马斯克转发金融AI新考题字节联手哥大挑战金融分析
让AI像金融分析师一样搜索和分析数据,到底有多难?当前的大模型虽然能回答基础金融知识,在CFA考试中取得高分,但面对真实的金融场景,它们的表现究竟如何?
为了回答这个问题,字节跳动Seed团队联合哥伦比亚大学商学院推出了FinSearchComp,这是首个完全开源的金融搜索与推理基准测试。该基准包含635个金融专家精心设计的问题,覆盖全球和大中华两个市场,并在多个主流模型产品上进行了全面评测。
评测结果令人深思:
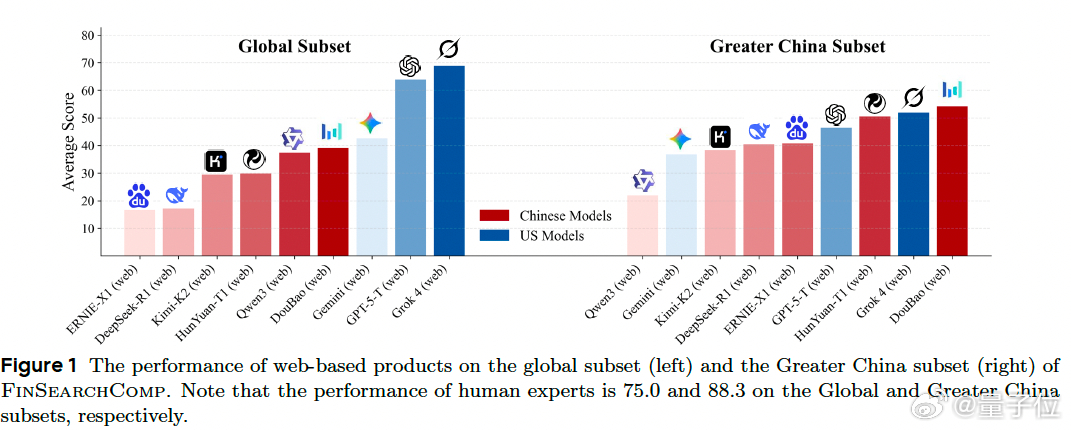
在全球数据集上,表现最好的Grok 4 (web)准确率达到68.9%,但仍落后人类专家6.1个百分点。在大中华区数据集上,豆包(web)虽然领先其他模型,但与人类专家88.3%的准确率相比,差距超过34个百分点。
这些数字清晰地表明,即使是最先进的AI系统,在处理复杂金融分析任务时仍有很大提升空间。【图1】
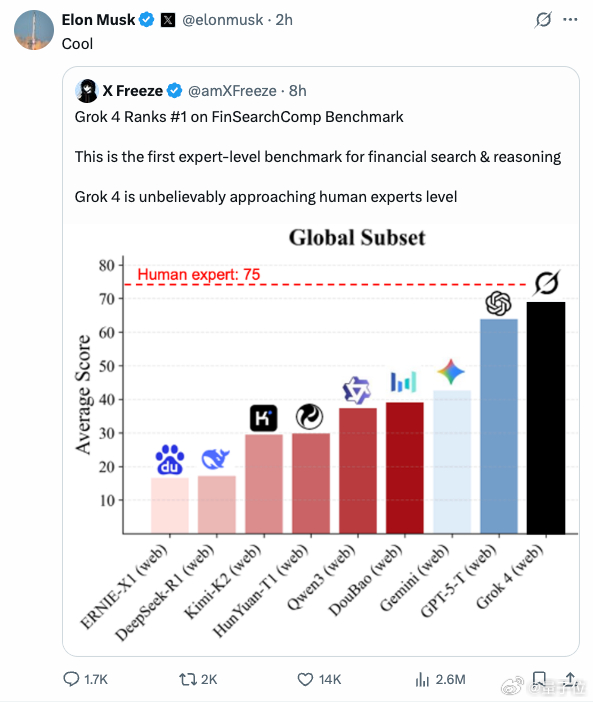
该基准测试发布后获得了业界的广泛讨论,马斯克也关注并转发。【图2】
学界专家们认为,这进一步凸显了金融AI能力评估在当前技术发展阶段的重要性和现实意义。
金融分析是检验AI能力的绝佳试金石。分析师的日常工作涉及大量复杂的信息搜索和整合,从实时市场数据到历史财务披露,从新闻事件到监管文件,这些任务不仅要求时效性和精确性,还需要跨源信息整合和专业判断。
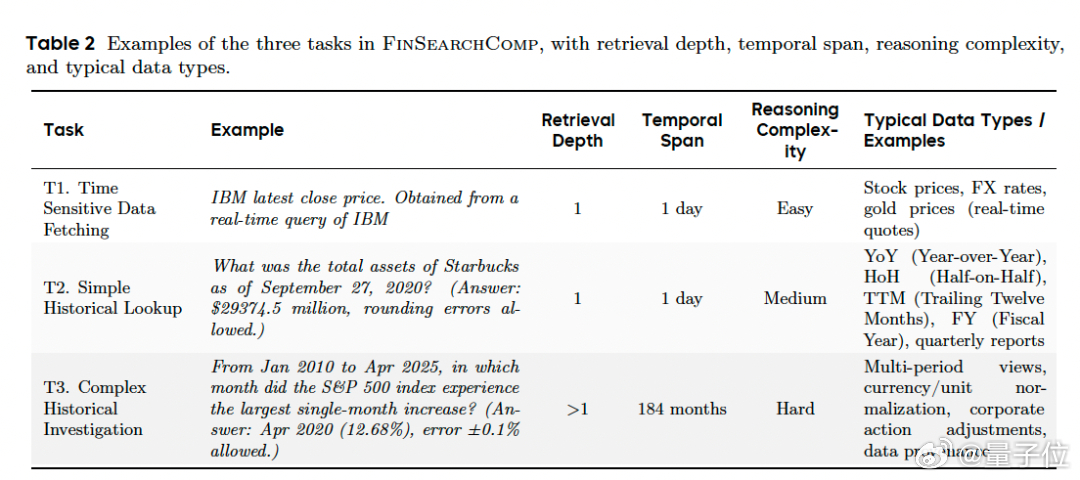
