RAG学习最全资料RAG入门到进阶
RAG学习最全资料:构建RAG系统所需资料都在这了。(地址在文末)
这是一个围绕RAG的全流程教程合集,从环境搭建开始,一直到高级技术如多查询、路由控制、上下文长文召回、ColBERT索引通通都有,且每部分都有对应notebook代码。
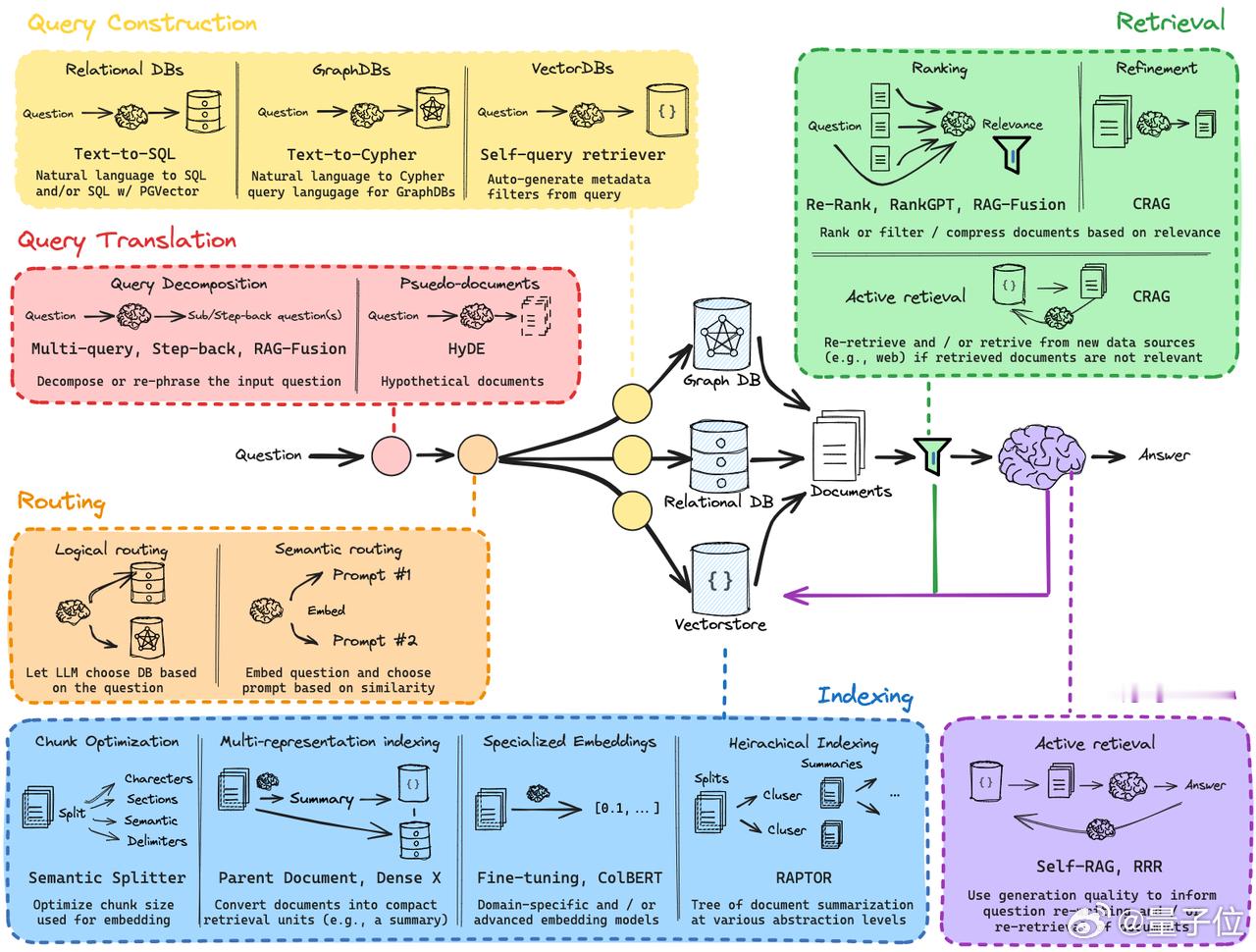
架构图可视化了一整个RAG信息流,有基础也值得一看👇(图2)
具体可以拆成6个模块,每个模块解决的就是在搭建真实RAG应用时会遇到的问题:
1. 查询构造(Query Construction) 自然语言怎么转成机器能理解的查询: - Text-to-SQL:适合结构化数据库场景 - Text-to-Cypher:用于图数据库的查询转换 - Self-query retriever:使用LLM自动生成元数据过滤词,用于增强向量检索
2. 查询翻译(Query Translation) 好的问题不一定好检索,如何“改写问题”对模型更友好: - Multi-query:多个版本问题同时检索 - RAG-Fusion:多路径召回后进行排名融合 - Hypothetical Documents(HyDE):构造伪文档启发搜索方向
3. 路由(Routing) 查询来了之后怎么选数据源、选最合适的query位置: - 逻辑路由:比如判断代码相关的问题进入编程数据库 - 语义路由:相似度驱动的选择机制,可自适应不同领域
4. 文档检索(Retrieval) 拿到query后,怎么快速、精准地检索: - Re-Rank、RankGPT、CRAG:结果排序与压缩技术 - 主动检索(Active Retrieval):如果检索不准,用LLM判断是否需要补拉新数据(如网络实时搜索)
5. 索引构建(Indexing) 向量库好不好用,取决于怎么切文档、用什么嵌入方法: - 多表示法(Multi-representation):比如用摘要+原文双路嵌入 - 层级索引:用RAPTOR实现多层摘要结构 - ColBERT:token级索引方法,保留上下文精度
6. 答案生成(Generation) Content拿到了,怎么组织答案更优? - Self-RAG:让生成过程反过来控制检索 - RRR:Rewriting + Retrieval + Reasoning,支持在生成过程中再判断要不要改写问题或二次检索
整套代码基于LangChain封装,无需基础也能跑起来。也可以灵活替换API,比如换成自己的embedding模型或者上下文存储向量库(支持ChromaDB/Pinecone等)。
项目地址:github.com/bRAGAI/bRAG-langchain/