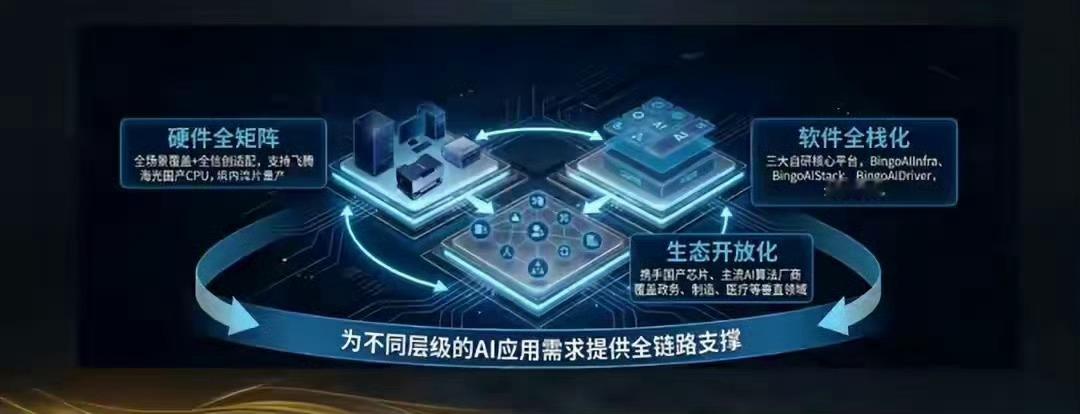
品高股份算力战略再升级:AI Station液冷工作站重磅首发,2026年T800芯片剑指大规模算力市场在国产AI基础设施加速落地的浪潮下,品高股份(688227.SH)官宣算力战略级新品发布计划,于2025年12月25日推出品原AI一体机AI Station液冷AI工作站系列。这款产品以“国产智芯为核心、软硬件生态为基底、长期技术布局为羽翼”,打造从桌面级AI算力终端到集群训练的全栈自主算力解决方案,为国产化算力生态添砖加瓦。一、 今日重磅首发:AI Station液冷工作站,树立国产桌面级算力新标杆作为品原AI软硬件产品矩阵的核心终端,AI Station液冷AI工作站以江原D20 AI加速卡为算力底座,同步推出单卡(AI Station D20-S)、双卡(AI Station D20-D)、四卡(AI Station D20-Q)全矩阵机型,精准覆盖不同层级的算力需求。值得一提的是,江原D20是国内首款实现设计、制造、封装、境内流片量产的云端AI推理卡,供应链全程自主可控。该加速卡搭载256GB显存,INT8算力峰值高达320TOPS,支持FP32/FP16/BF16/INT8多精度混合计算,为大模型稳定运行筑牢硬件根基。在单机性能上,AI Station系列实现关键突破:单卡机型可流畅运行32B参数级大模型;四卡机型依托多芯片协同架构与品高自研4D并行调度策略,单机即可承载Qwen 235B、DeepSeek 685B等千亿级大模型,一举打破桌面级工作站部署超大模型的算力桎梏。一体式液冷散热架构更是这款产品的亮点所在,实现高性能、低噪音、长稳定三重优势:热传导效率较传统风冷提升40%,可有效避免高负载下的算力降频,保障设备7×24小时连续运行;运行噪音低至28dB,堪比图书馆环境音,完美适配办公、实验室等安静场景;液冷系统的小型化集成设计,让四卡机型依旧保持紧凑机身,兼顾算力密度与空间适配性。场景应用层面,AI Station全系列深度支持RAG(检索增强生成)、工作流自动化、智能体部署等前沿AI场景,凭借本地算力部署模式构建起数据私域安全屏障,有效规避核心数据外泄风险,高度契合政企客户的数据合规需求,提供“开箱即用”的国产化AI算力终端方案。二、 全栈布局:构建国产智芯驱动的软硬件生态矩阵本次新品发布并非单一产品的落地,而是品高股份“国产智芯软硬件系列化”战略的集中体现,公司以此构建起“硬件全矩阵+软件全栈化+生态开放化”的完整国产AI算力生态体系,为不同层级的AI应用需求提供全链路支撑。1. 硬件产品矩阵:全场景覆盖+全信创适配品高股份打造了覆盖边端、桌面级、服务器集群的完整品原AI一体机产品线。服务器级涵盖1卡、8卡、16卡等多规格机型(含PYD10-MIN/PRO/MAX等型号);桌面级则是本次发布的AI Station工作站系列,提供1卡、2卡、4卡全配置选择。