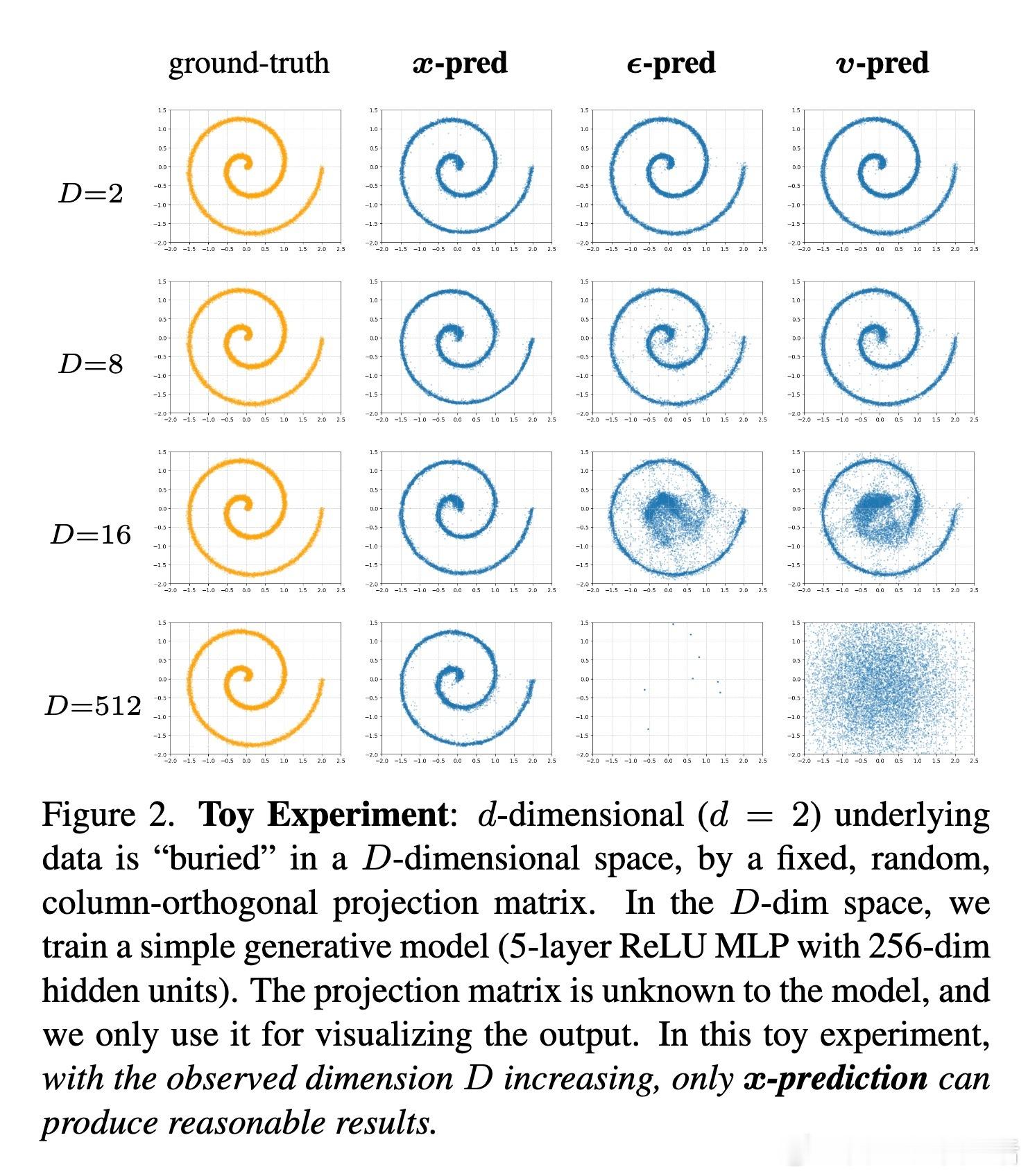
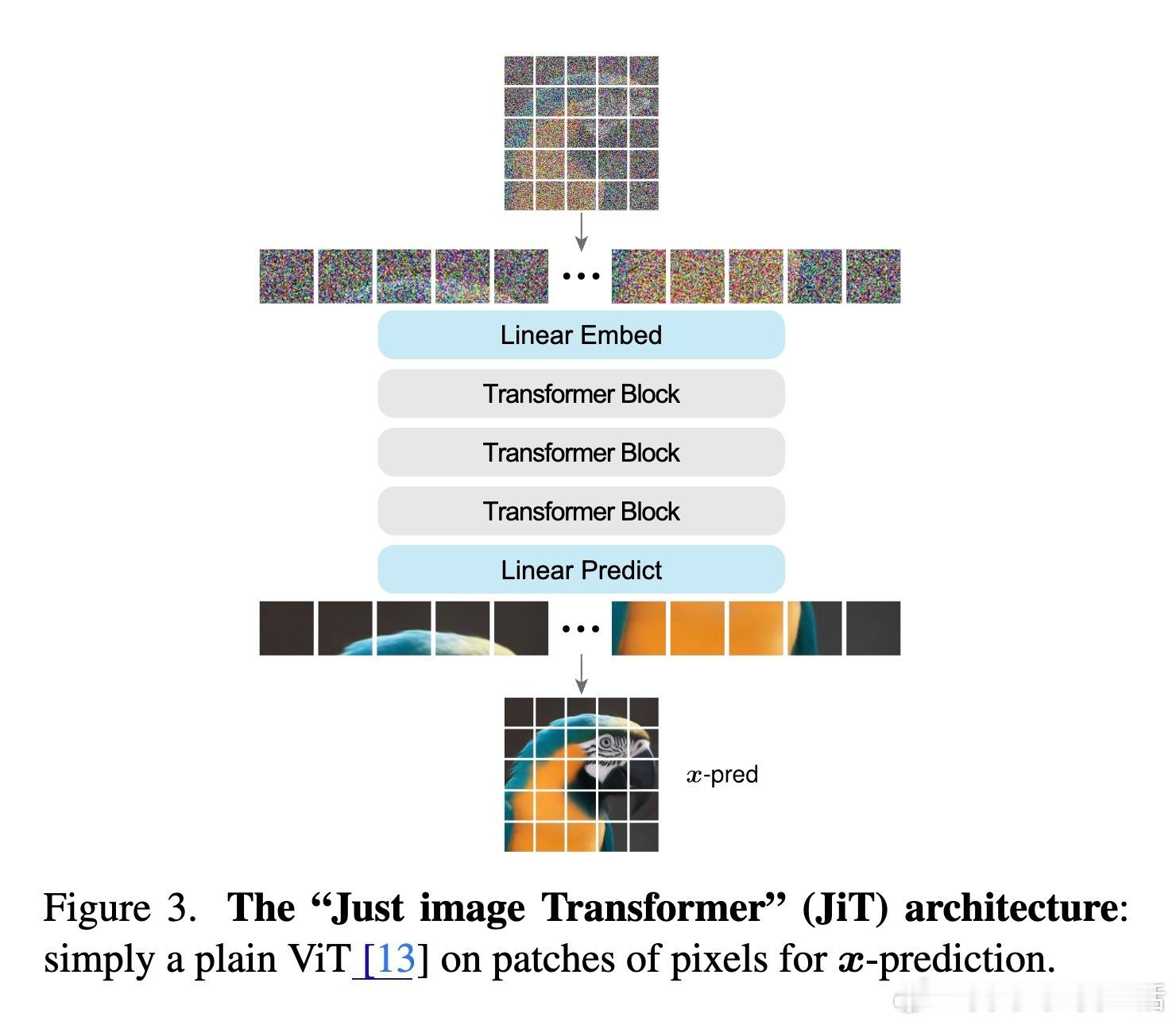
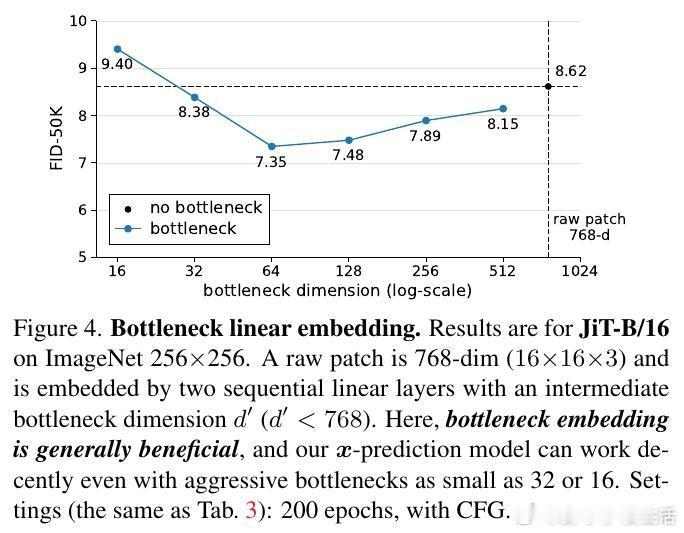
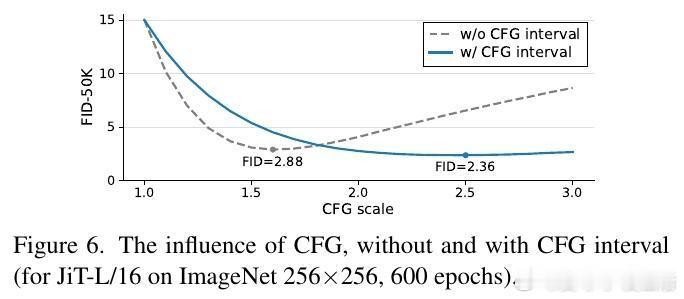
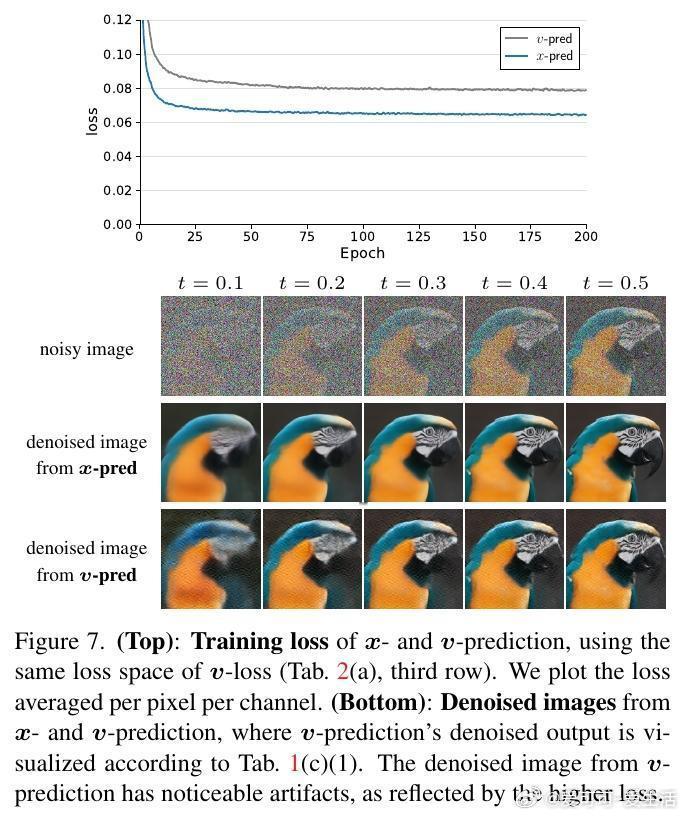
[CV]《Back to Basics: Let Denoising Generative Models Denoise》T Li, K He [MIT] (2025) 回归本质:让去噪生成模型真正去噪近年来,扩散模型广泛流行,但主流方法不再直接预测干净图像,而是预测噪声或带噪信号。本文提出,预测干净数据与预测噪声本质不同。基于“数据位于低维流形”假设,直接预测干净图像更符合自然数据结构,有助于网络在高维空间中高效工作。他们设计了“Just image Transformers”(简称JiT),即直接在像素大块上用纯粹的Vision Transformer(无预训练、无额外损失)进行扩散模型训练。实验证明,JiT在ImageNet 256×256、512×512分辨率下表现优异,预测噪声的传统方法在高维像素空间会出现灾难性失败。关键发现包括:- 预测干净图像(x-prediction)是高维扩散建模的关键,噪声预测(ε-prediction)和速度预测(v-prediction)在高维空间表现不佳。- 通过引入瓶颈层降低维度,不仅不会损失性能,反而能提升生成质量,呼应经典流形学习中的低维表示思想。- 采用logit-normal噪声采样策略,调节噪声水平可以优化训练,但不能解决噪声预测本身的能力不足问题。- 纯Vision Transformer架构,无需特殊预训练或复杂模块,模型容量与输入维度解耦,展现出良好可扩展性。这项工作强调神经网络能力有限,应聚焦于更易学习的“干净数据”空间,有助扩散模型摆脱对预训练潜变量空间的依赖,实现真正自洽的“Diffusion+Transformer”范式。此简洁有效的设计对科学领域处理高维自然数据(如蛋白质结构、分子、气象数据)具有重要启示,减少领域特定设计的需求,推动通用生成模型发展。论文:arxiv.org/abs/2511.13720这篇论文提醒我们:在高维复杂数据的生成任务中,回归本质、尊重数据结构,往往能带来意想不到的突破。让去噪模型回归“去噪”本身,也许是开启更强大生成能力的钥匙。