举例来说,看似简单的"查询IBM最新收盘价"需要快速获取并验证最新数据;"检索星巴克2020年9月的总资产"需要准确定位时间点并理解会计准则;而"识别2010年以来标普500单月最大涨幅"则需要跨越多个时期进行数据处理。
这些任务展现了金融搜索如何结合时效性、精确性和证据整合,使其成为评估AI是否能支持现实高风险决策的天然试验场。一个过时的数据、一个口径错误的数据、 一个非官方信息源的数据,都可能导致最终的决策失误。而完成这些,有依赖模型对搜索以及金融工具的使用。
FinSearchComp的研究团队精心设计了三类贴近分析师日常工作的任务,难度逐级递增。
时效性数据获取任务要求获取每日或日内变化的数据,如最新股价、汇率、黄金价格等,这类任务强调数据时效性搜索、多信息源判断。
简单历史查询任务需要查找固定时间点的事实,比如某公司2024财年的研发支出或TTM收入,关键挑战在于对齐报告惯例(财年、TTM、季度等单位),并确保单位和货币的一致性。
最具挑战性的是复杂历史调查任务,它要求进行多期聚合或综合分析。例如"过去10年标普500单月最大跌幅是哪个月"这样的问题,需要跨越长时间跨度检索数据、调整公司行为影响、标准化单位,并进行多步推理而不出错。
这种递进式的任务设计不仅反映了金融分析工作流程的实际复杂性,也为细粒度的错误分析提供了可能。【图3】
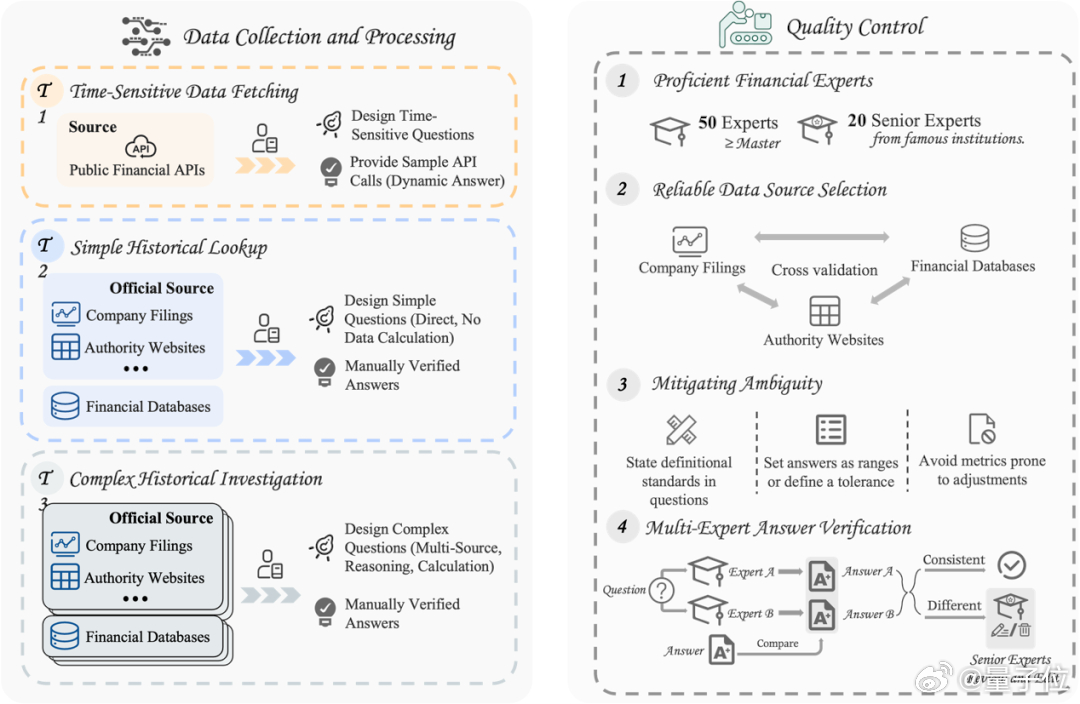
为确保基准的质量和可靠性,FinSearchComp的构建得到了字节跳动Xpert平台的有力支撑。
Xpert是字节跳动旗下的专家级数据服务平台,致力于将各行各业专家的深度知识和丰富经验转化为高质量AI训练数据。该平台汇聚了数千名经过严格筛选的专家,包括来自985/211院校的硕博士学者以及拥有2-10年丰富实战经验的各行业专家。