全系列硬件全面兼容全信创架构,已完成与飞腾、海光等主流国产CPU的深度适配,核心零部件与整机架构100%自主可控,最大限度保障供应链安全,可满足从边缘推理到云端大规模算力调度的全场景需求。2. 软件全栈平台:全流程赋能AI开发运维配套三大自研核心软件平台形成协同合力:BingoAIInfra智算调度平台具备驱动级GPU切割与云原生调度能力,实现国产算力资源的精细化管理与高效利用;BingoAIStack训推一体化平台提供一站式MaaS能力,支持零门槛开展模型训练、部署、测评与开发,赋能多用户多任务并行协同创新;BingoAIDriver智能应用平台聚焦行业应用落地,提供场景化应用组件与集成能力,大幅降低AI应用开发门槛。3. 开放生态合作:携手伙伴共建产业生态品高股份秉持开放共赢理念,已与江原科技等国产芯片厂商达成深度战略合作,同时完成与国内主流AI算法厂商、行业ISV的全面适配,覆盖智慧政务、智能制造、医疗健康、智慧交通等多个垂直领域。通过技术标准共建、解决方案共创等模式,推动国产AI算力生态的规模化落地与迭代升级。4. 权威认可加身:彰显国产算力硬核实力品原AI一体机系列凭借全栈国产化优势与卓越性能,斩获多项行业权威奖项:在第27届中国国际软件博览会上荣获“2025年度人工智能创新产品”称号;其应用项目《面向智慧交通场景的视频与图像智能识别系统》在第一届综合交通运输大模型智能体创新应用大赛全国总决赛中摘得一等奖;品高股份也凭借该系列产品的商业落地成果,成功入选“2025中国AI商业落地基础设施服务商Top20”榜单。三、 2026战略展望:江原T800训推一体芯片登场,锚定大规模算力需求面向未来,品高股份的算力布局剑指更高阶的大规模AI模型训练推理场景——2026年,江原科技将推出T800大模型训推一体AI芯片,对标英伟达H800芯片,以境内流片量产的优势,打造高性价比的国产高端算力选择。这款芯片的核心优势十分突出:采用国产先进工艺与先进封装技术打造,通过深度PPA(功耗、性能、面积)优化,在保障自主可控的同时实现效能跃升;原生支持FP8/FP4高精度计算加速,相较于传统FP16精度可减少50%内存占用,大幅降低内存带宽压力,在保障算法精度的前提下提升训练效率;搭载144GB高速率HBM3E存储,凭借高带宽、低功耗特性有效缓解AI训练的内存瓶颈;配备SmartLink卡间高速互联技术,支持最大256卡超节点集群部署,实现超大规模算力训练推理的高效协同调度。与海外主流高端GPU相比,江原T800的性能优势尽显:相较于H20 GPU,FP8/FP16算力实现翻倍,运算效能大幅提升;全面支持FP4精度,达成四倍推理算力突破;存储容量与显存带宽同步升级,轻松承载超大参数模型。相较于H800 GPU,互联带宽实现翻倍,支持更大规模超节点集群部署;存储容量和显存带宽显著提升,保障高算力场景下的稳定输出。江原T800的性能突破,不仅印证了国产AI芯片的技术进阶,更与本次发布的AI Station形成战略呼应——前者锚定未来大规模算力需求,后者夯实桌面级算力终端市场,二者共同构成品高股份“自主可控、全栈覆盖、长期迭代”的算力战略核心。