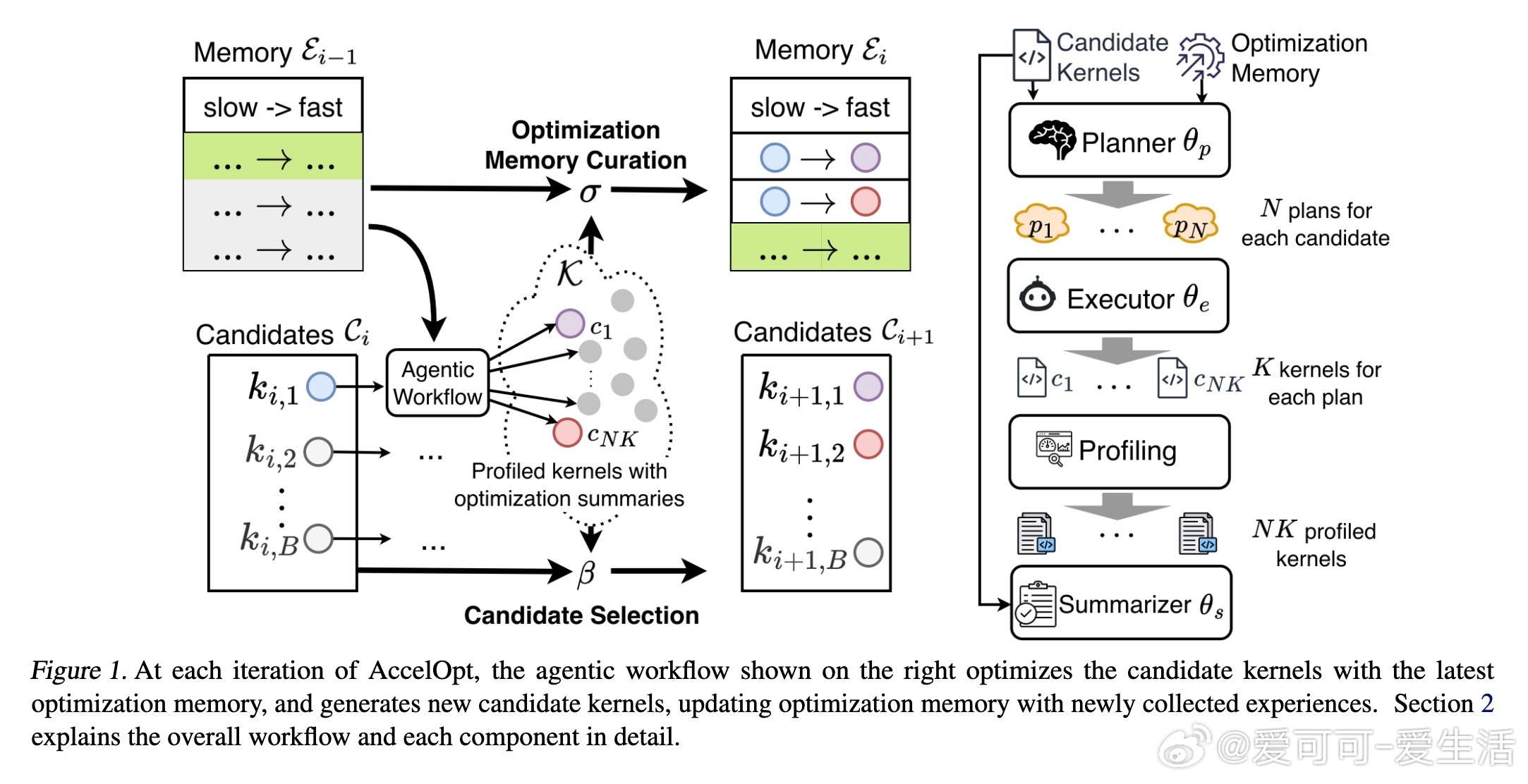
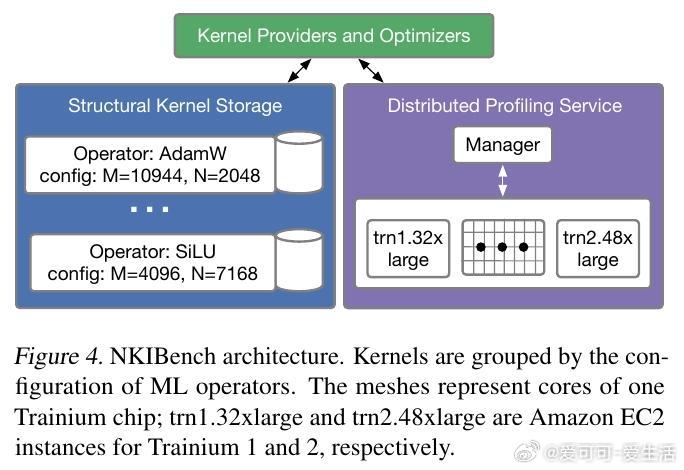
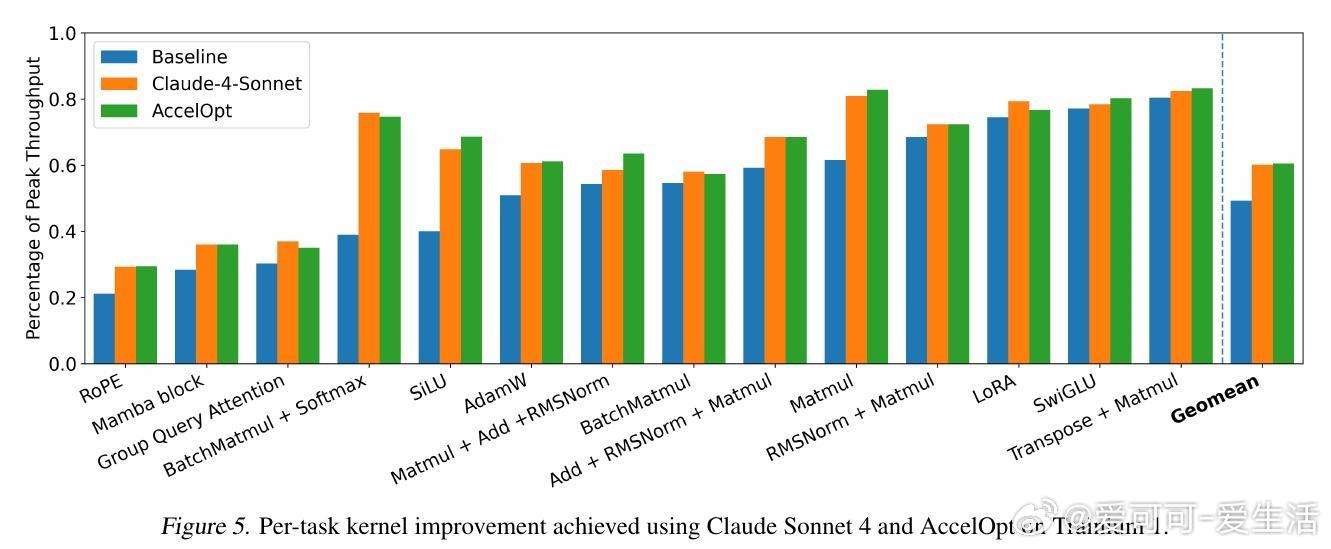
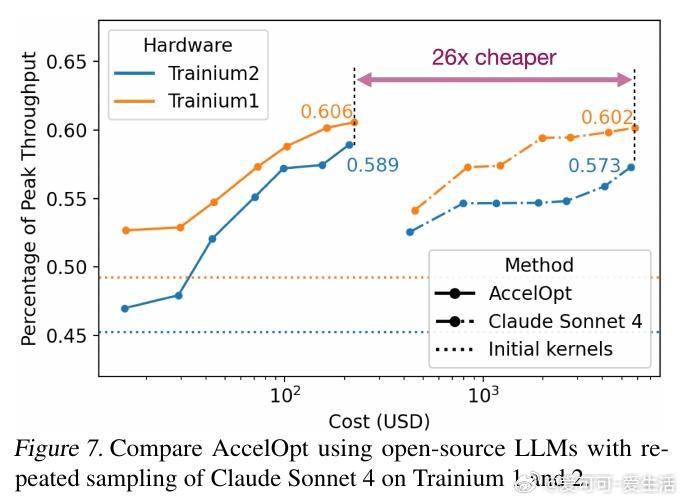
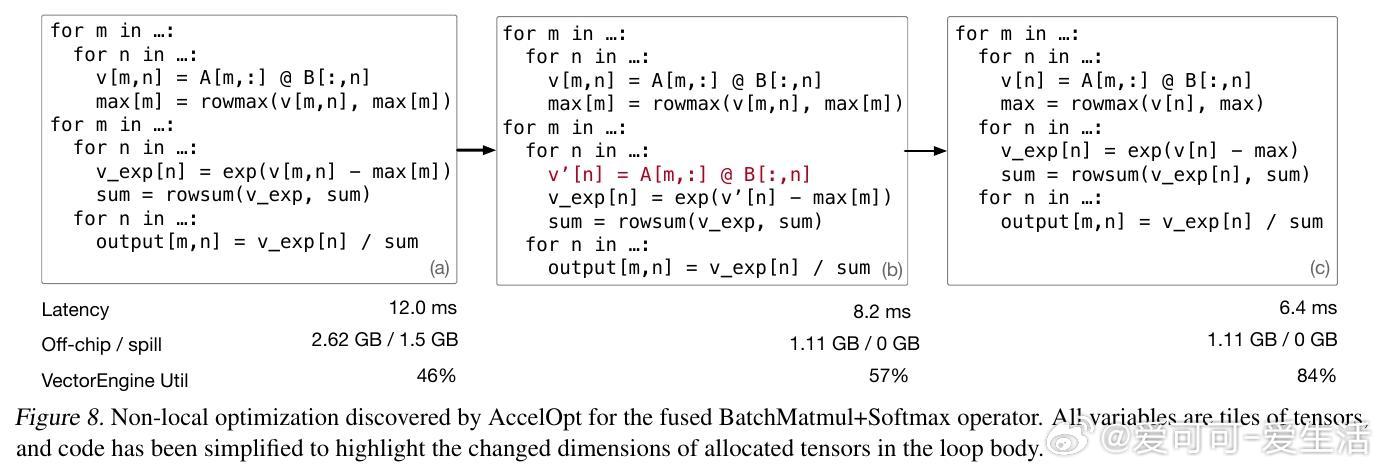
[LG]《AccelOpt: A Self-Improving LLM Agentic System for AI Accelerator Kernel Optimization》G Zhang, S Zhu, A Wei, Z Song... [Stanford University & Amazon Web Services] (2025) AccelOpt:开拓AI加速器内核优化的自我进化大语言模型系统在大模型时代,AI加速器性能瓶颈愈发依赖于内核效率。