在FinSearchComp项目中,Xpert平台提供了70位金融专家的专业支持,包括50位标注专家和20位资深审核专家。这些专家均具有金融硕士以上学位,来自花旗、摩根大通、德意志银行、野村证券、中信证券、华泰证券等知名机构。
在数据源选择上,所有答案均来自高度可靠的渠道,包括上市公司官方披露、政府和监管机构网站以及专业金融数据库。团队采用多源交叉验证方法确保数据可靠性并消除歧义。例如,他们会将两个不同官方网站的数据进行交叉引用,或将专业金融数据库的数据与官方网站进行验证。
为了消除歧义,团队在问题中明确说明定义标准(如静态市盈率vs市盈率TTM),将答案设置为数值范围或定义容差精度,并尽可能避免容易产生追溯调整的指标。每个问题和答案都经过盲审机制的多重验证,由其他专家独立求解并比对结果。整个数据集构建过程耗时约240小时专家工时,充分保证了专业性和准确性。【图4】
评测发现:搜索能力是关键,金融插件有帮助,但还远远不够。
首先是任务难度的递进性得到验证,所有模型的表现都从T1到T3单调递减,证明基准确实在测试越来越复杂的搜索和推理能力。T3任务需要跨异构源和时间段的多跳检索、时间推理、细粒度实体解析以及部分或冲突证据的协调,迫使系统进行规划、验证和综合,而不仅仅是检索。
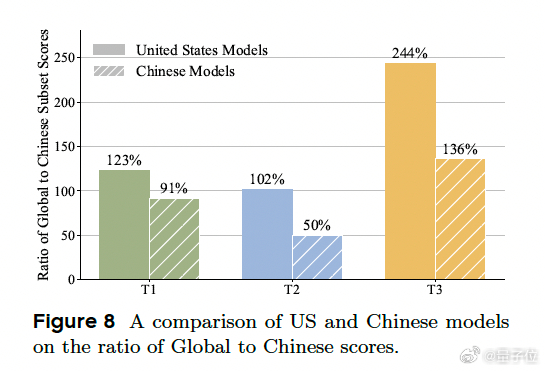
地域特征也很明显。美国模型在全球数据集上领先,中国模型在大中华区数据集上表现更好。研究团队认为这主要归因于模型能力、以及产品所用工具的地区性,这些因素共同提升了"主场"性能。【图5】
最引人注目的是搜索能力的关键作用。
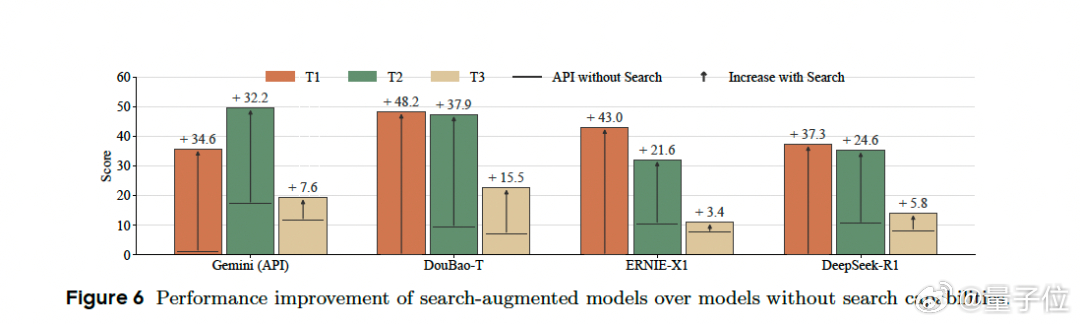
