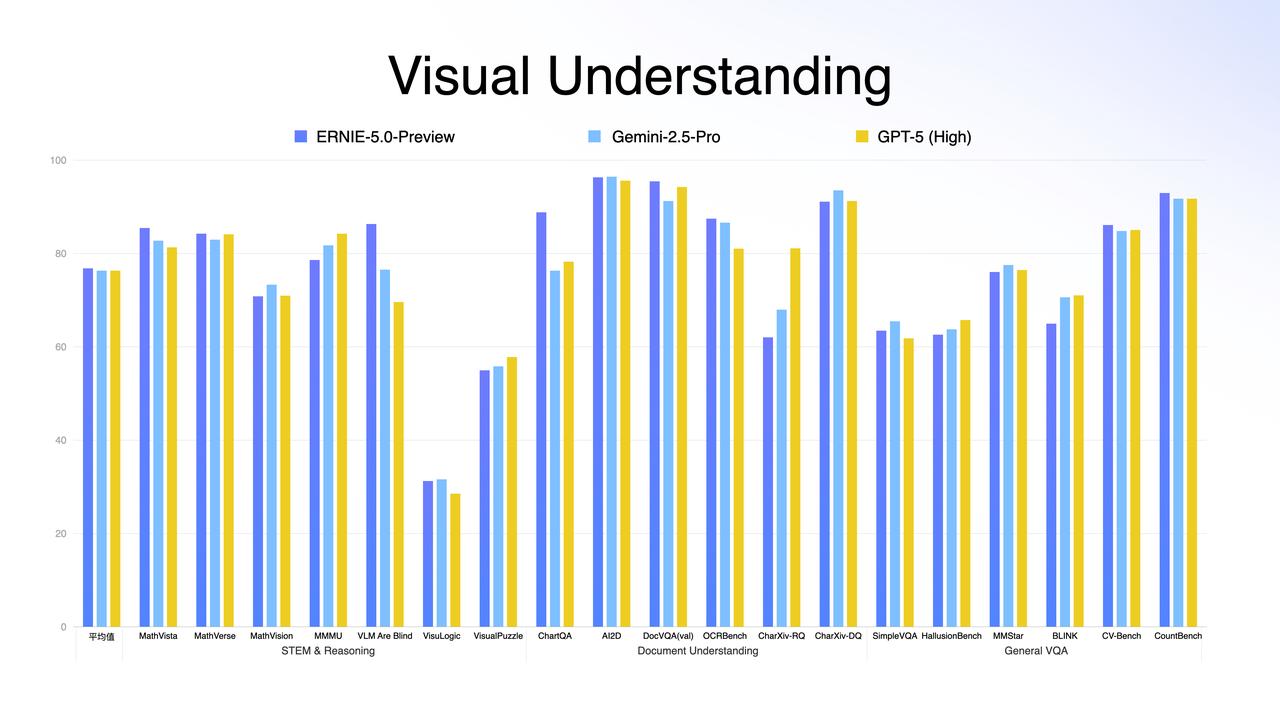
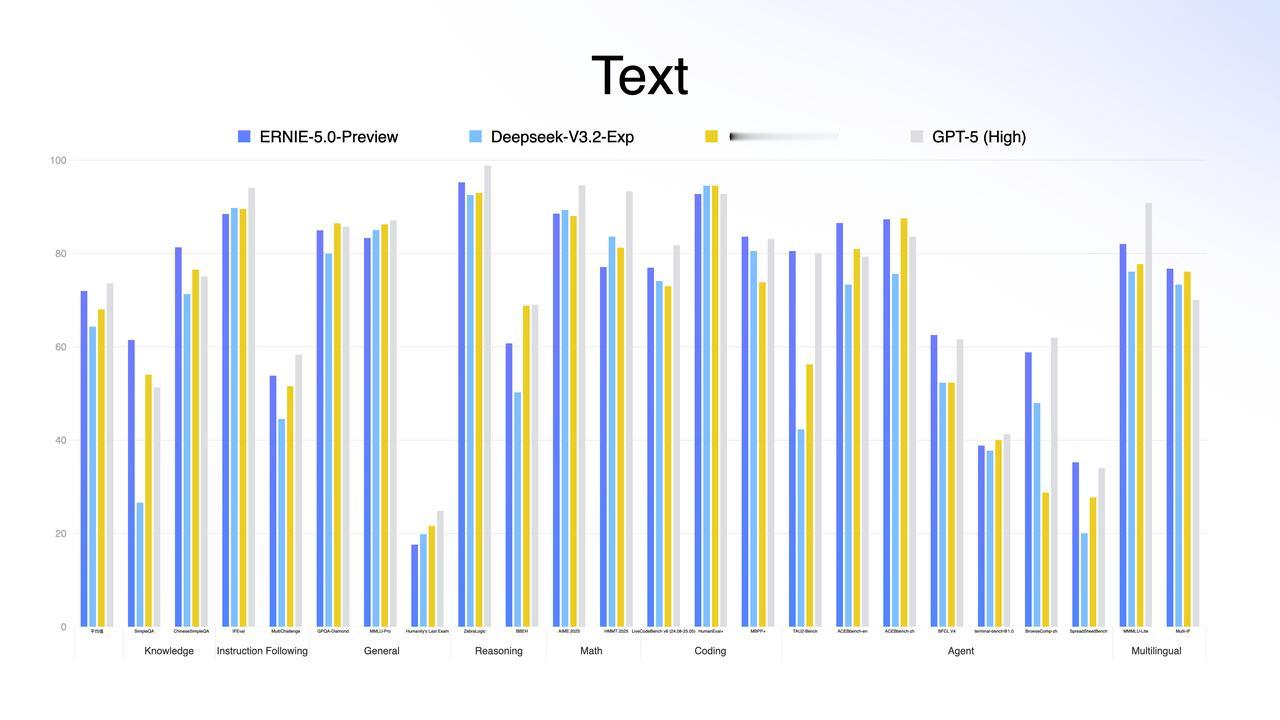
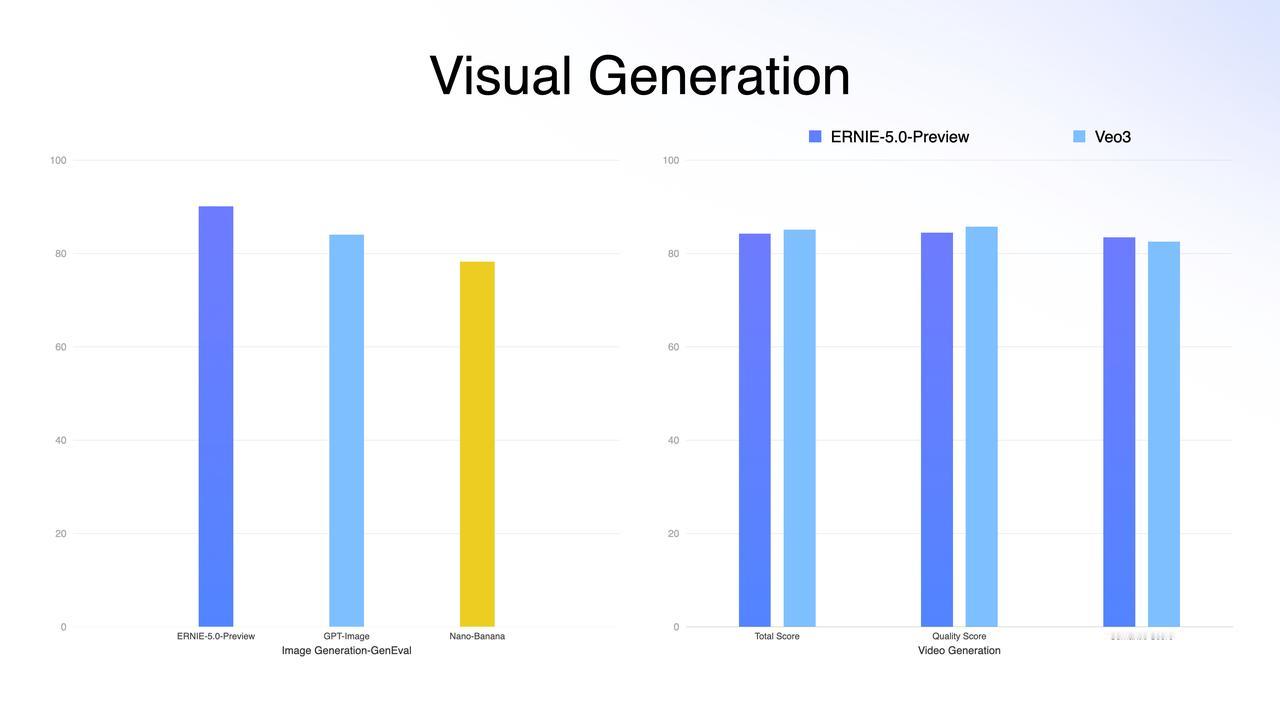
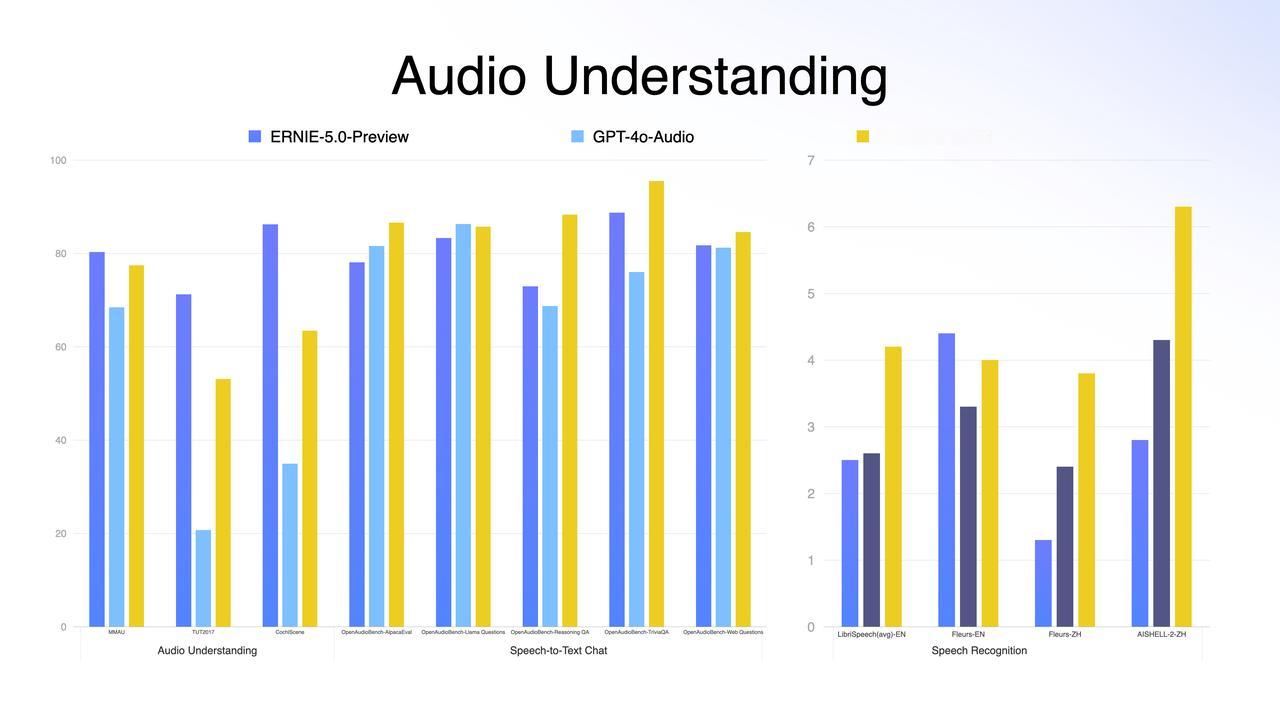
DeepMind说中国AI没创新?这张图就是最好的一记耳光;前两天 DeepMind CEO 那句评价大家听了吗? 中国 AI 毫无创新,只不过是跟进速度可怕。 这话听着是真刺耳。在前两年的叙事里,我们确实习惯了「跟跑」,习惯了看美国模型神仙打架;甚至在很多人的潜意识里,国产模型就是“套壳”和“微调”的代名词。 但偏见这东西,最怕硬数据。在今天,全球最难刷榜、最讲究“盲测”的 LMArena(大模型竞技场)更新了。大家可以直接看图。 在美国模型的重重包围里,百度文心 ERNIE-5.0-Preview-1203杀出来了。 