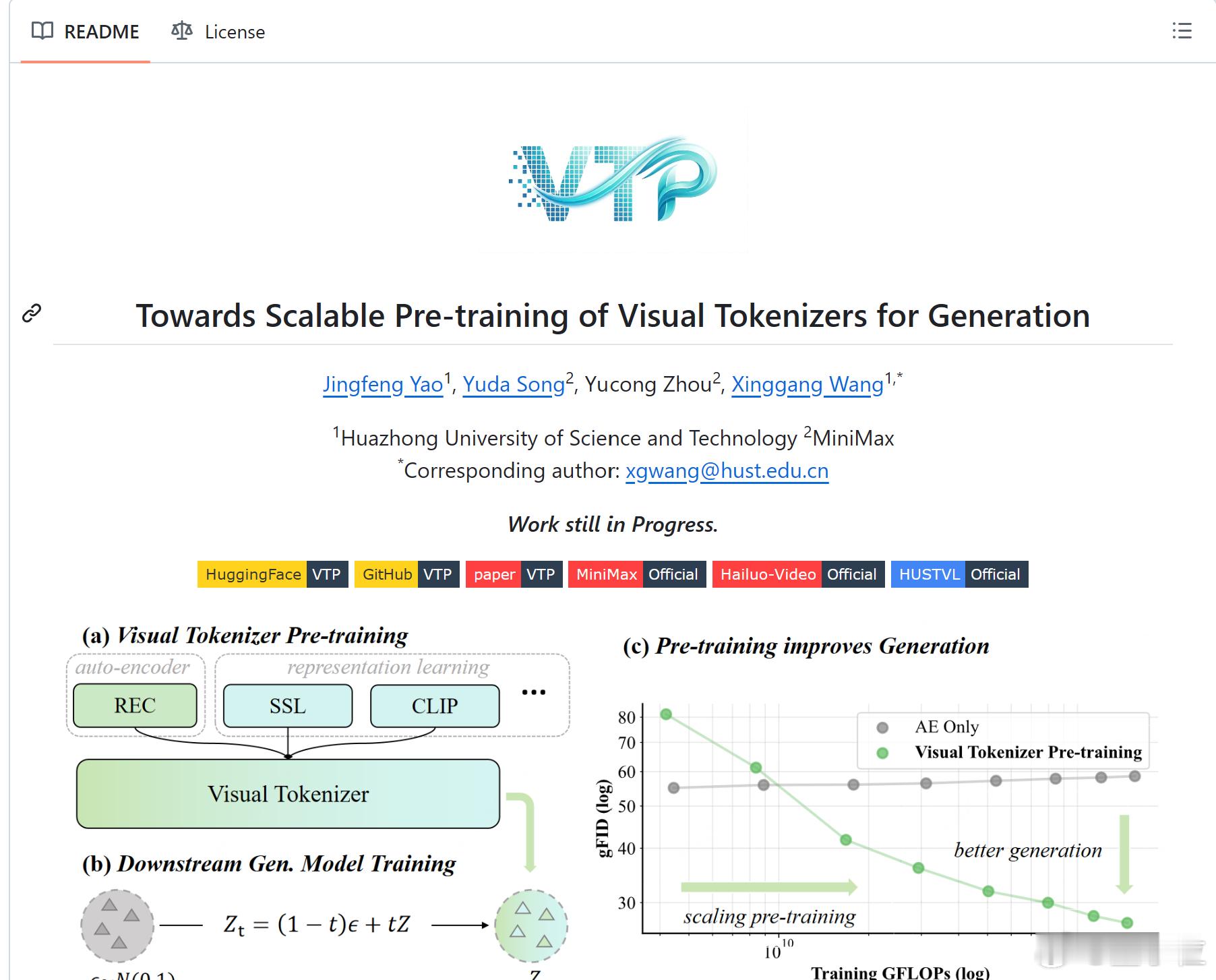
MiniMax海螺视频团队首次开源 带来一款开箱即用的视觉分词器预训练框架VTPMiniMax海螺视频团队不藏了!首次开源就揭晓了一个困扰行业已久的问题的答案——为什么往第一阶段的视觉分词器里砸再多算力,也无法提升第二阶段的生成效果?翻译成大白话就是,虽然图像/视频生成模型的参数越做越大、算力越堆越猛,但用户实际体验下来总有一种微妙的感受——这些庞大的投入与产出似乎不成正比,模型离完全真正可用总是差一段距离。So why?问题,大概率就出在视觉分词器(Tokenizer)这个东西身上了。当算力不再是答案时,真正需要被重新审视的,其实是生成模型的“起点”。在当前主流的两阶段生成框架中(分词器+生成模型),业界已经在视觉分词器的预训练上投入了大量算力与数据,但一个尴尬的事实是:这些成本,几乎没有线性地转化为生成质量的提升。而MiniMax海螺视频团队,不止挑战了这一现实——用实验证明“Tokenizer的scaling能够提升模型性能”。更关键的是,还带来了一款开箱即用、专为“下一代生成模型”打造的可扩展视觉分词器预训练框架——Visual Tokenizer Pre-training(以下简称VTP)。只需换上这个视觉分词器,即可在不改变下游主模型(如DiT)任何训练配置的情况下,实现端到端生成性能的倍数级提升。网页链接代码:网页链接论文:网页链接模型:网页链接