配备网络搜索功能的模型在三个任务上分别获得40.8、29.0和8.1个百分点的巨大提升。没有搜索功能的模型在时效性任务上一律得分为0,因为它们无法检索当前金融数据。即使在T2和T3任务上,无搜索模型虽然能获得非零但很低的分数,这主要依赖于预训练时的参数记忆,但这些记忆往往过时或不准确。
此外,金融插件的价值也得到充分体现。在元宝平台上使用金融插件的DeepSeek R1比在DeepSeek官方网站上的版本表现提升了31.9个百分点。标准网络搜索功能可能产生过时的金融数据或无法检索最新信息,而专用金融插件提供对简单实时数据的直接访问,使模型能够生成更准确的摘要并减少错误的可能性。【图6】
这个基准不仅测试了AI的搜索能力,更重要的是揭示了构建可靠金融决策支持系统所需的关键能力差距。
据统计,美国约有37万金融专业人士,全球可能超过100万金融分析师每天都在执行这些信息检索任务。个人分析师每天执行10-30次简单历史查询,每次平均需要5-10分钟;而复杂历史调查虽然频率较低,但每次往往需要15-60分钟。
虽然标准化模板和自动化工具已经存在,但约有一半的信息检索活动仍然需要手动数据收集和重写模版开发。如果AI能够准确成这些任务,分析师可以进一步自动化这些流程,显著提升整体生产力。
这次评测也点明了一个现实:最强的AI在金融搜索上也只能及格。或许我们需要的不只是一个FinSearchComp,而是多个这样的行业级评测,构建起金融AI的完整"驾照考试体系",让更多的金融AI产品来参与并证明自己的可靠性。毕竟,在AI能够精准完成这些任务之前,谁敢让它从copilot变成pilot?
Arxiv链接:
Github链接:
Xpert专家平台榜单链接: