GoogleDeepMind CEO Demis Hassabis 谈为什么应用于现实世界的强化学习很难做,其奖励函数很难定义:
我认为,在我们人类世界中,我们自己就没有单一的目标函数,这是一个非常复杂和动态的过程。事实上,如果你问任何一个人,他在特定的一天里在优化什么,他都可能给出不同的答案。
我们本质上是多目标的,并且会根据自己的情绪、环境、人生阶段等一系列状态,持续地动态调整各个目标之间的权重。但不知何故,我们的大脑总能应对自如,大致摸索出正确的「北极星」来指引方向。
————
其实,也有很多人的大脑应对不怎么自如,摸索不出北极星,不然怎么那么多人「听过很多大道理,但依然过不好这一生」。[泪奔][泪奔]




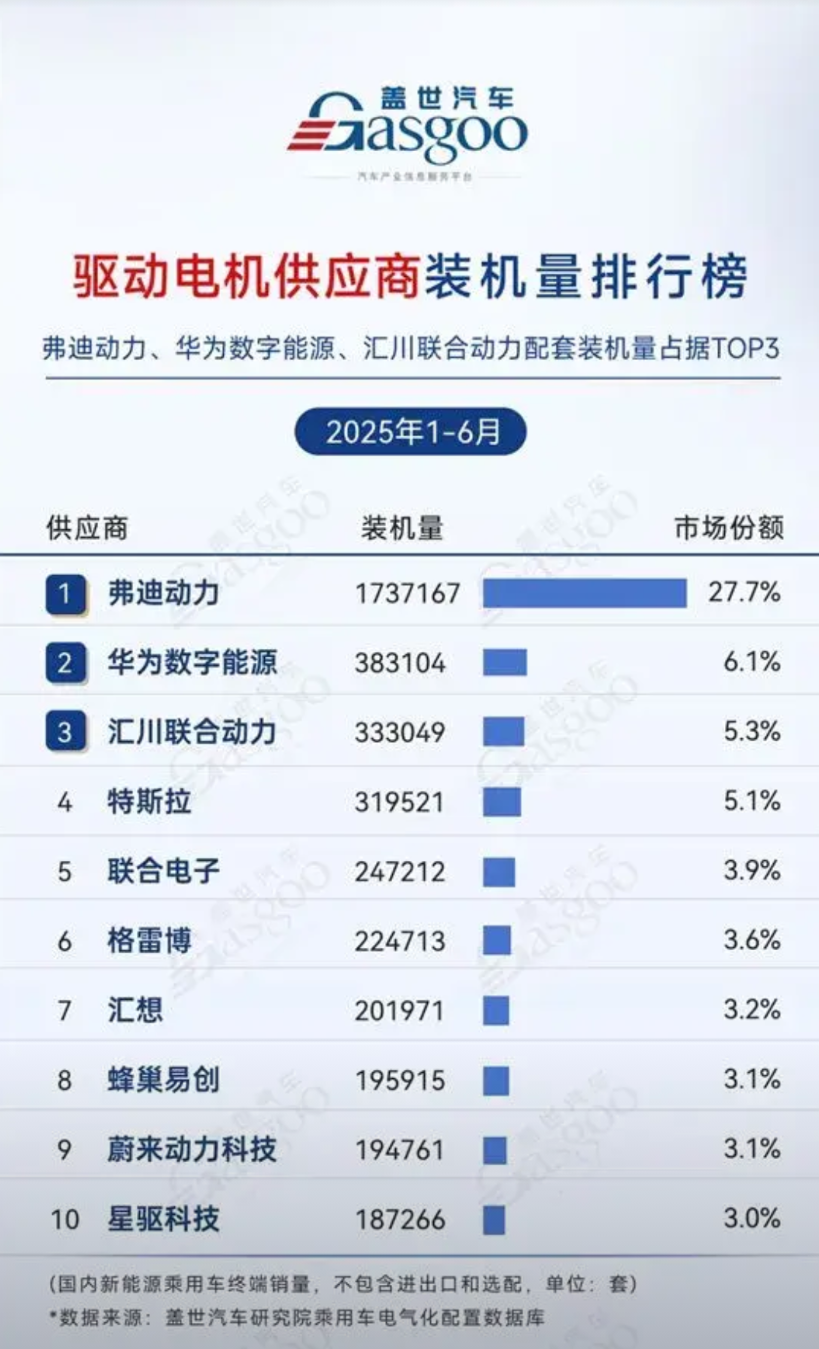
![华为不小心又得了个第一[捂脸哭][捂脸哭][捂脸哭]](http://image.uczzd.cn/13108934159867420374.jpg?id=0)