阿里千问3登顶全球最强开源模型!
官方详细介绍(中英文版):qwenlm.github.io/blog/qwen3/
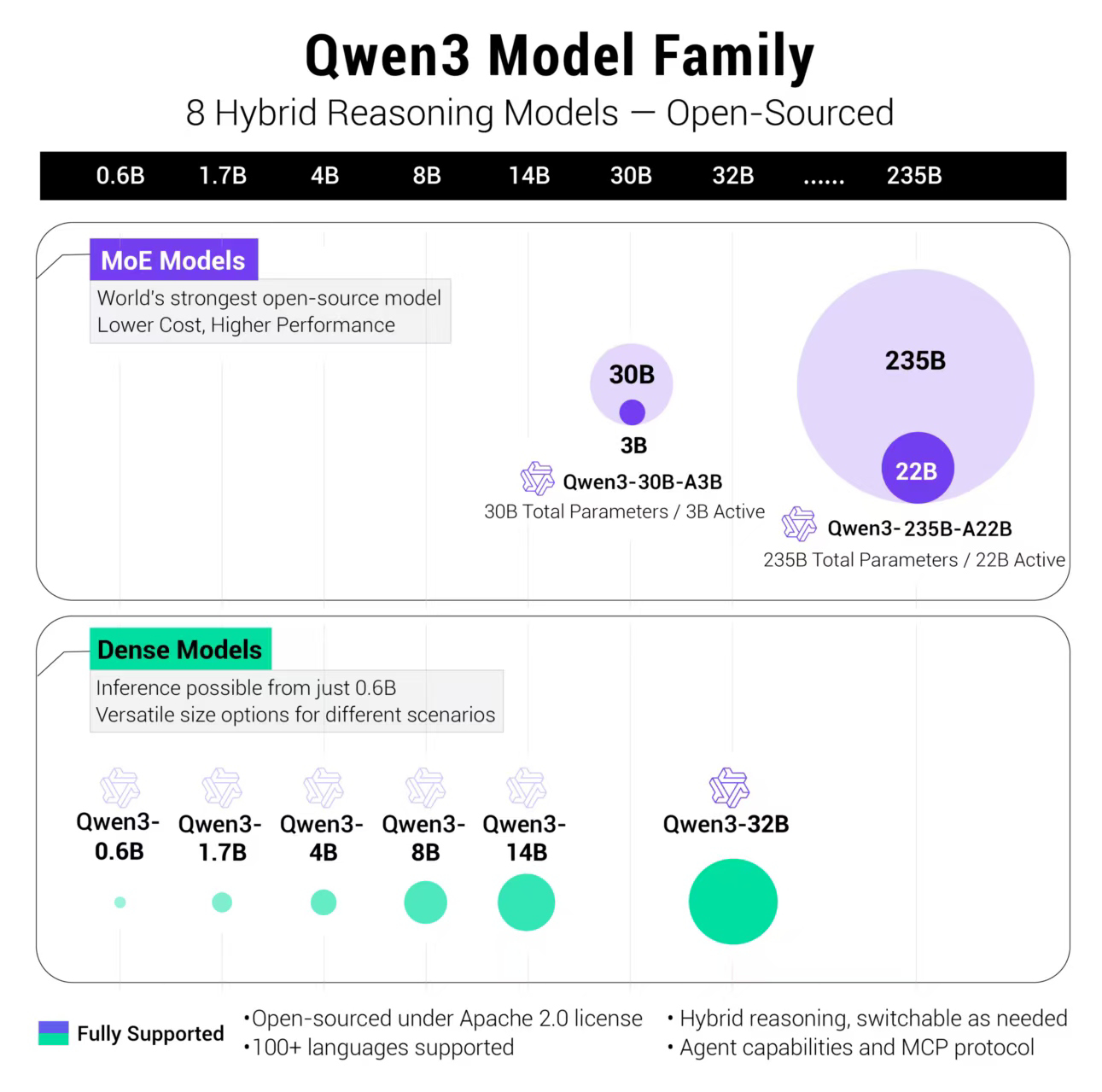
这次发布的模型全部都是在 Apache 2.0 许可下开源的。具体包括两个 MoE 模型的权重:Qwen3-235B-A22B,一个拥有 2350 多亿总参数和 220 多亿激活参数的大模型,以及Qwen3-30B-A3B,一个拥有约 300 亿总参数和 30 亿激活参数的小型 MoE 模型。此外,六个 Dense 模型也已开源,包括 Qwen3-32B、Qwen3-14B、Qwen3-8B、Qwen3-4B、Qwen3-1.7B 和 Qwen3-0.6B,均在 Apache 2.0 许可下开源。