1451分,登顶国内第一;全球排名前 10,超过了 GPT-5.2 和 Claude Sonnet 4.5;最关键的是:它是前 20 名里,唯一的非美国模型。 这意味着,在所谓的「技术铁幕」上,文心硬生生撕开了一道口子。 很多人可能会问:凭什么?凭什么一个 Preview(预览版)能打赢 GPT-5.2? 这事儿我特意去扒了下文心 5.0 的技术文档,发现百度这次真的在练「狠活」。这 1451 分背后,其实是三次技术路线的“换道”: 第一,是“原生”。以前多模态模型,很多是“外挂”个眼睛耳朵,属于后期融合。但文心 5.0 采用的是“原生全模态(Native Omni-modal)” 。 打个比方: 它就像天生具备视听说能力的生命体,从训练的第一天起,文本、图像、音频、视频就是融合在一起学习的 。 它不需要“翻译”,就能直接理解视频里的情绪,直接看懂图片里的逻辑,支持多种信息的联合输入与输出;这种“出厂设置”级别的差异,让它的理解和生成能力直接上了一个台阶。 第二,大块头有大智慧。 文心 5.0 的参数量高达2.4 万亿 。这是什么概念?这是目前业界已公开参数模型里的“巨无霸” 。通常我们认为模型越大越慢,但它用了一种“超大规模混合专家模型(MoE)”架构。 简单说,它拥有 2.4 万亿个专家的脑子,但在处理具体问题时,它具备“超稀疏激活”能力,只激活其中不到 3%的相关专家来干活。 这完美解决了悖论:既有万亿级大模型的智商,又有小模型的推理速度和低成本。 第三,从“快嘴”变“智者”。 这次它还进化出了“长程智能体”能力 ;面对复杂指令,它不再是简单的问答,而是基于“思维链”和“行动链”进行端到端的强化学习 。 它会先思考拆解,再调用工具执行,最后根据结果反馈调整下一步计划;这种解决复杂长程任务的能力,才是打赢 GPT-5.2 的核心杀手锏 。 所以,别再信什么“无创新论”了;别忘了,这还只是个 Preview 版。 听说是 1 月份正式版上线。到时候,这出“突围”大戏,可能才刚刚开始。