优化这些底层内核代码极其复杂,尤其是新兴加速器如AWS Trainium,缺乏成熟的硬件知识和优化经验。针对这一挑战,AccelOpt提出了一种全新的自动化解决方案:1. 自我进化设计:AccelOpt构建在大语言模型(LLM)之上,结合beam search搜索策略和“优化记忆”,通过反复生成、评估和总结,逐步积累优化经验,无需专家先验知识。2. 代理工作流:系统包括规划者、执行者和总结者三个智能代理,模拟人类专家的优化思路——先分析性能瓶颈,制定优化方案,修改内核代码,性能验证后提炼总结优化策略。3. 优化记忆机制:保存历史成功与失败的优化案例(慢内核与快内核对比),为未来迭代提供经验启发,提升搜索效率和结果质量。4. NKIBench基准套件:专为Trainium设计,涵盖14个来自真实LLM工作负载的内核任务,且引入理论峰值性能指标,帮助评估优化结果在硬件潜力中的位置,而非仅对比基线速度。5. 优异表现与成本优势:在Trainium 1上,AccelOpt将平均峰值利用率从49%提升至61%;Trainium 2从45%提升至59%,表现媲美Claude Sonnet 4专业模型,同时成本降低约26倍。开源模型配合优化记忆展现良好的性价比。6. 关键技术验证:实验证明beam search比简单重复采样更有效,优化记忆提升了成本效率,且AccelOpt能自动发现从局部代数简化到多层循环变换的复杂优化。7. 限制与未来方向:部分任务性能达峰值后优化趋于饱和,部分因内核复杂度高或DSL表达限制,展现了自动优化的边界;未来可聚焦更强执行者模型和更丰富的优化空间表达。AccelOpt的出现标志着AI加速器内核优化迈入自动化、自我进化的新阶段。它不仅为新硬件平台提供了强大工具,也为教育和研究带来启发,促进了高性能计算与机器学习的深度融合。详见论文:arxiv.org/abs/2511.15915