从官方发布的内容看,特点有:
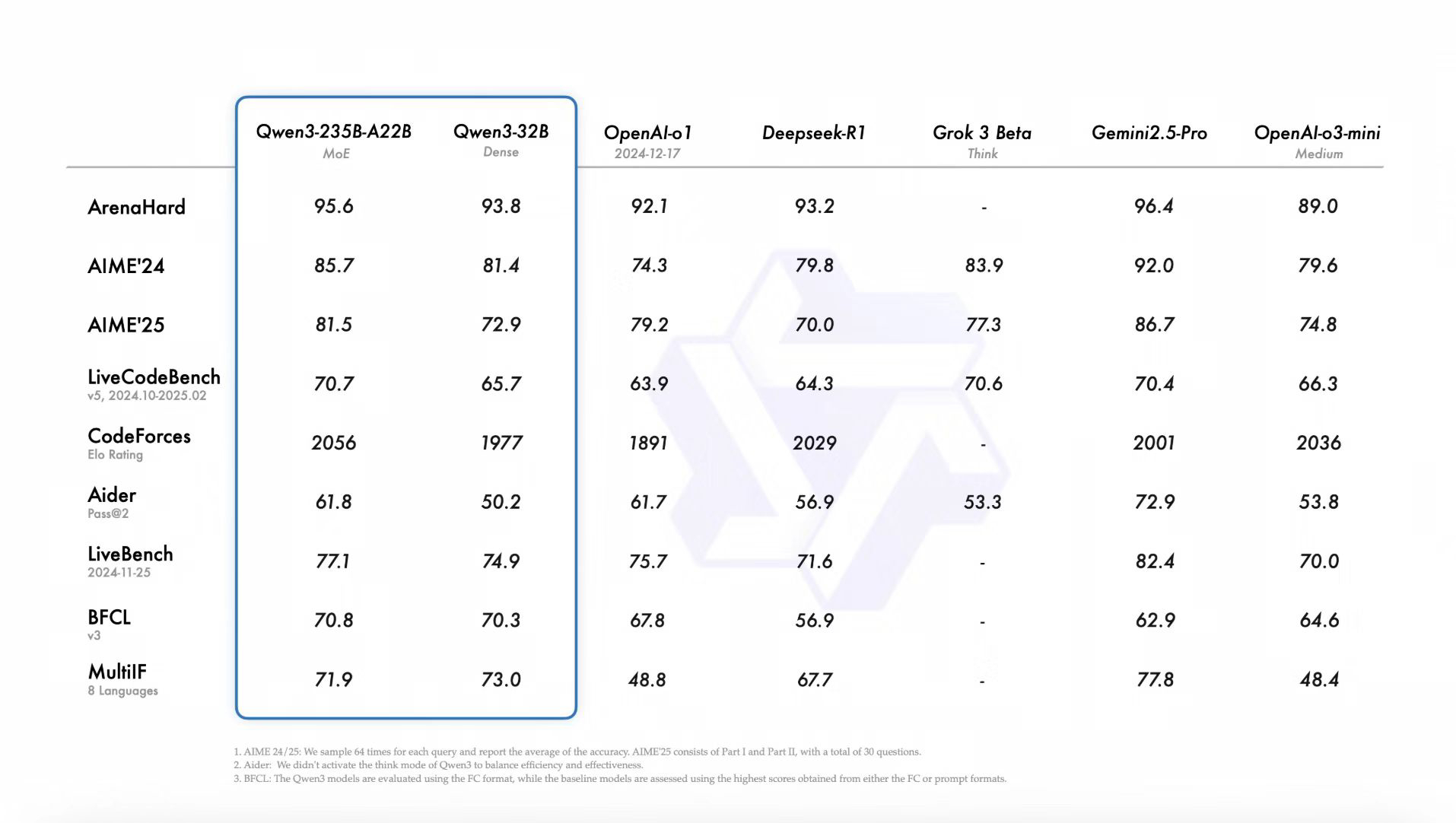
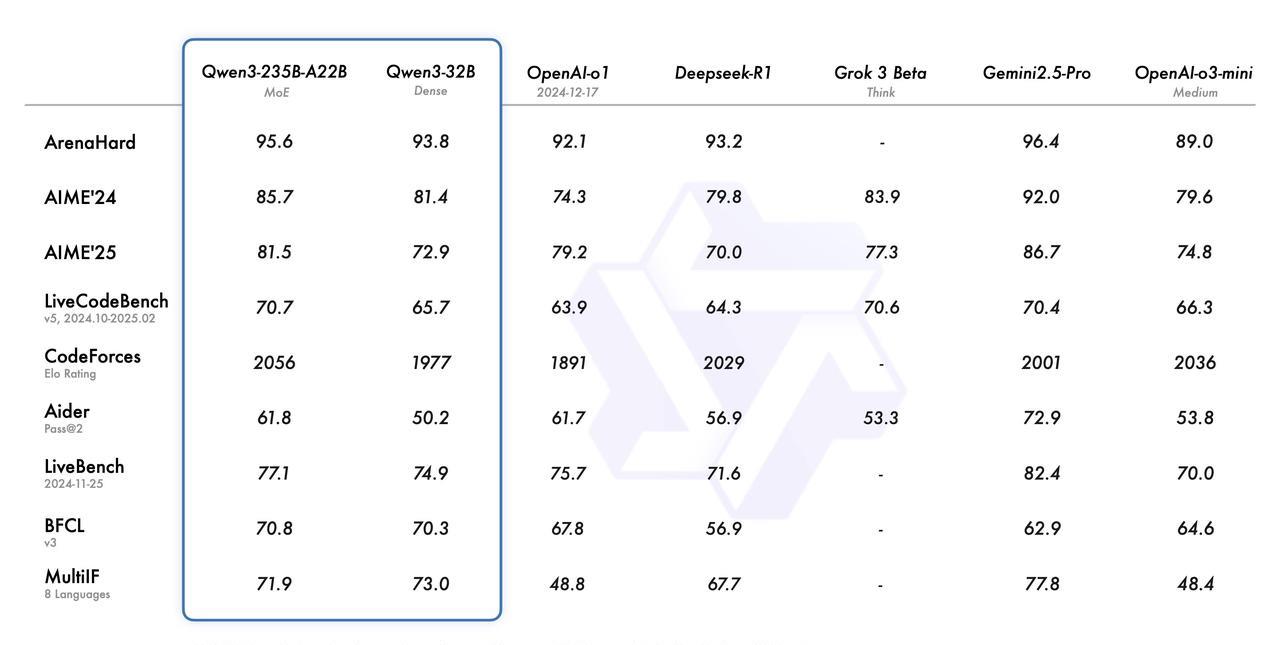
1. 跑分更高了,最前的Qwen3-235B-A22B跑分超过之前的开源模型,部分超过最强的Gemini-2.5-Pro 。
2. 是个类似Claude 3.7 Sonnet那样的融合模型,既能快速响应问题,也能进行深度思考
3. 多语言支持,支持 119 种语言和方言。
4. 支持MCP。
具体能力方面,再等等深度评测。可以直接在chat.qwen.ai上体验,现在速度很快。
这几年Qwen的发展过程,也是一步步把口碑打起来了。特别是在单独部署和科研领域的应用,基本上就是当之无愧的第一。之前发布的Llama4各方面能力都明显不行,开源许可也不友好。DeepSeek虽然能力很强但参数量太大,不适合学术研究和个人和中小企业单独部署使用。单独部署方面,可以看到Qwen系列自2.5以后基本是reddit/localllama频道最热的讨论点。学术研究方面,参考Gabriele Berton的推文“过去几个月里每一篇视觉语言模型/多模态大模型的论文都采用 Qwen 作为 LLM。不是 Gemma,不是 Llama,也不是 DeepSeek。而是 Qwen——每一个”
开源生态方面也搞的很棒。这次发布后mlx-lm、LM Studio、Unsloth Al、SGLang 等都在第一时间表示支持。
之前Meta说,想做“大模型界的Linux”,现在看,是Qwen真的做到了这一点。



评论列表